



*실전 Web Application 부하 테스트 - 1,2편 통합한 웹∙앱 부하테스트 성능 진단 및 컨설팅 안이 최신 업데이트 되었습니다.
아래 글에서 확인하실 수 있으며, 웹 부하테스트는 20page 부터 확인하시면 됩니다😀
실전 Web Application 부하 테스트 - 1, 2편 통합 본 보러가기
지난 포스트에서는 웹 어플리케이션의 부하 테스트를 하기 위한 개념과 종류에 대해서 설명하는 시간을 가졌습니다.
이번 포스트에서는 실전에서 부하 테스트를 하기위해 고려해야 하는 환경 구성과 부하 테스트 시나리오 구축법에 대해서 상세히 설명을 드리고자 합니다.

1.Load Testing (부하 발생) 도구 소개
부하를 발생시키는 도구로는 여러 가지 존재하지만 한국에서 인지도 있는 솔루션은 다음과 같습니다.
| 도구명 | 기능 | 특징 | 비고 |
|---|---|---|---|
| JMeter | * 아파치 프로젝트 * GUI/ Non-GUI 지원 * 분산 부하테스트 지원 |
* 오픈소스 부하테스트 점유율 1위 * 다양한 플러그인 지원 * 다양한 연동 서비스 존재 (Blazemeter, Azure등) *시나리오 기반 테스트 가능 *멀티 시나리오 지원 |
사용 예 |
| Load Runner | * MicroFocus제품 * 유료 * 부하량당 비용 증가 |
*다양한 프로토콜 지원 *다양한 운영체제 성능 모니터링 *시나리오 기반 테스트 |
사용 예 |
| nGrinder | *Grinder의 확장(네이버) | 스크립트 기반 테스트 분산 부하테스트 지원 *개별 트랜잭션별 성능 측정 |
사용 예 |
| Gatling | * 아파치 라이센스 * Akka,Netty 기반 * 분산 부하테스트 지원 |
* 단일머신으로 많은 부하 생성 * 오픈소스 부하테스트 점유율 2위 * 스크립트 기반 테스트 * 멀티 시나리오 지원 |
사용 예 |
각 도구 별로 사용 예를 클릭하시면, 제품의 특징이나 구성을 파악하실 수 있습니다.
국내에서는 고객사가 Jmeter, Load Runner를 선호하시는 상황입니다.
다만 Load Runner 같은 경우는 가상 유저가 늘어날 경우 비용이 기하 급수적으로 늘어나기 때문에, 대용량의 트랜잭션을 만들기 위해서는 Jmeter와 Cloud를 같이 쓰는것이 비용 효율적입니다.
해외에서는 Jmeter, Gatling, Load Runner가 주로 사용되고 있습니다.
2. 조직에 맞는 Load Testing (부하 발생) 도구 선별이 중요
부하 발생 도구를 도입하기 이전에 조직의 문화/환경/구성에 맞는 도구를 선정하는 것이 중요합니다.
별도의 QA 부서나 팀이 있다면 좋겠지만, 없다면 우리 조직에 맞는 현실적인 구성을 해야겠지요.
-
CI/CD와의 연동이 편한가?
Jenkins 같은 CI/CD 툴하고 쉽게 연동이 되어, 배포 이전에 쉽게 TPS나 성능 측정을 할수 있는가? -
학습과 트러블슈팅이 용이한가? 관리나 유지보수가 되는가?
자료가 많이 공유되어 있고, 도움을 받을 수 있는 커뮤니티가 구성되어 있는지?
끊임없이 제품을 유지보수하거나 관리가 되는 오픈소스 인지? -
부하 스크립트를 작성하는 주체는 누구인가? (개발자 vs 비 개발자)
개발자 : 스크립트 기반으로 높은 자율성을 가지고 개발이 가능한지? (Gatling)
비개발자 : GUI 툴로 뚝딱 만들 수 있는 도구를 선호 (Jmeter)
Gatling은 개발을 어느 정도 할수 있는 엔지니어가 사용할수 있습니다. 개발자 입장에서는 더 많은 자유도를 제공합니다.
Jmeter는 GUI 로 비개발자도 쉽게 접근할수 있고, 다양한 플러그인을 제공하고 있습니다. 다만 커스텀한 프로토콜 연동 테스트인 경우 개발이 들어가기도 합니다.
3. 부하 테스트의 첫 관문 - 시나리오 선택
부하 테스트 시 만나게 되는 첫 고민은 부하 시나리오를 어떻게 구성하는가입니다.

