



이 글은 Kousik Nath의 System Design: Design a Geo-Spatial index for real-time location search을 번역한 글로, 모든 저작권은 원저작자에 있습니다. 최대한 원문을 살리려 했으나, 이해를 돕기 위해 의역과 역주를 사용한 곳도 있습니다. 수정할 부분이 있다면 indigoguru@gmail.com으로 남겨주시길 바랍니다.
이번 시간은 아키텍처 전략: 실시간 위치 검색을 위한 지리 공간 인덱스 설계 시리즈 마지막 시간으로 Geo Hash를 이용하여 아키텍처 개선하기에 대해 다루었습니다.
- 개요 및 아키텍처
- 샤딩으로 아키텍처 개선하기
- Geo Hash를 이용하여 아키텍처 개선하기
소개
우리는 실생활에서 항상 실시간 위치 검색 서비스를 사용합니다. 음식 주문 앱이나 주문형 택시 예약 서비스는 요즘 어디서나 볼 수 있죠. 이 글의 목적은 실생활에서 지리 공간 인덱스(Geo-spatial Index)에 대한 백엔드 인프라를 설계하는 방법을 살펴보는 것입니다.

지난 1편 글에서는 로드발랜서와 캐시를 이용하여 부하를 배분 및 감소하는 전통적인 아키텍처를 설명했습니다.
하지만 위 아키텍처는 여전히 IO를 처리하는데 한계가 있어, 도시 ID 기반의 저장소를 분리하는 샤딩이라는 전략을 도입하는 개선된 아키텍처를 2편에서 다루었습니다.
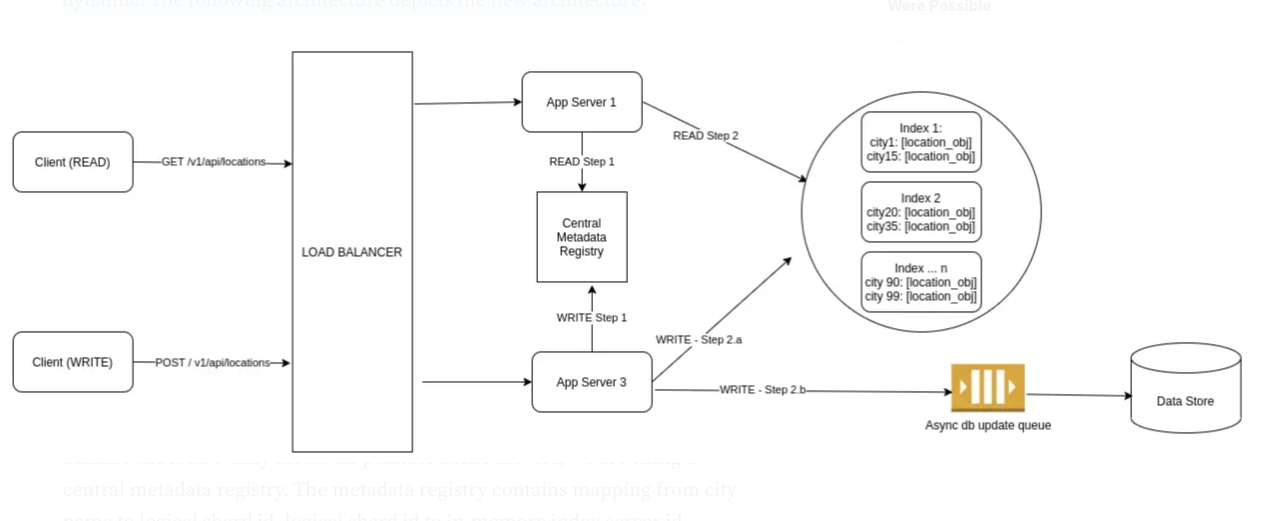
도시와 도시 경계 사이에 있는 배달 에이전트들, 그리고 특정 도시에만 과도하게 트래픽이 몰릴 경우(hotspot)를 고민하는 것이 필요해 보입니다.
