이 글은 Kousik Nath의 System Design: Design a Geo-Spatial index for real-time location search을 번역한 글로, 모든 저작권은 원저작자에 있습니다. 최대한 원문을 살리려 했으나, 이해를 돕기 위해 의역과 역주를 사용한 곳도 있습니다. 수정할 부분이 있다면 indigoguru@gmail.com으로 남겨주시길 바랍니다.
이번 시간은 아키텍처 전략: 실시간 위치 검색을 위한 지리 공간 인덱스 설계 시리즈 두 번째 시간으로 샤딩으로 아키텍처 개선하기에 대해 다루었습니다.
- 개요 및 아키텍처
- 샤딩으로 아키텍처 개선하기
- Geo Hash를 이용하여 아키텍처 개선하기
소개
우리는 실생활에서 항상 실시간 위치 검색 서비스를 사용합니다. 음식 주문 앱이나 주문형 택시 예약 서비스는 요즘 어디서나 볼 수 있죠. 이 글의 목적은 실생활에서 지리 공간 인덱스(Geo-spatial Index)에 대한 백엔드 인프라를 설계하는 방법을 살펴보는 것입니다.
지난 1편에서는 로드밸 런서와 캐시를 이용하여 부하를 배분 및 감소하는 전통적인 아키텍처를 설명했습니다.
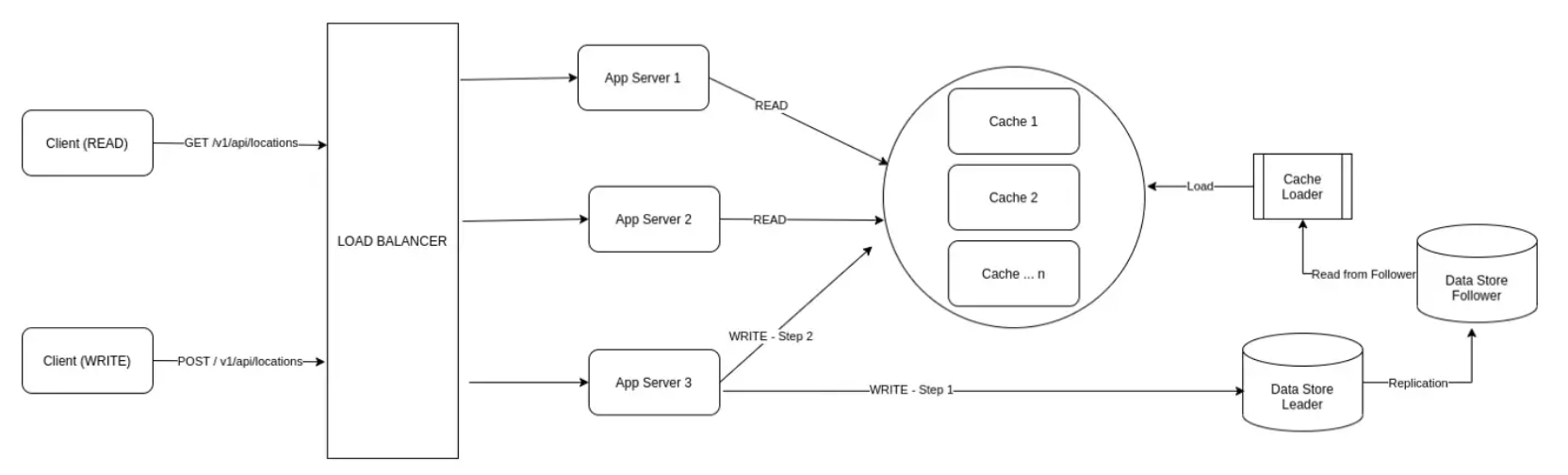
이번 시간에는 위 그림에서 더 개선된 아키텍처 접근법을 공유합니다. 더 나은 방법으로 캐시를 분할하는 방법을 알아보도록 하겠습니다.
접근 방법 2: 메모리에 파티션 생성하기 & 영리하게 파티션 검색하기
어떻게 하면 이전의 접근 방식보다 더 잘 할 수 있을까요?