-
주요 시나리오 테스트
고객사와 협의하여 주요 시나리오 선정 후 (가입, 강좌 수강 등) 개별 시나리오 별로 얼마나 견디는지 테스트하는 방법 -
주요 시나리오 가중치 테스트
위 선정된 주요 시나리오에 가중치를 부여하는 테스트 방법
예) A 시나리오 20%, B 시나리오 30%, C 시나리오 50%
시나리오 별로 가중치를 다르게 해서, 여러 개의 시나리오를 동시에 던지는 방법 -
사용 빈도가 높은 Top N의 트랜잭션을 추출하여 테스트
APM과 같은 솔루션으로 트랜잭션의 빈도를 추출하여, 많이 호출되는 상위 트랜잭션을 20~30개를 뽑아내어 테스트 시나리오를 만드는 방법
이 중 가장 현실세계와 가까운 것은 2번째인 주요 시나리오 가중치 테스트입니다. 실제 예를 보도록 하죠.
시나리오가 많아질수록, 시나리오 별로 들어가는 다양한 파라미터 (로그인 시나리오 시 한 명이 아닌 1000명이 접속한다면 1000개의 ID, PW로 로그인하는 경우)들이 많아지면 많아질수록 시나리오 작성에는 더 많은 시간이 걸립니다.
정작 시나리오는 Blazemeter Chorme Plugin, BadBoys를 통해 금방 만들 수 있지만 데이터 생성 작업이 훨씬 오래 걸릴 때도 있습니다.
4. APM의 선택
부하를 발생시킨 후, 웹 어플리케이션의 주요 병목지점을 찾아내는 것이 중요합니다. 아픈 곳을 찾기 위해서는 MRI와 같은 도구와 나온 결과물을 보고 판단하는 의사가 필요하죠. 웹 어플리케이션의 병목을 찾아주는 MRI가 APM이라고 생각하면 됩니다. APM의 가장 대표적인 솔루션은 제니퍼소프트가 있습니다.
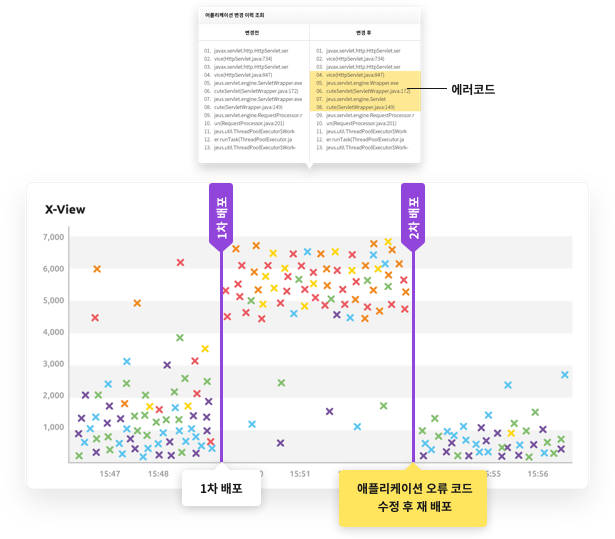
위 그림에서 보듯이 하나의 점이 개별 트랜잭션을 의미하며, Y축이 응답시간(서버에 머무른 시간)을 의미합니다. 즉 응답시간이 긴 트랜잭션을 Drag&Drop으로 선택하면, 다음과 같이 프로파일링 정보를 볼수 있습니다.
국내에서 많이 사용되는 APM은 다음과 같습니다.