접근 방법 3: Geo-Hash 기반의 파티셔닝 & 매칭된 Hash에 조회(query)하기
우리는 초당 수백만 쿼리와 같은 매우 높은 규모(Uber, Lyft와 같은 서비스의 경우)가 있는 경우 지역/도시 ID 기반의 파티셔닝만으로는 문제를 해결할 수 없다는 것을 확인했습니다. (필요에 따라) 반경을 기반으로 검색 영역을 늘리거나 줄이는 유연성을 가질 수 있는 전략을 찾아야 합니다.
Geo-Hash라는 주어진 위치(lat, long pair)를 인코딩하는 메커니즘이 있습니다. 핵심 개념은 지구를 평평한 표면으로 상상하고 표면을 여러 그리드(정사각형 또는 직사각형, 구현 방법에 따라 달라짐)로 계속 나누는 것입니다. 그림 4에서 먼저 평평한 지구 표면을 0, 1, 2, 3으로 표시되는 4개의 격자로 나눕니다. 이제 각 격자는 100,000 KM x 100,000 KM과 같은 큰 크기의 4개의 서로 다른 영역을 나타냅니다. (이 그림은 이해를 돕기 위한 것으로 정확하지 않을 수도 있습니다.)
위 방법으로는 매칭되는 위치를 검색하기엔 너무 큽니다. 그래서 더 나눌 필요가 있습니다. 이제 4개의 Grid를 각각 4개의 부분으로 나눌 것입니다. 그래서 Grid 0은 이제 내부에 4개의 Grid(00, 01, 02, 03)로 나뉩니다. 그림 4에서 Grid 2가 20, 21, 22, 23의 4개 부분으로 나누어져 있음을 보여줍니다. 이제 이 작은 그리드들이 각각 크기 20,000KM x 20,000KM의 영역을 나타낸다고 합시다. 이것도 매칭되는 위치를 검색하기엔 여전히 큽니다.
그래서 우리는 이러한 Grid들을 4개의 부분으로 계속해서 나누고 각 영역/Grid가 50 KM x 50 KM 영역 또는 검색에 적합한 일부 영역으로 표현될 수 있는 지점에 도달할 때까지, 반복적으로 나누는 작업을 계속했습니다.
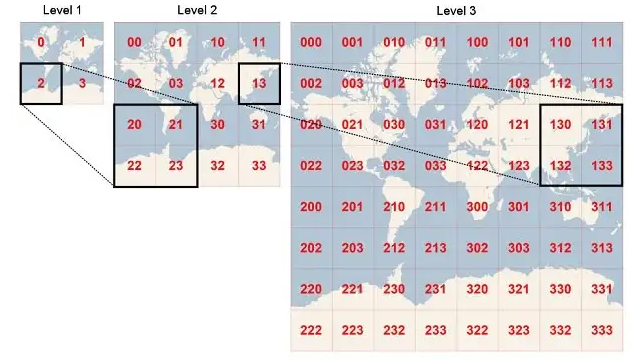
따라서 개념적으로 더 많은 Grid를 추가할수록 해당 영역(area)은 계속 작아집니다. 영역의 정밀도가 매우 높아지고 영역(area)을 나타내는 문자열의 길이가 증가합니다. 문자열 "02"는 20,000 KM x 20,000 KM의 영역을 나타내고 문자열 "021201"은 50 KM x 50 KM의 영역을 나타낼 수 있습니다.
(언급된 수치는 수학적으로 정확하지 않으며 Geo-Hash의 핵심 개념에 대한 이해를 돕기 위한 것입니다.)
간략히 말하자면,
고정밀 (High precision) Geo-Hash는 문자열 길이가 길고 작은 영역만 포함하는 셀을 나타냅니다. 낮은 정밀도(Low precision) Geo-Hash는 문자열 길이가 짧고 각각 넓은 영역을 포함하는 셀을 나타냅니다.
모든 Geo-Hash 라이브러리는 평평한 지구를 초기에 4개의 그리드로 표현할까요?
그렇지는 않습니다. 대부분의 Geo-Hash 라이브러리는 32개의 영숫자 문자를 기반으로 하며 표면을 32개의 직사각형으로 계속 나눕니다. 자기가 원하는 진수 체계 (2진수, 16진수 등)로 자신의 Geo-Hash 라이브러리를 구현할 수 있습니다. 그러나 핵심 개념은 동일합니다.
