이 글은 Kousik Nath의 System Design: Design a Geo-Spatial index for real-time location search을 번역한 글로, 모든 저작권은 원저작자에 있습니다. 최대한 원문을 살리려 했으나, 이해를 돕기 위해 의역과 역주를 사용한 곳도 있습니다. 수정할 부분이 있다면 indigoguru@gmail.com으로 남겨주시길 바랍니다.
이번 시간은 아키텍처 전략: 실시간 위치 검색을 위한 지리 공간 인덱스 설계 시리즈 첫 번째 시간으로 개요 및 아키텍처에 대해 다루었습니다.
소개
우리는 실생활에서 항상 실시간 위치 검색 서비스를 사용합니다. 음식 주문 앱이나 주문형 택시 예약 서비스는 요즘 어디서나 볼 수 있죠. 이 글의 목적은 실생활에서 지리 공간 인덱스(Geo-spatial Index)에 대한 백엔드 인프라를 설계하는 방법을 살펴보는 것입니다.
공간을 다루는 여러 회사가 어떻게 문제를 해결했는지, 다양한 접근 방식의 장단점은 무엇인지, 어떻게 문제에 접근했는지 다루어보겠습니다. 또한 시스템 및 아키텍처 설계 기술 인터뷰 관점에서 문제에 접근하는 방법에 대해서도 알아보겠습니다.
실제 사용 사례
- Uber, Lyft, Bolt와 같은 실시간 택시 예약 서비스
- Yelp와 같은 실시간 호텔/레스토랑 검색
- 마케팅 프로모션을 위해 특정 매장 근처에 있는 쇼핑객을 대상으로 하는 서비스
- 하이퍼 로컬 배달 시스템 — Uber Eats와 같은 레스토랑 주문에 대해 배달 에이전트를 파견하는 서비스
설계 요구 사항
- 우리의 서비스는 전 세계적으로 사용됩니다.
- 클라이언트 또는 사용자가 위치를 지정하면 당사 서비스는 특정 수의 주변 위치를 파악해야 합니다.
- 인프라는 안정적이어야 합니다.
- 시스템은 200ms 이하로 응답해야 합니다. 따라서 지연 시간을 줄이기 위한 설계는 큰 관심사입니다.
- 초당 50,000개의 읽기 쿼리와 초당 10,000개의 쓰기 쿼리를 지원해야 합니다.
- 사용자가 증가함에 따라 시스템은 큰 부담 없이 선형적으로 확장되어야 합니다.
- 단순화를 위해 위치가 제목, 설명, 유형, 위도 및 경도 (
title,description,type,latitude&longitude)로 표시된다고 가정합니다. - 시스템은 MULTI-TENANT가 아닙니다.
- 클라이언트는 일반적으로 모바일 클라이언트이지만 웹 클라이언트도 있을 수 있습니다.
정량적 분석 (Quantitative Analysis)
2억 개의 위치(location)에서 시작한다고 가정해 보겠습니다. 성장률이 매년 25%일 때, 다음 몇 가지 추정 치를 보여드리겠습니다.
스토리지 측정 (Storage Estimation)
말했듯이 위치는 타이틀, 유형, 설명, 위도, 경도(title, type, description,lat, long)로 표시됩니다.
이러한 모든 매개변수에 대해 합리적인 숫자를 가정해 보겠습니다.
제목=100바이트, 유형=1바이트, 설명=1,000바이트, 위도= 8바이트, 길이= 8바이트 (title = 100 bytes, type = 1 byte, description = 1000 bytes, lat = 8 bytes, long = 8 bytes)
따라서 단일 위치에는 최소한 다음의 용량이 필요합니다(100 + 1 + 1,000 + 16) bytes = ~1,120 bytes = ~1,200 bytes
2억 개의 위치를 기반으로 서비스를 시작한다면, 다음과 같은 용량이 필요합니다 200 * 10⁶ * 1200 bytes = 240GB(Gigabytes)
매년 25%의 성장률로 5년을 계획한다면 다음과 같은용량이 필요합니다.
1년 차: 240GB
2년 차: (240 + 240 * .25) = 300GB
3년 차: (300 + 300 * .25) = 375GB
4년 차: (375 + 375 * .25) = ~470GB
5년 차: (470 + 470 * .25) = ~600GB
데이터 저장소에 위치 정보를 저장하기 위해서는 최소 600GB의 저장소가 필요합니다. 사용 사례에 따라 저장해야 할 다른 메타데이터/보조 정보나 검색 또는 쿼리 작업을 용이하게 하기 위해, 데이터 저장소 내부에 저장해야 하는 메타데이터를 고려하면 실제로 더 많은 스토리지가 필요할 수 있습니다. 따라서 스토리지를 최소 1TB로 추정해 보겠습니다.