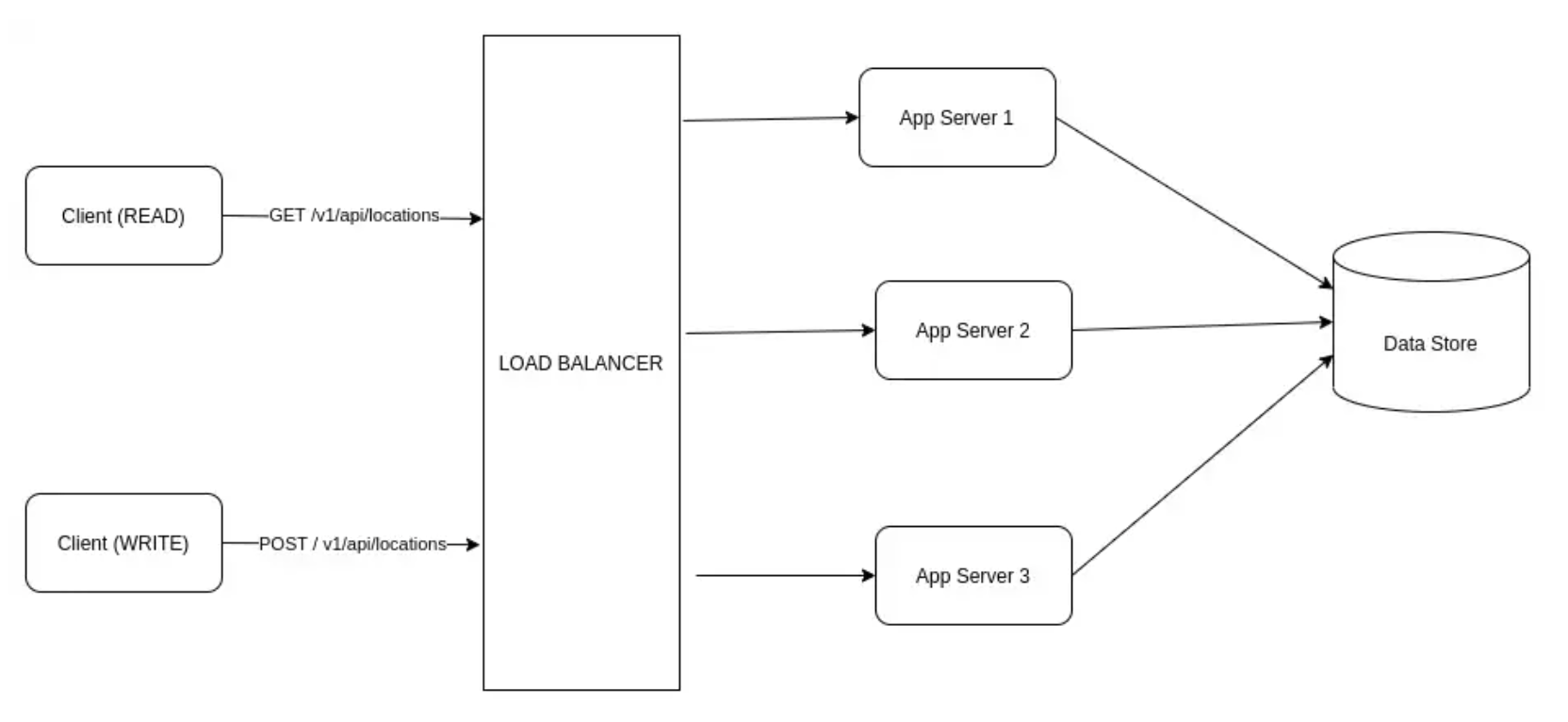
명확하게 그림 1의 병목 지점은 모든 읽기 작업에 대해 모든 캐시 노드를 쿼리하고 있습니다. 위치 검색 영역(공간)을 줄이기 위해 일종의 샤딩/분할 전략을 구현할 필요가 있습니다.