(Geo-Hash 내부에 대해서는 차후 별도의 글을 작성하도록 하겠습니다.)
실생활에서 기존 Geo-hash 라이브러리를 비교하고 성능, 노출된 API 및 커뮤니티 지원 측면에서 라이브러리가 얼마나 좋은지 확인합니다. Use Case가 맞지 않는 경우 직접 작성해야 할 수도 있지만 그럴 확률은 낮습니다.
좋은 Geo-Hash 라이브러리 중 하나는 Mapzen입니다. 실생활에서 셀/지역의 치수는 경도 및 위도에 따라 달라질 수 있습니다. 모든 곳이 동일한 정사각형 또는 직사각형은 아니지만 기능은 동일합니다.
그렇다면 우리의 경우 Geo-Hash를 어떻게 사용할 수 있나요?
먼저 30~50제곱KM과 같은 검색에 적절한 영역을 제공하는 Geo-Hash의 길이를 결정해야 합니다. 일반적으로 Geo-Hash 구현에 따라 그 길이는 4에서 6이 될 수 있습니다. 기본적으로 합리적인 검색 영역을 나타낼 수 있고 핫 샤드가 되지 않는 길이를 선택합니다. 길이 L을 결정한다고 가정해 보겠습니다. 이 L 길이 접두사를 샤드 키로 사용하고 더 나은 부하 분산을 위해 현재 개체 위치를 해당 샤드에 배포합니다.
Geo-Hash 개념이 작동하는 이유는 무엇인가요?
우리가 본 것처럼 특정 길이의 Geo-Hash는 유한한 평방킬로미터의 영역을 나타냅니다. 실제 현실에서는 한정된 수의 자동차나 배달원 또는 한정된 물체만 해당 영역에 들어갈 수 있죠. 따라서 최악의 경우에 얼마나 많은 개체가 있을 수 있는지 파악하기 위해 몇 가지 추정치를 개발하고, 그에 따라 핫 샤드 가능성을 줄일 수 있는 인덱스 머신 크기를 계산할 수 있습니다. 유한한 수의 개체가 있는 유한한 영역이 있기 때문에 어쨌든 논리적으로(매우 부하가 많은) 핫 샤드가 없을 것입니다.
인터뷰 팁: Geo-Hash가 어떻게 작동하는지 이해하여 편하게 이야기하거나, 면접관이 이 개념에 대해 모를 수도 있으므로 최소한 간략한 개요를 제공하세요. 면접관이 Geo-Hash의 내부 수학에 대해 질문할 가능성은 거의 없습니다. 그래도 가능하면 Geo-Hash 라이브러리의 구현을 이해하려고 시도합니다. 참조 섹션에 참고할 만한 링크를 넣어두었습니다.
Geo-Hash 기반의 개선된 아키텍처
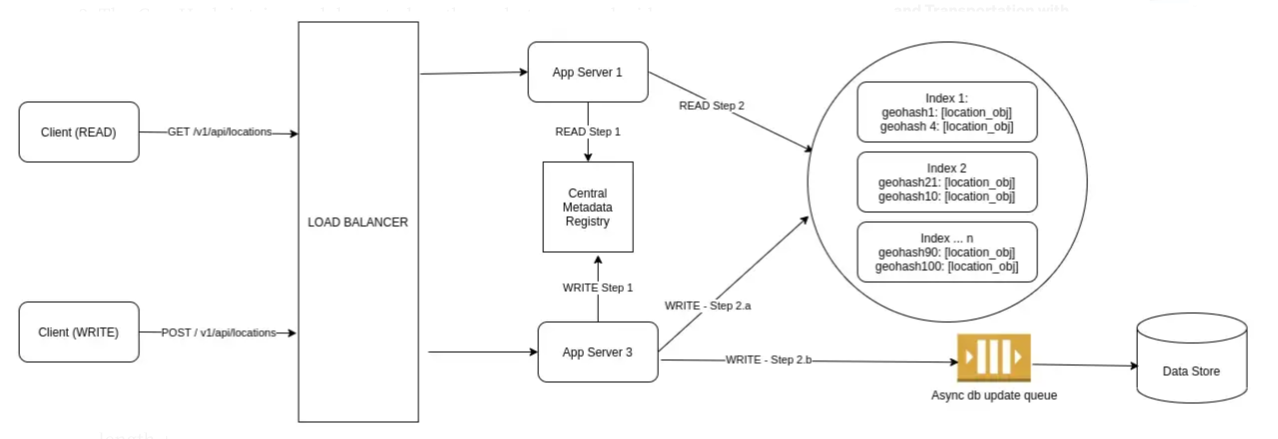
Write Path(쓰기 경로)
- 우리의 애플리케이션은 배달 에이전트 또는 드라이버 등의 객체로부터 현재 위치 세부 정보를 포함하는 지속적인 ping을 수신합니다.