그렇다면 1TB의 데이터를 저장하려면 몇 대의 시스템이 필요할까요? 현재 AWS 또는 Azure에는 비용 및 사용 사례에 따라 16TB에서 64TB의 스토리지를 제공할 수 있는 많은 데이터베이스 시스템 유형이 있습니다. 따라서 이상적으로 1대의 기계로 사용 사례를 지원하기에 충분합니다. 하지만 성장률이 높거나 인기가 높아지면 스토리지 또는 시스템이 더 필요할 수 있습니다. 그럼에도 불구하고, 우리는 수평적 확장(horizontal scaling)을 지원하도록 인프라를 설계할 것입니다.
역자 주 : 용량 산정만큼 , 실제 IOPS (IO per Second)의 산정도 중요하다. 사용자가 늘어남에 따라 초당 얼마큼의 IO를 처리할 수 있는지, 디스크에 어떻게 이 IO를 분배할지에 대한 전략도 같이 고민되어야 한다.
인터뷰 팁: 실제로는 예상 성장률이 확실해지면 자세한 스토리지 요구 사항을 제시할 수 있습니다. 일반적으로 엔지니어링팀과 제품팀이 협력하여 수치를 산출합니다.
하지만 인터뷰에서는 상당한 시간이 소요될 것이기 때문에 계산할 필요가 없습니다.
첫 해에 계산하고 어떤 숫자로 추정할 수 있습니다. 충분히 합리적인 데이터 크기와 증가를 염두에 두고 데이터를 기반으로 결정을 내리고, 불합리한 숫자를 버리지 말고, 너무 많은 수치를 벗어난 추정은 좋지 않다는 것을 면접관에게 보여주기 위한 것입니다.
읽기가 많은 시스템 vs 쓰기가 많은 시스템
요구사항은 이미 초당 50,000 읽기 쿼리와 10,000 쓰기 쿼리를 지원해야 한다고 명시되어 있습니다. 따라서 우리 시스템은 읽기:쓰기 비율 5:1로, 극도로 읽기가 많다는 것은 이미 정해져있습니다.
요구 사항에 읽기에 대한 설명 또는 힌트가 없는 경우 어떻게 해야 할까요? 읽기/쓰기 비율은 어떻게 결정하시겠습니까?
우선, 어떤 종류의 시스템을 설계하고 있는지 고려해야 합니다. Facebook 뉴스피드 또는 Twitter Timeline은 읽기와 쓰기가 많은 시스템입니다. Google 검색 또는 트윗 검색 시스템과 같은 것을 설계하는 경우는 읽기가 매우 많은 시스템이고, 로그 전달 애플리케이션을 설계하는 경우 쓰기가 매우 많은 애플리케이션입니다. 또한 얼마나 많은 DAU(일일 활성 사용자)가 있는지, 그들이 생산하고 있는 콘텐츠의 양과 매일 소비하고 있는 콘텐츠의 양을 고려해야 합니다. 여기서 말씀드린 대로 추측해 보세요. 시스템이 읽기가 많은지 쓰기가 많은지 추측하실 수 있을 겁니다.
인터뷰 팁: 시스템 설계 인터뷰에서 다양한 시스템의 DAU에 대해 이야기하기 전에 DAU, 일일 트윗, 매일 얼마나 많은 사진/동영상이 Facebook 또는 Twitter에 업로드되는지와 같은 필요한 정보 목록을 작성합니다. YouTube 등 또는 Google이 크롤링하는 웹사이트 수 또는 Yelp가 매일 다양한 시스템에 대해 서비스를 제공하는 사용자 수 등 이러한 애플리케이션에 대한 읽기 및 쓰기의 일일/월간 통계 목록을 만들어 보세요.
사용 규모에 대해 모르는 경우, 명시된 시스템이 얼마나 많은 사용자 또는 읽기/쓰기를 가질 수 있는지 대략적으로 생각하여 면접관과 함께 확인해 보세요. 면접관들은 보통 여러분의 예상이 옳다고 생각하는 것과 약간 어긋날 경우에 대비하여 여러분의 측정 기준에 도움을 줍니다. 하지만 직접적으로 묻지 말고, 대략적인 적절한 수치를 던질 수 있는 첫 단계를 밟으세요 DAU와 연관된 매개 변수로부터 추정치를 도출해 보고 나서 물어보세요.