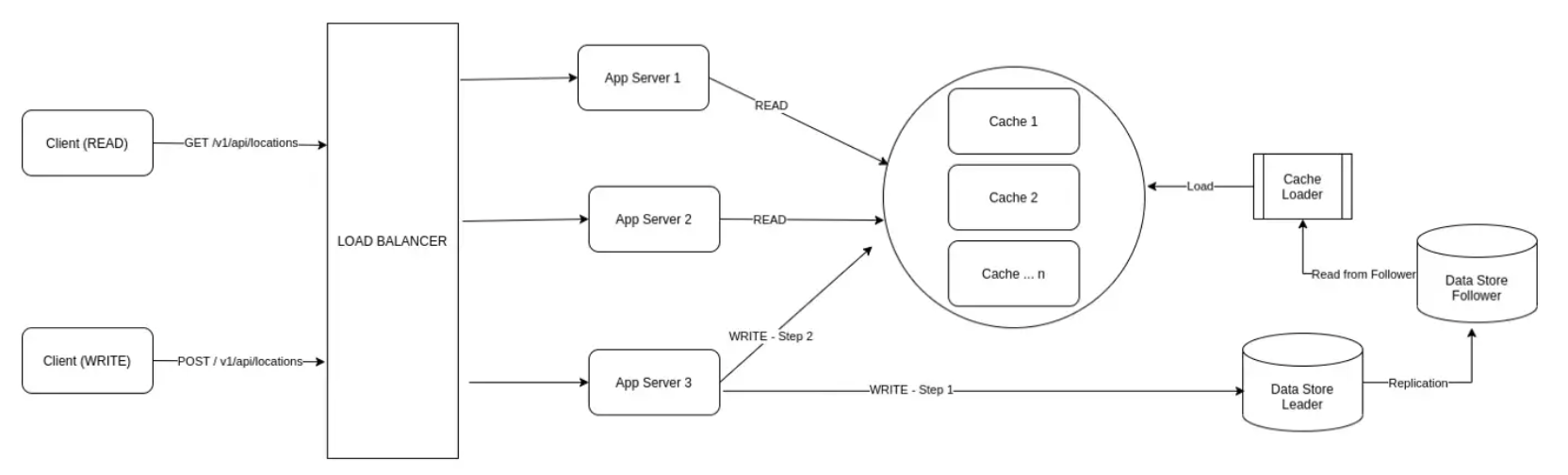
어떻게 파티션(분할 전략)을 구현해야 할까요?
다양한 사례에 대해 구현할 수 있는 표준 파티셔닝(분할 전략)은 없으며, 어떤 종류의 애플리케이션과 어떻게 데이터 액세스 패턴이 보이는지에 따라 전략은 다릅니다.
hyper-local food (근거리 동네에서 직접 하는 음식: 배달의 민족, 요기요 등) 배달 애플리케이션을 생각해 봅시다. 우리는 고객에게 효율적으로 배송 대행(배달 라이더/에이전트)을 배정하여 빠른 시간 내에 주문이 발송될 수 있도록 해야 합니다.
배달 에이전트(라이더)에게 주문을 할당할 수 있는지 여부를 결정하는 여러 가지 매개 변수가 있을 수 있습니다. 예를 든다면 배달 에이전트가 식당 및 고객 위치에서 얼마나 멀리 떨어져 있는지, 배달 중인지, 그리고 또 다른 주문을 받을 수 있는지 등입니다. 하지만 이 모든 필터를 적용하기 전에 제한된 수의 배달 에이전트를 가져와야 합니다.
대부분의 배달 에이전트(라이더)는 특정 지역이 아니라면 도시 안에 있을 것입니다. 인천의 배송 에이전트는 일반적으로 부산에 거주하는 고객에게 주문을 배송하지 않습니다.
(역자의 주 - 원문은 벵갈루루 / 하이데라바드라는 540km 떨어진 도시로 이야기하고 있으나 이해를 돕기 위해 인천/부산으로 의역하였습니다.)
또한 한 도시에 한정된 수의 에이전트가 있을 것이며, 그 수가 수천 명에 이르진 않을 것입니다.
(역자의 주 - 서울은 가능해 보이긴 하나, 저자의 도시의 기준으로 이해해 주시기 바랍니다.)
주문을 배치 처리하기 위한 수천 개의 위치를 그룹화하여, 검색하는 것은 좋은 아이디어입니다. (지방 또는 도시에서 발생한 주문을 배치 처리하고, 같이 배분하는 아이디어를 말함) 따라서 이 이론에 따라 우리는 도시 이름을 하이퍼 로컬 시스템의 파티션 키로 사용할 수 있습니다.
(배송 에이전트, 주문자) 디바이스의 현재 위치에서, 어떻게 도시 이름(파티션키)을 알아낼 수 있나요?
Google 지도는 현재 도시 및 관련 위치 정보를 식별하기 위해 Reverse Geo-Coding API를 제공합니다. 이 API는 Android 및 iOS 앱에서 사용할 수 있습니다.
개선된 새 아키텍처
배송 에이전트의 현재 위치는 대부분 동적으로 변하므로, 모바일 장치의 최신 위치로 지속적으로 서버에 전달(핑하도록) 할 수 있습니다.
핑은 10초마다 발생할 수 있습니다. 또한 서버가 배달 에이전트 디바이스에서 수신한 현재 위치는 10초 후에 만료되므로, 오래된 위치 정보 데이터는 저장하지 않습니다. 그램 3은 개선된 새로운 아키텍처입니다.