- Geo-Hash 라이브러리를 사용하여 앱 서버는 위치의 Geo-Hash를 파악합니다.
- 우리가 무엇을 결정하든, Geo-Hash는 L 길이로 축소됩니다. 이제 앱 서버가 중앙 메타데이터 서버와 통신하여 위치를 결정합니다. 메타데이터 서버는 Geo-Hash 접두사에 대한 샤드가 이미 있는 경우 인덱스 서버 세부 정보를 즉시 반환하거나, 논리 샤드에 대한 항목을 생성하여 적절한 인덱스 서버에 매핑하고 결과를 반환할 수 있습니다.
- 병렬적으로, 앱 서버는 데이터를 비동기 대기열에 기록합니다.(데이터베이스 내의 위치를 업데이트 하기 위하여)
Read Path (읽기 경로)
- 애플리케이션 서버는 가장 가까운 위치를 찾아야 하는(위도, 경도) 쌍을 받습니다.
- Geo-Hash는 위치(location)로부터 결정되며 L 길이로 축소됩니다.
- 우리는 접두사로부터 이웃 Geo-Hash를 찾아야 합니다. 일반적으로 모든 8개의 이웃을 찾아야 합니다. Geo-Hash의 이웃을 쿼리할 때, 구현에 따라 각각 다른 8개의 이웃에 속하는 8개의 샘플 포인트를 얻을 수 있습니다. 왜 우리는 이웃을 알아내야 할까요?
API 요청에서 받은 위치가 Geo-Hash로 표시되는 영역의 경계 또는 가장자리 근처에 있을 수 있습니다. 일부 지점은 이웃 지역에 존재하지만 우리 지점과 매우 가까운 곳에 있을 수 있으며 이웃 지역의 접두사는 우리 지점의 접두사와 전혀 일치하지 않을 수 있습니다. 그래서 우리는 모든 8개 이웃의 Geo-Hash 접두사를 찾아야 모든 근처 지점을 제대로 찾을 수 있습니다. - 이제 우리는 길이 L의 9개의 접두사(이웃)을 가지고 있습니다. 하나는 우리 지점이 속한 지역을 위한 것이고 다른 하나는 이웃을 위한 것입니다. 9개의 병렬 쿼리를 실행하여 이 모든 영역에 속하는 모든 포인트를 검색할 수 있습니다. 이것은 우리의 시스템을 더 효율적이고 덜 느리게 만들 것입니다.
- 모든 데이터를 수신하면 애플리케이션 서버는 우리 지점으로부터의 거리를 기준으로 순위를 매기고 적절한 응답을 반환할 수 있습니다.
이 기술을 지원하기 위해, 하위 레벨의 설계를 변경해야 하나요?
나중에 db 계층을 샤딩해야 하는 경우를 대비하여 데이터베이스에 Geo-Hash 접두사를 추가해야 합니다. 길이 L의 해시 접두사를 샤드 키로 사용하여 동일한 작업을 수행할 수 있습니다. 새 스키마는 다음과 같습니다.