더 중요한 것은 모의 인터뷰를 연습하거나, 다른 사람의 모의 인터뷰를 자주 시청하여 이러한 수치와 아이디어에 익숙해지는 것입니다.
네트워크 밴드위스(Network Bandwidth) 측정
대역폭 및 처리량 계산을 수행하려면 네트워크를 통해 전송하는 데이터의 양을 알아야 합니다. API Signature(명세)을 결정해야 제대로 판단할 수 있습니다. 다음 섹션을 살펴보겠습니다.
네트워크 프로토콜 선택
앞서 언급한 요구사항에서, 웹&모바일 클라이언트를 지원해야 되다고 명시하고 있고 있습니다. 타사 개발자가 인프라와 통합해야 하므로 개발자 친화적이고 사용하기 쉽고 이해하기 쉬운 프로토콜을 선택해야 합니다. 다음과 같은 여러 가지 옵션들이 있을 수 있습니다. (SOAP, RESTful API over HTTP 또는 RPC API)
SOAP: 꽤 오래되고 복잡하며, 중첩된 스키마이며 일반적으로 요청과 응답을 표현하는 데 XML이 사용됩니다. 개발자에게 그다지 친숙하지도 않습니다. SOAP은 선택하지 않겠습니다.
RPC: 동일한 데이터 센터에서의 통신에 적합한 사용 사례에 적합하며 RPC는 클라이언트 및 서버 측 스텁을 생성해야 밀접하게 연결됩니다. 필요한 경우 클라이언트-서버 통합을 변경하는 것은 어려울 것입니다. 그래서 우리는 RPC도 선택하지 않을 것입니다.
HTTP 기반의 Restful API: 이것은 오늘날 사실상의 표준입니다. 개발자 친화적이며, 대부분의 개발자들은 커뮤니티에서 잘 이해된 요청/응답을 표현하기 위해 JSON 스키마를 사용하며, 필요할 때 새로운 API 버전을 통합하고 도입하기 쉽습니다. 이러한 이유로, 우리는 HTTP를 사용하여 API를 RESTful API로 설계를 진행할 것입니다.
API 시그니처 (명세)
우리의 시스템을 외부에 노출하기 위해, 필요한 요청과 응답을 위한 최소한의 API 구조를 결정해야 합니다.
Get Location (API)
Request(요청): 우리는 위치 기반 시스템을 설계하고 있기 때문에 클라이언트에서 가져와야 하는 최소한의 데이터는 경도 및 위도(longitude & latitude)입니다. 또한 클라이언트가 검색할 최대 반경(maximum radius)을 지정할 수 있는 유연성을 지원하는 경우 반경(radius)을 입력으로 사용할 수 있습니다. 또한 우리는 클라이언트가 관심 있는 일치하는 위치의 max_count를 취할 수 있습니다. 따라서 GET HTTP API는 아래와 같을 수 있습니다.
GET /v1/api/locations?lat=89.898&long=123.43&radius=50&max_count=30
인증 시스템이 이미 구축되어 있다고 가정하므로 여기에서는 인증에 대해 고려하지 않겠습니다
radius & max_count 매개 변수는 선택적 매개 변수입니다. 또한 클라이언트가 GET 위치 API에 값을 지정하거나 지정하지 않을 경우, 애플리케이션 서비스에 최대 허용 반경 또는 위치 수를 정확하게 결정할 수 있는 비즈니스 로직이 있다고 가정하겠습니다
Response (응답) : 응답은 다음과 같습니다
GET /v1/api/locations?lat=89.898&long=123.43&radius=50&max_count=30
HTTP 1.1 Response Code: 200
{
"locations": [
{
"id": 7910837291,
"title": "Toit",
"desceription": "Best brewary in the area",
"lat": 89.33,
"long": 123.222
},
{
"id": 1697290292,
"title": "English Craft",
"desceription": "Best brews hands down",
"lat": 88.214,
"long": 122.908
}
]
}
응답의 위치 리스트(결과)에는 클라이언트가 지정한 최소 max_count 또는 제공된 위치에 대해 시스템에서 사용할 수 있는 모든 항목이 포함될 수 있습니다.