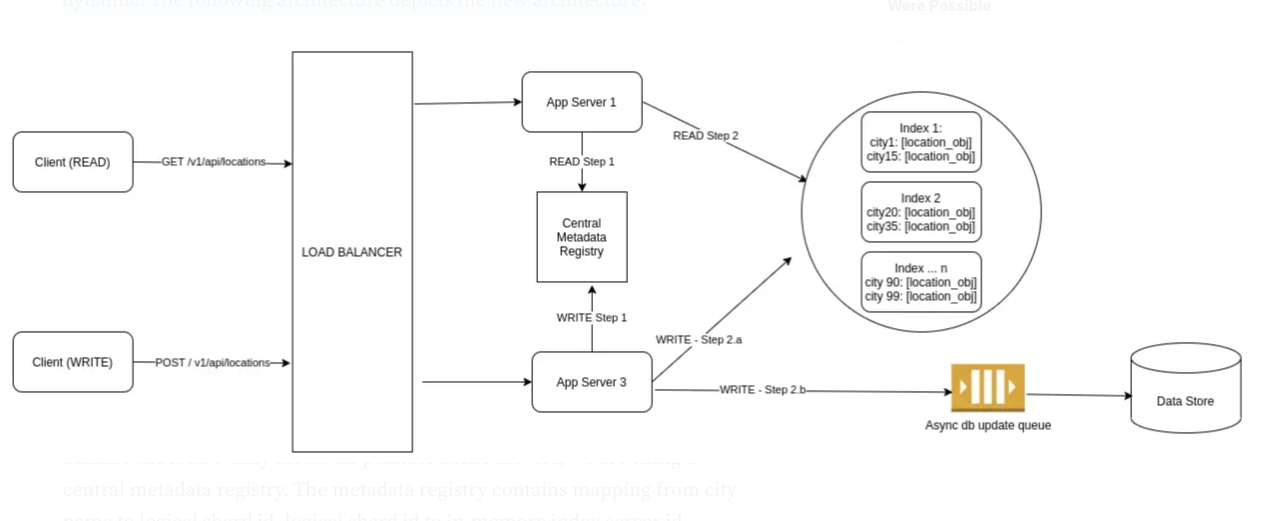
그림 2에 설명된 이전 아키텍처에서 일부를 변경하여 개선된 아키텍처를 생각해 냈습니다. (역자의 주 - 원문은 그림 1에서 개선했다고 했으나, 흐름상 그림 2가 적합해 보임)
도시 이름 기반의 위치 데이터 샤딩 체계를 도입했습니다. (도시 이름에 충돌이 발생할 위험이 있는 경우, 도시 ID를 사용할 수도 있음)
우리는 위치 데이터들을 여러 개의 논리적 샤드로 나눕니다. 서버 또는 물리적 머신은 많은 논리적 샤드를 포함할 수 있습니다. 논리적 샤드에는 특정 도시에만 속하는 모든 위치 데이터가 포함됩니다. 이 할당 전략에서 큰 도시에는 많은 양의 위치들이 포함되는 반면 작은 도시에는 적은 양의 위치들이 포함될 수 있습니다.
이러한 샤드를 관리하고, 가능한 모든 캐시 서버에 균등하게 로드 균형을 맞추기 위하여 중앙 메타데이터 레지스트리(central metadata registry)를 사용하고 있습니다. 메타데이터 레지스트리에는 도시 이름에서 논리적 샤드 ID로의 매핑, 논리적 샤드 ID에서 메모리 내 인덱스 서버 ID로의 매핑이 포함되어 있습니다. (서비스 검색 메커니즘을 사용하여 서버 ID를 사용하여 서버의 IP 주소를 얻을 수 있습니다. 역자의 주: 해당 부분은 이 글의 논의 범위를 벗어남.)
City to shard mapping:
''''''''''''''''''''''''''
city shard_id
''''''''''''''''''''''''''
Bangalore 101
Hyderabad 103
Mumbai 109
New York 908
San Francisco 834
Shard to Physical server mapping
''''''''''''''''''''''''''
shard_id index_server
''''''''''''''''''''''''''
101 index-1
103 index-2
109 index-1
908 index-3
834 index-2
한개의 샤드(예: index-1) 콘텐츠(위치 개체)는 다음과 같습니다.