Collection Name: Locations
--------------------------
Fields:
-------
id - int (4+ bytes)
title - char (100 bytes)
type - char (1 byte)
description - char (1000 bytes)
lat - double (8 bytes)
long - double (8 bytes)
geo_hash - char(10 bytes)
geo_hash_prefix - char(6 bytes)
timestamp - int (4-8 bytes)
metadata - JSON (2000 bytes)
City to shard mapping:
----------------------
geo_hash_prefix (length = L) shard_id
------------------------------------------
a89b3 101
ab56e 103
fy78a 109
c78ab 908
a78cd 834
Shard to Physical server mapping
--------------------------------
shard_id index_server
----------------------------
101 index-1
103 index-2
109 index-1
908 index-3
834 index-2
우리 시스템에서, 어떻게 이러한 인덱스를 구현할 수 있을까요?
이러한 인덱스를 구현하기 위해서 세 가지 기본 사항이 필요합니다.
- 객체의 현재 위치(Uber의 경우 운전자, 음식 배달 앱의 경우 배달원 위치)
- Geo-Hash 접두사로부터 개체로 매핑하기
- (배달 원의 위치 같은) 동적인 객체를 다루기 때문에 동적 위치 데이터의 적절한 만료
Redis를 사용하여 위의 모든 요구 사항을 모델링 할 수 있습니다.
- 객체의 현재 위치를 (일반 키, 값)쌍으로 나타낼 수 있습니다. 여기서 키는 개체 ID이고 값은 위치 정보입니다. 장치에서 위치를 ping하면 해당 위치의 Geo-Hash를 식별하고 길이 L의 해시 접두사를 가지고(중앙 메타데이터 레지스트리에서) 해당 위치가 있는 샤드 & 인덱스 시스템을 찾아 해당 시스템의 위치 정보를 추가하거나 업데이트합니다.
(우리가 결정한 기준인) 10초나 30초마다 위치가 업데이트됩니다. 기억하시겠지만 이러한 위치는 항상 업데이트됩니다. 모든 업데이트 요청이 있을 때마다 이러한 종류의 키(동적으로 움직이는 객체의 위치를 나태내는)에 대해 만료 시간을 몇 분으로 설정할 수 있습니다.
"7619": {"lat": "89.93", "long": 52.134, "metadata": {...}}
- 위의 요구 사항 2 및 3에 대해 Redis의 Sorted Set(우선 순위 대기열)으로 구현할 수 있습니다. Sorted Set의 키는 길이가 L인 Geo-Hash 접두사가 됩니다. Sorted Set의 Member(구성요소)는 현재 Geo-Hash 접두사를 공유하는 객체의 ID입니다.(기본적으로 Geo-Hash로 표시되는 지역 내에 있음.) Score는 현재 Timestamp입니다. 점수를 사용하여 오래된 데이터를 삭제합니다.
This is how we set Redis sorted set for a given object location belonging to a Geo-Hash prefix:
ZADD key member score
ZADD geo_hash_prefix object_id current_timestamp
Example:
ZADD 6e10h 7619 1603013034
ZADD 6e10h 2781 1603013050
ZADD a72b8 9082 1603013089
Let's say our expiry time is 30 seconds, so just before retrieving current objects for a request belonging to a Geo-Hash prefix, we can delete all data older than current timestamp - 30 seconds, this way, expiration will happen gradually over time:
ZREMRANGEBYSCORE geo_hash_prefix -INF current_timestamp - 30 seconds
-INF = Redis understands it as the lowest value
(역자의 주 - 명령어에 대한 설명은 아래를 참고 하세요.)
이 전략을 실 생활에서 구현한 회사가 있나요?
-Lyft는 이 전략을 실행했습니다. 자세한 내용은 아래 동영상을 시청하세요.
Geo-Spatial Index를 생성하는 다른 방법이 있습니까?
Google에는 S2 라이브러리라는 Geo Hashing에 대한 대체 솔루션이 있지만 문서가 매우 열악합니다. 언젠가는 다른 블로그 게시물에 다룰 별도의 주제로 간직하겠습니다.
Geo-Hash를 사용한 인기 있는 제품이 있나요?
MongoDB & Lucene은 Geo-Hash를 사용하여 Geo-spacial 인덱스를 생성합니다.