Create Location API
마찬가지로 다음과 같이 위치 API를 만들 수 있습니다:
POST v1/api/locations
{
"locations": [
{
"title": "Toit",
"desceription": "Best brewary in the area",
"lat": 89.33,
"long": 123.222
},
{
"title": "English Craft",
"desceription": "Best brews hands down",
"lat": 88.214,
"long": 122.908
}
]
}
Response: 202 ACCEPTED
위 POST API는 단일 위치 또는 여러 위치를 만드는 데 사용할 수 있는, 대량 API입니다. 대량 API가 필요한지 단일 개체 API가 필요한지 여부는 클라이언트가 시스템에서 원하는 것에 따라 달라질 수 있습니다.
인터뷰 팁: 인터뷰에서 대량 API가 필요한지 여부를 명확히 해야 할 수 있습니다. 그렇다면 목록에서 지원하는 위치 개체 수를 명시해야 합니다. 시스템의 처리량이나 네트워크 효율성에 영향을 미치기 때문에 개체 수를 유연하게 보낼 수 없습니다.
응답 코드(response code)는 202 ->이는 시스템이 API의 잠재성(조건을 충족하지 못하는 것 - 예 속도 지연, 일관성 없는 결과 반환 등)을 줄이기 위해 요청을 비동기식으로 처리하는 것을 의미합니다.
이제 API 요청 및 응답 스키마가 명확하므로 네트워크 대역폭 및 처리량 계산을 수행해 보겠습니다.
네트워크 밴드위스(Network Bandwidth) 측정
GET API 대역폭 (bandwidth)
GET 위치 API의 경우 응답 목록에서 최대 30개의 위치를 지원한다고 가정해 보겠습니다. 따라서 단일 응답 객체 크기는 다음과 같습니다.
id(int를 고려한 4bytes) + title (100 bytes) + description (1000 bytes) + lat (8 bytes) + long(8 bytes) = 1120 바이트.
30개 위치의 경우 응답 헤더 및 모두와 같은 추가 메타데이터를 고려하여 1120 * 30 bytes = 33.6 Kilobytes = ~35 Kilobytes를 보내야 합니다.
따라서 단일 GET 요청은 35KB의 대역폭을 사용합니다. 50000 GET 쿼리를 지원하는 경우 초당 35 * 50000 KB = 1.75 GB = ~ 초당 2GB의 데이터를 지원해야 합니다.
POST API 대역폭
초당 10000 쓰기 요청을 지원해야 합니다. 대량 쓰기 (bulk write) 및 클라이언트가 API 호출당 최대 30개의 위치를 업로드하는 것을 고려하여 다음과 같이 처리량을 지원해야 합니다.
10000 * (30 * (title(100 bytes) + description(1000 bytes) + lat(8 bytes) + long(8 bytes))) = ~350 MB per second. (초당 350MB)
이것은 상당히 작지만 성장과 함께 이 수치는 증가할 수 있습니다.
따라서 읽기 및 쓰기 쿼리를 결합하면 (1.75GB + 350MB) = 초당 ~2.1GB 데이터 전송을 지원해야 합니다.
시스템이 점점 더 성장할 것이기 때문에, 이러한 처리량을 달성하기 위해 애플리케이션 서버 전체에 로드를 분산해야 할 수도 있음을 의미합니다.
인터뷰 팁: 인터뷰에서 너무 많은 계산을 수행하면 완료하는 데 시간이 오래 걸릴 수 있습니다. 따라서 면접관에게 그러한 대역폭을 추정할 필요가 있는지 물어보세요. 일반적으로 스토리지 및 네트워크 대역폭 계산은 인터뷰에 충분해야 합니다. 정확할 필요는 없지만 빠르고 편안하게 계산할 수 있도록 여러 사용 사례에 대해 연습해야 할 수도 있습니다.
데이터베이스 스키마
높은 수준의 디자인을 할 때 데이터베이스 스키마에 대해 생각하는 것은 매우 자연스러운 일이지만 Use Case(사용 사례)에 대해 먼저 생각하고 다음 질문을 스스로에게 물어보세요.
어떤 종류의 위치 데이터를 저장하고 있나요? 정적인가요? 동적인가요?
레스토랑 위치와 같이 데이터가 정적인 경우 이러한 위치는 대부분 정적이므로 해당 위치 데이터를 데이터 저장소에 넣는 것이 좋습니다.