"San Francisco":
[
{
"agent_id": 7897894,
"lat": 89.678,
"long": 67.894
},
{
"agent_id": 437833,
"lat": 88.908, "
long": 67.109
},
...
]
읽기 및 쓰기 요청 둘 다(먼저 요청 대상의 IP 주소를 사용하여) 메타데이터 레지스트리와 통신하여 배송 에이전트가 정확히 어느 도시에 있는지 또는 고객 요청이 어디에서 왔는지 확인합니다.
(IP에서)변환된 도시(도시 ID)를 이용하여 shard id를 식별하고, shard id를 이용하여 index server를 식별합니다. 마지막으로 요청은 특정 인덱스 서버로 전송됩니다. 따라서 더 이상 모든 캐시/인덱스 서버를 조회할 필요가 없습니다. 이 아키텍처에서는 읽기 또는 쓰기 요청이 데이터 저장소와 직접 통신하지 않으므로 API 지연 시간이 훨씬 더 줄어듭니다.
또한 그림 3의 아키텍처에서 소비자가 해당 위치 데이터를 선택하고 타임스탬프 또는 주문 ID 등과 같은 적절한 메타데이터로 데이터베이스를 업데이트하는 큐에 데이터를 넣습니다. 이것은 필요한 경우에 대비하여 이력을 추적하고 배달원의 이동 경로를 추적하기 위해서만 수행됩니다. 하지만 이내용은 이번 아키텍처에서 부차적인 부분이라 언급하지 않겠습니다
역자의 주 - 데이터를 큐에 넣어서 이후 업데이트하는 이유는 한 건씩 직접 DB에 업데이트하면 락이 빈번하게 발생하며 성능 저하가 발생한다. 보통 데이터를 개별적으로 한 건씩 넣는 것보다 1분 또는 10초와 단위 시간마다 묶어서 일괄 배치 처리하는 게 훨씬 DB의 부하를 줄일 수 있다.
중앙 레지스트리에서 정적 파티션을 관리하는 것이 파티션을 관리하는 가장 간단한 방법입니다. 캐시 서버 중 하나에 부하가 많아지는 경우, 부하가 많이 발생하는 시스템(인스턴스)에서 다른 시스템(인스턴스)으로 논리적 파편의 일부를 이동하거나 새 시스템(인스턴스)를 할당할 수 있습니다.
비록 파티션을 조작하고 이동하는 정책이 자동화되어 있지 않고 사람의 개입이 요구되더라도 보통은 운영적인 실수를 일으킬 가능성은 매우 적습니다. 그러나 일반적인 성장, 비정상적인(월드컵 등) 성장이 발생할 경우도 있습니다.
수천 대의 물리적 시스템이 있을 때 정적 파티션을 관리하는 것은 어려움이 될 수 있으므로 자동화된 파티셔닝 체계를 살펴보고 이러한 활용 사례가 만족하는 도구를 개발해야 합니다. (역자의 주: 성장의 속도를 고려하여, 파티셔닝을 수동으로 할 것인가? 자동으로 할 것인가?)
파티션 키로 도시를 선택하면 어떤 트레이드 오프가 있습니까?
현재 배달 에이전트 중 한 명이 두 도시의 경계 근처에 있을 가능성이 매우 높습니다. 예를 들어 그는 A 도시에 있는데 이웃 도시 B에서 주문이 들어오고 배달 에이전트와 도시 B의 고객과의 거리가 상당히 짧다고 가정해 보겠습니다. 하지만, 안타깝게도 배달 에이전트는 도시 B에 없기 때문에 우리는 에이전트를 파견할 수 없습니다. 따라서 때때로 도시 기반 파티셔닝이 모든 사용 사례에 최적이 아닐 수 있습니다. 또한 크리스마스나 새해와 같은 특정 행사에 대한 도시의 수요가 증가함에 따라 특정 도시 기반의 샤드는 매우 많은 부하가 발생할 수도 있습니다. 이 전략은 하이퍼 로컬 시스템에서 작동할 수 있지만 Uber와 같은 매우 큰 스케일(범위)를 가진 시스템에서는 적합하지 않습니다.
다음 영상에서는 이러한 문제를 해결하기 위한 Uber의 전략에 대해 상세히 알수 있습니다.
역자의 가이드
14분터 시작하는 Hot Spot 부분부터 참고하시기 바랍니다.
간단히 요약하자면, 긴 특정지역에 운전자와 라이더(고객)이 몰리면 Sub Sharding 전략과 복제의 전략을 이용해서 부하를 분산하는 전략을 사용하고 있다는 것입니다.