마지막으로 시스템의 응답성이 매우 뛰어나야 한다는 요구사항에 따라 지연 시간을 더 줄일 수 있는 방법은 무엇인가요?
데이터가 정적일 경우를 대비하여 국가별 인덱스 서버의 복제본을 만들 수 있습니다. 택시 위치와 같은 동적 데이터의 경우 지역별로 매우 다릅니다. 따라서 해당 지역 또는 국가의 데이터로만 인덱싱되는 지리적으로 분산된 인덱스 서버를 사용할 수 있습니다. (예: 중국에서 데이터를 가져오면 중국의 인덱스 서버만 해당 데이터를 인덱싱합니다.)
Fault Tolerance(내결함성)을 위해 여러 국가 또는 한 국가의 다른 지역에 걸쳐 인덱스 서버의 복제본을 만들 수 있습니다. DNS 수준 로드 밸런싱을 사용하여 다른 국가에서 사용 가능한 가장 가까운 서버로 사용자를 리다이렉션(재 분배) 할 수 있습니다.
맺으며
지리적 위치 인덱스를 생성하기 위한 여러 가지 실제 접근 방식에 대해 논의했습니다. 모든 문제를 해결할 수 있는 단일 기술은 없습니다. 시스템의 규모, 시스템에 대한 사용자 기대치에 따라, 우리의 요구에 맞는 다양한 기술을 선택할 수 있습니다.
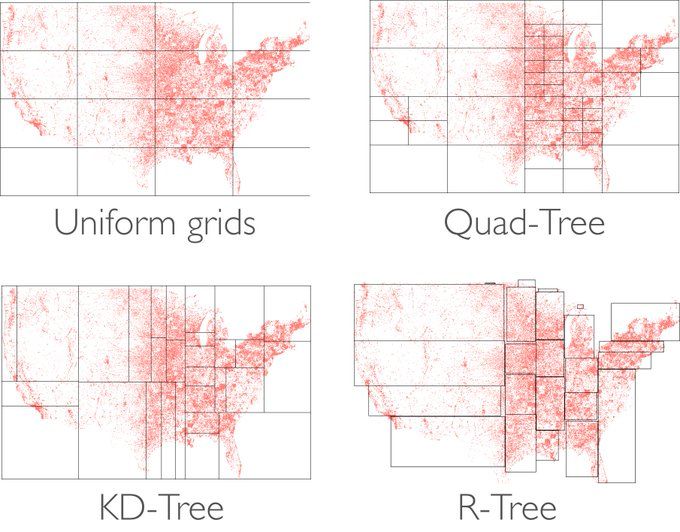
동일한 문제를 해결하기 위해 Quad-Tree를 사용하는 많은 기사가 있지만 실생활에서 얼마나 많은 회사가 이러한 솔루션을 사용하는지 또는 해당 솔루션이 실제로 얼마나 확장 가능한지 잘 모르겠습니다. R-Tree 또는 Uber의 육각형 계층적 공간 인덱스 기반 솔루션이 있으며 향후 기사에서 이에 대해 쓸 수 있습니다.
Geo-Spatial 인덱스를 만드는 몇 가지 실용적인 기술을 배웠기를 바랍니다. 이 기사에서 개선해야 할 사항이 있거나 나에게 듣고 싶은 주제가 있으면 의견을 말하고 알려주세요.
역자의 추천 : 부하를 적절하게 분배하기
참고할 만한 전략으로 IO에 따른 적절한 샤드 크기 분배 전략을 보시길 권해드립니다.
참고 자료
- https://www.pubnub.com/learn/glossary/what-is-geohashing/
- https://www.youtube.com/watch?v=cSFWlF96Sds
- https://www.youtube.com/watch?v=AzptiVdUJXg
- https://github.com/transitland/mapzen-geohash
- https://redis.io/commands/zadd
- https://redis.io/commands/zremrangebyscore
또한 흥미로운 다른 아키텍처 사례도 공유 드리니 참고해 보세요.
✔️ Uber 아키텍처와 시스템 디자인
✔️트위터는 왜 모니터링 시스템을 다시 만들었나?

![[배너] IMDEV 2023](/content/images/2023/02/IMDEV2023_-----------.jpg)