위치 데이터가 택시 위치 또는 배달원 위치와 같이 매우 동적이며 해당 위치가 지속적으로 시스템에 푸시되는 경우 이러한 목적 또는 그 목적을 위해 추적을 활성화하지 않는 한 영구 데이터 저장소에 저장하는 것은 이치에 맞지 않습니다.
이제 데이터 저장소를 사용해야 한다는 것을 깨달았다면 어떤 종류의 저장소를 보고 있나요?
이것은 논쟁의 여지가 있는 주제입니다. 무엇을 선택할지는 데이터 모델 및 데이터 액세스 패턴에 따라 다릅니다. 관계형 저장소와 비 관계형 저장소 간에는 많은 논쟁이 있습니다. 그러나 항상 간단하게 시작할 수 있습니다. 테이블 형식이나 관계형 형식으로 데이터를 시각화하는 것이 항상 더 쉽습니다. 데이터 모델에 따라 다양한 데이터베이스 기술을 탐색, 벤치마킹 및 데이터와 비교하고 해당 기술에서 사용 사례에 대한 지원을 찾지 않는 한 하나를 선택하기가 어렵습니다.
이 시점에서 지금 당장은 특정 기술을 선택하지 않고 데이터 저장소에 저장해야 하는 최소한의 데이터 구조가 무엇인지 식별하는 작업을 진행하겠습니다.
데이터 저장소에도 동적 데이터를 저장할 수 있나요? 거기에 무엇이 문제가 될까요?
우리는 저장할 수 있지만 삽입 또는 업데이트 속도가 매우 높아 본질적으로 디스크/IO 사용 측면에서 시스템 비용이 매우 많이 들고 더 큰 규모에서는 쓸모가 없게 됩니다. 이 기사의 뒷부분에서 완전한 동적 데이터를 처리하는 방법을 살펴보겠습니다.
데이터베이스 스키마는 어떻게 생겼나요?
현재로서는 상당히 일반적인 다음 스키마를 저장할 수 있습니다. 데이터베이스 기술에 따라 데이터 유형과 크기가 변경될 수 있지만, 설계 검토자나 면접관에게 원하는 바를 잘 보여줄 수 있습니다. 필요한 경우 나중에 수정할 수 있습니다.
Collection Name: Locations
--------------------------
Filed(필드들):
------------
* id - int (4+ bytes)
* title - char (100 bytes)
* type - char (1 byte)
* description - char (1000 bytes)
* lat - double (8 bytes)
* long - double (8 bytes)
* timestamp - int (4-8 bytes)
* metadata - JSON (2000 bytes)
인터뷰 팁: 인터뷰에서 관계형 또는 비관계형 데이터베이스를 선택할지 여부는 항상 뜨거운 질문입니다. 많은 사람들이 읽기 부하가 높기 때문에 비관계형 데이터베이스가 여기에 잘 맞을 것이라고 맹목적으로 말합니다. 이것은 완전히 정답이 아닙니다. No-SQL은 마술처럼 확장되지 않습니다. 약간의 운영 부담이 있습니다. 일반적으로 좋은 기능인 애플리케이션 지정 키(application specified key)에 의한 샤딩 지원을 기본 제공합니다.
기술을 선택할 때 데이터가 데이터베이스 시스템에서 제공하는 데이터 모델에 맞는지, 데이터베이스 시스템이 얼마나 많은 커뮤니티 지원을 받는지, No-SQL의 경우 내부 파티셔닝 체계가 실제 환경에서 어떻게 작동하는지를 고려해야 합니다.
워크 로드 (작업 부하) 등 또는 사용 사례에 적합한지 확인합니다. 읽기 로드 또는 규모만 기준으로 데이터베이스를 결정하는 것은 논리적이지 않습니다. 매우 높은 규모의 시스템에서는 데이터베이스만 전체 로드를 처리하지 않는다는 점을 기억하세요.
이 글의 뒷부분에서 함께 로드를 공유하고 시스템을 구성하는 여러 가지 구성 요소를 볼 수 있습니다. 데이터 저장소는 그 일부일 뿐입니다. 또한 많은 대기업에서 많은 주요 사용 사례에 RDBMS를 사용합니다. 따라서 관계형 시스템이든 비관계형 시스템이든 관계없이 데이터베이스 기술이 기존 회사 인프라뿐만 아니라 사용 사례의 환경에 어떻게 적합한지 확인해야 합니다. 또한 비용 및 운영 우수성은 고려해야 할 매우 중요한 또 다른 요소입니다.