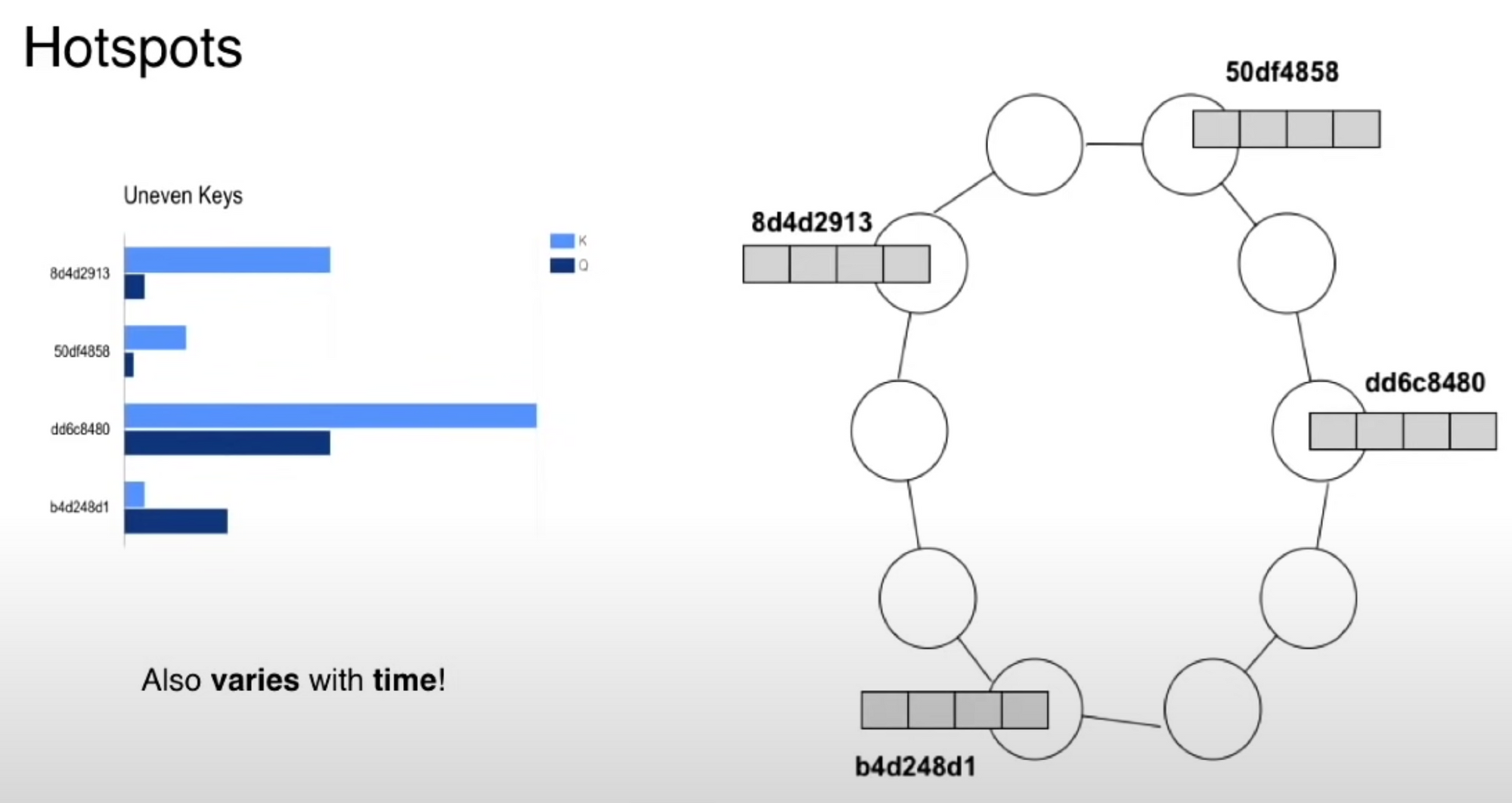
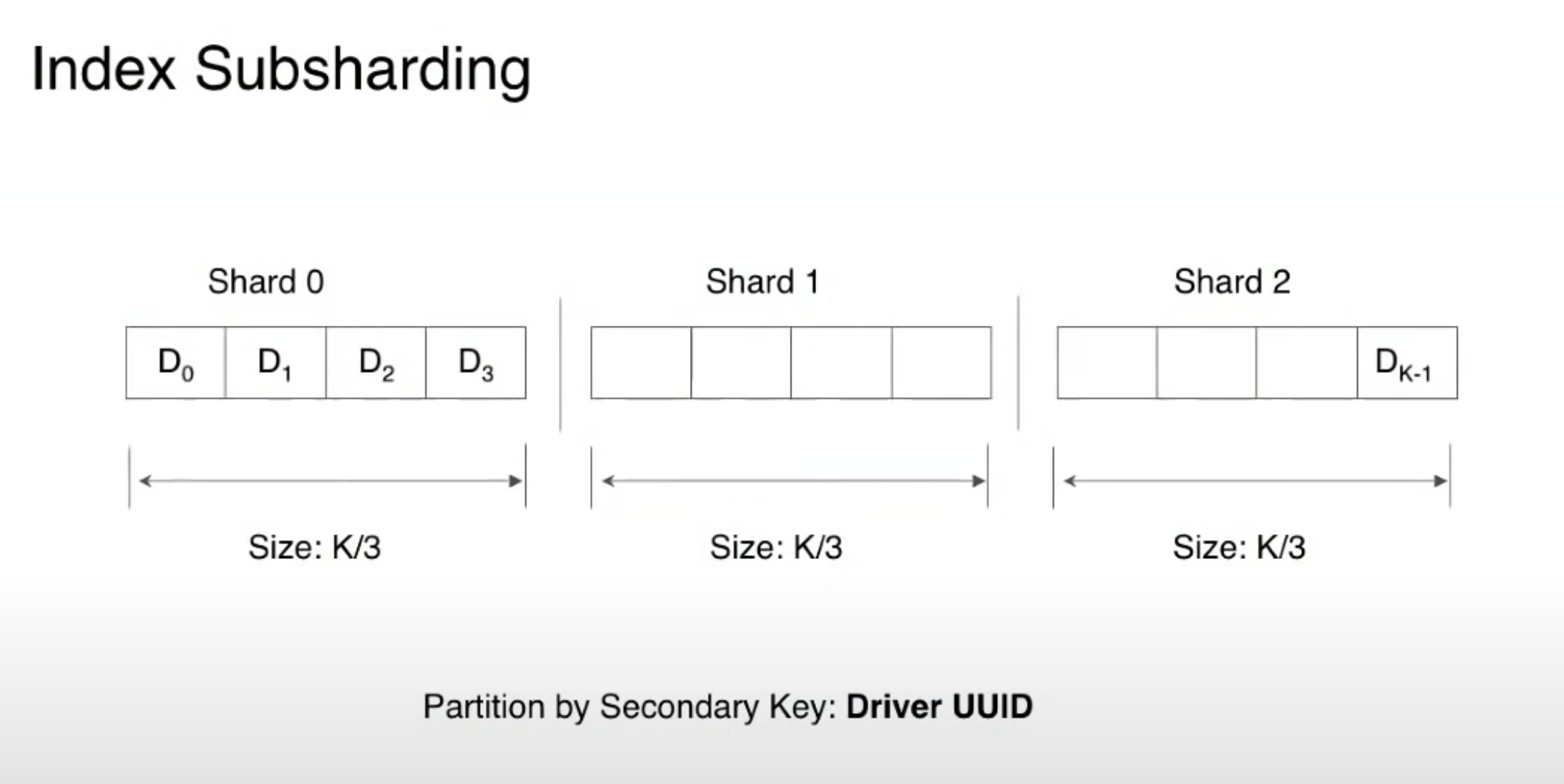

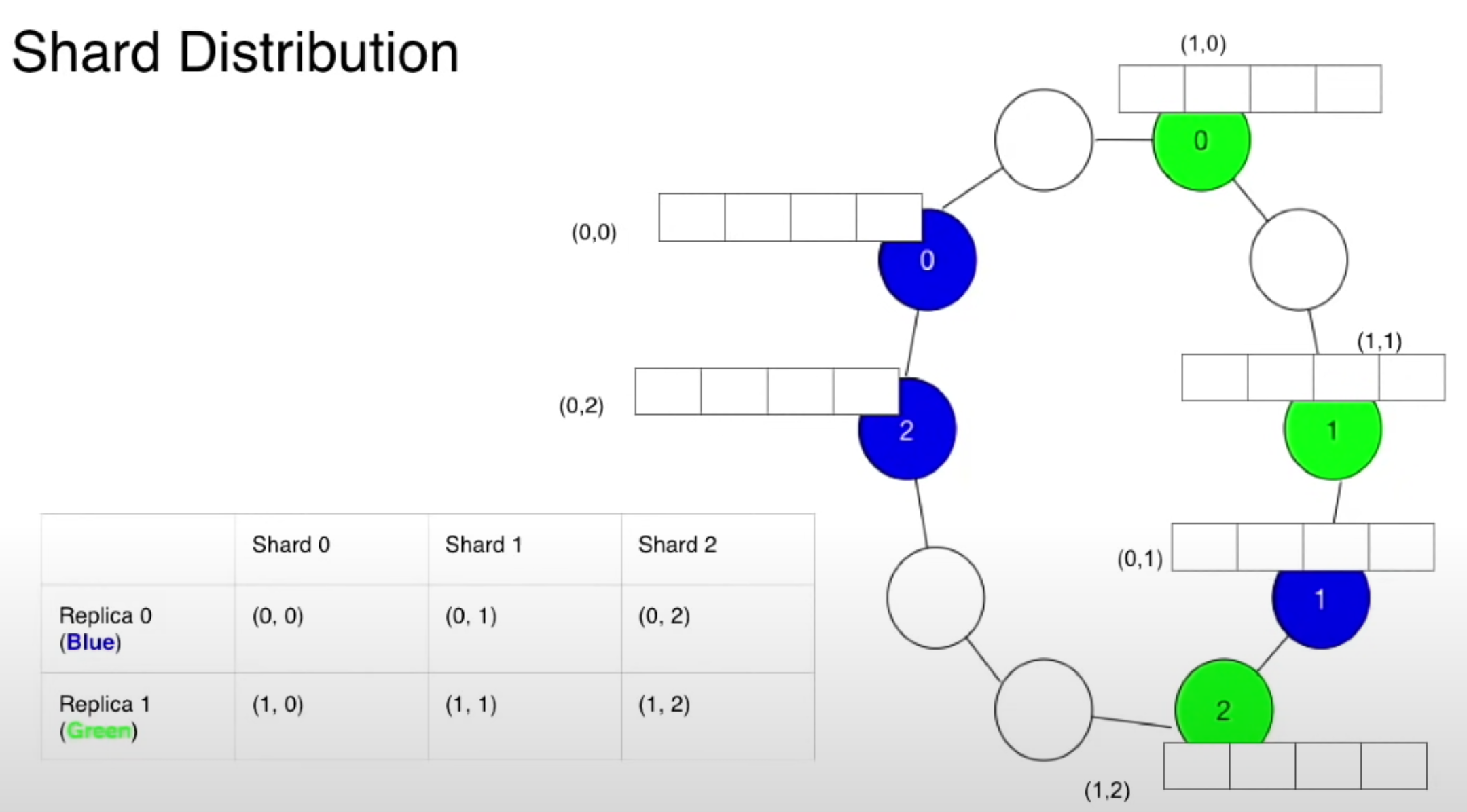
단 복제본을 만들 경우 NRT (near real time)에 준하는 복제 방식을 선택하는지 엄격한 Consistency를 적용하는지는 알 수 없지만 전자를 선택해도 상관없을 것으로 유추됩니다. 