인터뷰 상황에서는 모든 사람이 RDBMS를 이해하고 있으므로, 나중에 목적에 맞는 적절한 기술을 선택할 것이라고 말하고, RDBMS로 가정하고 시작하셔도 됩니다.
High Level Design(고수준 설계)
이제 사용 사례(Use Case) 및 기대치, 추정에 대한 적절한 아이디어가 있으므로 이제 높은 수준의 설계를 도출 할수 있습니다.
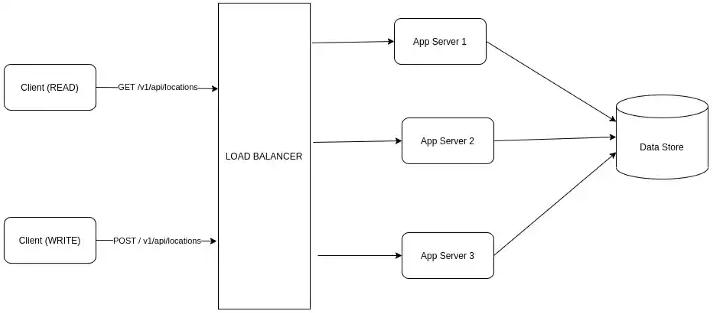
그림 1은 시스템의 가장 기본적인 HLD (고수준 설계)를 보여줍니다. 트래픽을 허용하는 Load Balancer(로드밸런서) 뒤에 배치된 애플리케이션 서버가 있습니다. 이러한 앱 서버는 API 정의와 함께 배포됩니다. API 구현은 데이터베이스에 연결하고, 결과를 가져오고, 응답을 형성하고 클라이언트에게 다시 반환합니다.
여기에 Load Balancer(로드밸런서)가 필요한 이유는 무엇인가요?
초당 50,000개의 읽기 쿼리를 처리해야 하므로 최악의 경우 모든 트래픽이 동일한 지역에서 오는 것을 고려하면 단일 서버에서 해당 부하를 관리하기 어려울 것입니다. 따라서 부하를 공유할 수 있는 상태 비저장 애플리케이션 서버가 필요합니다. 따라서 로드 밸런서가 필요합니다.
어떤 종류의 Load Balancer(로드밸런서)인가요? 하드웨어인가요? 소프트웨어인가요?
우리의 기존 인프라 및 비용 최적화 기술에 달려 있습니다. 소프트웨어 부하 분산 장치는 하드웨어 부하 분산 장치보다 비용이 적게 듭니다. 하드웨어 로드 밸런서는 특별한 하드웨어 요구 사항이 있을 수 있지만 , 소프트웨어 요구 사항보다 더 효율적이고 고급입니다. 그러나 아직 표준이나 선택 사항이 없는 경우 HAProxy와 같은 소프트웨어 로드 밸런서를 선택하는 것이 좋습니다.
AWS에서 서비스를 생성하는 경우 AWS 자체에서 프로비저닝된 HAProxy 로드 밸런서를 얻을 수 있습니다. 레이어 7 애플리케이션 로드 밸런서와 같은 정교한 로드 밸런서가 필요하지 않으며 단순히 레이어 4 또는 네트워크 로드 밸런서를 사용할 수 있습니다.
데이터베이스에 무엇을 넣어야 하나요?
API 정의에서 JSON 형식의 위치 개체 목록을 사용하는 것을 확인했습니다. 우리의 데이터베이스 스키마는 또한 API와 거의 일치하게 구성했습니다. 따라서 해당 위치 데이터를 데이터 저장소에 간단히 저장할 수 있습니다. -> 데이터 저장소에 저장하기 전에 해당 데이터에 대한 일부 유효성 검사, 변환 또는 비즈니스 논리 구현이 필요할 수 있습니다.
데이터베이스에서 무엇을 쿼리하고 있나요? 쿼리는 어떻게 동작하나요?
이것은 지금까지 다룬 질문 중, 가장 흥미롭고 까다로운 질문입니다. 우리는 단순히 데이터 저장소를 사용하고 있기 때문에 수행하는 쿼리는 사용하는 저장소에 따라 다릅니다. 데이터 저장소가 기본 지리적 위치 쿼리를 지원하는 경우 해당 쿼리를 작성하여 애플리케이션 로직에서 가까운 위치를 검색할 수 있습니다. 그러나 모든 데이터 저장소가 위치 쿼리(location query)를 지원하는 것은 아닙니다. MySQL과 같은 기존 RDMS 시스템은 기본 위치 쿼리(location query)를 지원하지 않습니다.
그럼에도 불구하고 우리는 초당 최소 50,000개의 읽기 쿼리를 지원하고 있기 때문에 대기(지연)시간이 200ms 이하라는 제약 조건으로 인해, 네트워크 또는 디스크 IO 병목 현상이 발생할 수도 있습니다. 그래서, 데이터 저장소에서 항상 검색을 수행하는 것은 사실상 불가능합니다.
또한 우리가 사용하는 데이터 저장소에 관계없이 위치 쿼리를 원활하게 관리할 수 있는 방식으로 시스템을 설계하는 것이 좋습니다. 이제 우리의 문제는 다음과 같습니다.
데이터 저장소가 규모가 커짐에 따라 많은 부하를 처리할 수 없는 상황에서도 (기본적으로 지원하지 않거나 지원하더라도) 위치를 검색 가능하게 만드는 방법은 무엇인가요?
위치 검색을 좀 더 쉽게 하기 위해 다양한 접근 방식에 대해 이야기해 봅시다.
접근 방법 1: 메모리에서 위치 및 검색을 캐싱 하기
우리의 초기 데이터 크기는 대략 240 GB이며 가까운 미래에 그 이상으로 600 GB로 커질 수 있습니다. 대규모 읽기 쿼리를 지원해야 하므로 적극적인 캐싱 전략을 수행해야 합니다. 그렇다면 어떻게 해야 할까요?
우리의 의도는 가능한 한 캐시를 쿼리하고 데이터베이스에 대한 부하를 줄이는 것입니다. 우선 캐시 머신의 메모리에 있는 240GB의 데이터를 모두 수용할 수 있나요?
네, 그렇게 할 수 있지만 비용에 따라 여러 대의 기계가 필요할 수 있습니다. 메모리 가 충분한 단일 시스템을 얻을 수 250+ Gigabytes있지만 비용 효율적이지 않을 수 있습니다. 그래서 우리는 각각 120 GB 메모리가 있는 2대의 캐시 머신을 가질 수 있고, 데이터를 2대의 머신에 나누어 배포할 수 있습니다.
캐시에 무엇을 저장하나요?
이 접근 방식에서는 모든 위치 쿼리에 대해 제공된 클라이언트(위도, 경도)와 모든 캐시 머신에 저장된 모든 위치 사이의 거리를 찾습니다.
모든 결과를 찾은 후 오름차순 거리 순서 및 고객이 제공한 기준(있는 경우)에 따라 위치 순위를 매깁니다. 이것은 기본적으로 무차별 대입 검색이며 완전히 메모리에서 수행하므로, 우리의 데이터베이스가 위치 쿼리를 지원하지 않는다면 데이터베이스에서 전체 작업을 수행하는 것보다 더 빠릅니다.
위치를 저장하는 형식은 중요하지 않습니다. 위치 ID를 키로 저장하고 위치 개체를 값으로 저장하거나 캐시가 개체 목록을 지원하는 경우, 위치 목록을 키로 저장하고 위치 목록 전체에서 검색할 수 있습니다.
캐시는 어떻게 로드되나요?
몇 분마다 실행되고 마지막 ID 또는 타임스탬프 이후 위치를 로드하는 예약된 작업을 수행할 수 있습니다. 이것은 실시간 프로세스가 아니므로 (POST 타입의) location API가 호출될 때 쓰기 경로도 위치 정보를 작성/업데이트하도록 할 수 있습니다.
다음 아키텍처에서 쓰기 경로에는 2단계가 있습니다. (아래 그림 2, 그림 3을 참고하세요)
1단계: 데이터베이스에 쓰기
2단계: 캐시에 쓰기
이제 쓰기를 순차적으로 실행할 수 있습니다. 데이터베이스가 정적 데이터에 대한 신뢰할 수 있는 소스이기 때문입니다. 먼저 데이터를 데이터베이스에 쓴 다음 캐시 클러스터에 써야 합니다.
다음 아키텍처에서 캐시 로더는 조정 프로세스 역할을 하는 백그라운드 프로세스입니다. 쓰기 경로의 2단계가 실패하는 경우 캐시 로더는 데이터가 누락되었음을 발견하므로 데이터를 씁니다. 데이터가 이미 존재하는 경우 메모리 내 개체의 타임스탬프에 따라 로더는 데이터를 업데이트할지 건너뛸지 결정할 수 있습니다. 데이터베이스에 더 많은 업데이트된 데이터/더 높은 타임스탬프가 있는 경우 캐시의 데이터를 업데이트합니다.