이유는 모든 드라이버 데이터를 엄격한 일관성으로 관리하는 것은 많은 성능 저하를 가져오기 때문입니다. 또한 샤드에서 수십, 수백 명의 드라이버(운전자)중 한,두 명이 동기화되지 않아도 현재 저장되어 있는 운전자 리스트에서만 고르면 되므로 큰 이슈가 아닐 것으로 생각됩니다. 물론 동기화가 완벽하게 안되어 예외적인 요청이 갈수 있는데 이것은 승객을 태우고 있는지, 그 위치에 벗어나지 않는지 한 번 더 체크하고 호출하는 추가적인 예외 처리가 더 필요해 보입니다.
파티션 중 하나가 충돌하면 어떻게 되나요? 어떻게 데이터를 복구해야 하나요?
위치 데이터는 매우 동적이며, 시스템에서 몇 초 동안만 유지되기 때문에(만료 시간이 짧기 때문에) 파티션이 충돌한 후 복구되거나, 수동으로 페일오버(복구전략)를 수행하면 됩니다. 클라이언트 장치에서 시스템으로 지속적으로 스트리밍되므로 데이터가 자동으로 다시 축적됩니다.
그럼 수백만 개에서 수 십억 개의 위치를 분할하여, 탐색할 수 있는 다른 방법이 있을까요? 3편에서 다루어 보겠습니다.