또한 캐쉬 로더는 "Follower 머신"에서 데이터를 읽습니다. 데이터베이스를 확장하는 방법일 뿐입니다. 모든 쓰기 작업은 "Leader"에서 발생하고 읽기 작업은 "Follow" 머신에서 발생합니다. 여기에는 트레이드오프가 있습니다. "Follower"는 "Leader"보다 몇 밀리초에서 몇 초 정도 늦게 데이터가 기록될 수 있습니다. 대부분의 실생활 사용 사례에서 동기식 복제가 아닌 비동기식 복제를 사용하기 때문입니다. 동기식 복제 속도가 느리기 때문입니다.
역자 주 - 동기식 복제 / 비동기식 복제라고 어렵게 표현을 했지만, 업계에서는 NRT- Near Real Time(실시간에 준하는) 복제를 하느냐, 아니면 Master - Slave에서 복제 중 Slave에 복제가 안될 경우 Rollback하게 엄격한 복제를 할지 고민을 해야 한다. MongoDB 같은 경우 WritingConcern을 이용해 Writing Level을 결정할 수 있다. 대부분은 성능적인 이슈로 NRT Replication을 사용한다.
캐시 머신을 분할하는 전략은 무엇인가요?
캐시 머신을 분할하는 많은 전략이 있지만 지금은 시스템을 더 단순하게 유지하고 캐시 머신이 완전히 채워지거나 임계값까지 채워질 때까지 캐시 머신을 계속 채우도록 하겠습니다. 기계가 가득 차면 다음 기계로 전환합니다.
캐시 시스템을 분할(partitioning)하는 전략은 무엇인가요?
캐시 머신을 분할하는 전략은 여러 가지가 있지만 지금은 시스템을 더 단순하게 유지하고 캐시 머신이 완전히 채워지거나 한계값까지 채워질 때까지 계속해서 캐시 머신을 채웁니다. 일단 하나의 머신(인스턴스)가 가득 차면 다음 머신으로 교체합니다.
이 전략에서 머신 전체의 캐시 로드가 불균형해질 것이라고 생각하지 않나요?
호텔/레스토랑 검색과 같은 시스템의 경우 매우 특정한 수의 레스토랑/호텔이 있고, 밤새 호텔/레스토랑 수가 갑자기 증가하거나 급증하지 않으므로 이 시스템이 잘 작동할 수 있습니다. 따라서 우리는 매우 상대적으로 정적인 양의 데이터를 가지고 있으며 이 데이터를 포함하기에 충분한 캐시 머신이 몇 개인지 이미 알고 있습니다.
캐시 로더 백그라운드에서 동작하는 프로세스와 쓰기 경로(를 저장한) 캐시를 사용함으로 우리의 모든 캐시 머신은 데이터는 궁극적으로 채워질 겁니다. 지속적으로 데이터가 증가하는 경우 어쨌든 두 기계는 결국 요청을 hit (Cache Hit - 캐시에 데이터가 있어 DB까지 안 가는 상황) 하는 상황으로 가게 될 겁니다. 또는 이후 모든 (거리를 계산한) 위치 정보의 요청을 처리하게 될 겁니다. 따라서 이러한 캐시 채우기 전략은 주어진 상황에서 잘 작동합니다.
동적 데이터(움직이는 물체)에 대한 캐시 파티셔닝을 최적화하는 방법은 다음편에서 보도록 하겠습니다.
캐시 클러스터를 쿼리하는 방법은 무엇인가요?
병렬 스레드를 사용하여 캐시 머신을 쿼리하고, 데이터를 독립적으로 처리하고, 결합하고 응답을 생성할 수 있습니다. 따라서 Divide & Conquer 전략은 그림 2와 같습니다.

이 시스템을 더 개선하기 위해 우리는 무엇을 해야 할까요? 우리는 모든 location(위치) 요청을 모든 캐시 머신을 통해서 쿼리를 하고 있습니다. 이것은 값비싼 방법이죠. 혹시 더 나은 방법이 있을까요?
다음 편에는 위치정보를 처리하기 위해 점진적으로 개선된 사례를 공유하도록 하겠습니다. 또한 흥미로운 다른 아키텍처 사례도 공유드리니 참고해 주세요!
✔️ Uber 아키텍처와 시스템 디자인
✔️ 트위터는 왜 모니터링 시스템을 다시 만들었나?