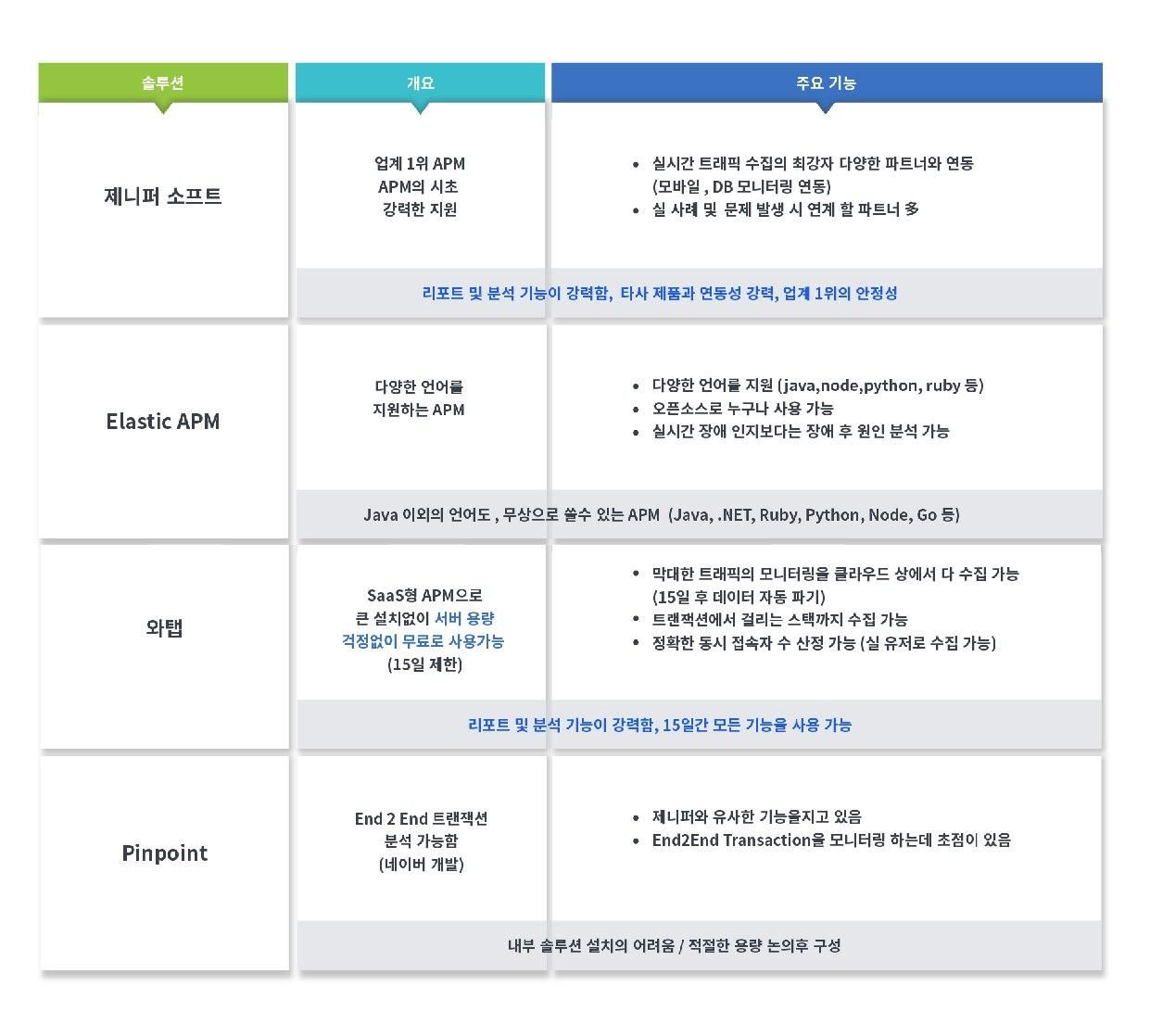
제니퍼가 국내 시장에서 점유율이 60%가 넘기 때문에, 고객 과반은 제니퍼소프트를 쓰신다고 보시면 됩니다. 이에 제니퍼 소프트 APM의 여러 화면과 성능 지표를 명확히 이해하시는 게 중요합니다. (오픈소스로 유사한 버전으로 Scouter가 있습니다.)
그리고 Elastic APM은 초 단위의 분석이 아닌 30초/ 1분 단위로 데이터를 수집하는 APM으로 무료이며, Java 이외에 다양한 언어(.NET, Go, Python, Ruby) 도 지원이 된다는 장점이 있습니다.
와탭의 제품은 SaaS형이라 고객사가 외부로 성능 데이터가 수집이 된다고 하면, 번거로운 절차 없이 Agent 설치 만으로 바로 결과를 확인할 수 있습니다.
5. 인프라 모니터링
개발 코드의 문제가 아닌, 자원이 부족해서 응답 지연 등이 발생할 수 있습니다. 또한 클라우드 환경으로 넘어오면서 (VM, Docker와 같은 가상 환경) 하나의 물리 머신에 자원을 공유하여 쓰면서 항상 일정한 성능을 낼 수 없는 상황이 되었습니다.
이에 코드의 병목이나 결함이 아닌, 자원이 부족해서 발생한 장애인지 판단을 하는 것이 중요합니다. 이에 운영체제에서 제공하는 여러 가지 지표를 읽을 수 있고 판단을 할 수 있어야 합니다.
상세한 내용은 클라우드 환경에서 시스템을 운영하기 위해 알아야 하는 것을 참고해 주세요. 핵심만 전달을 하자면 아래와 같습니다.
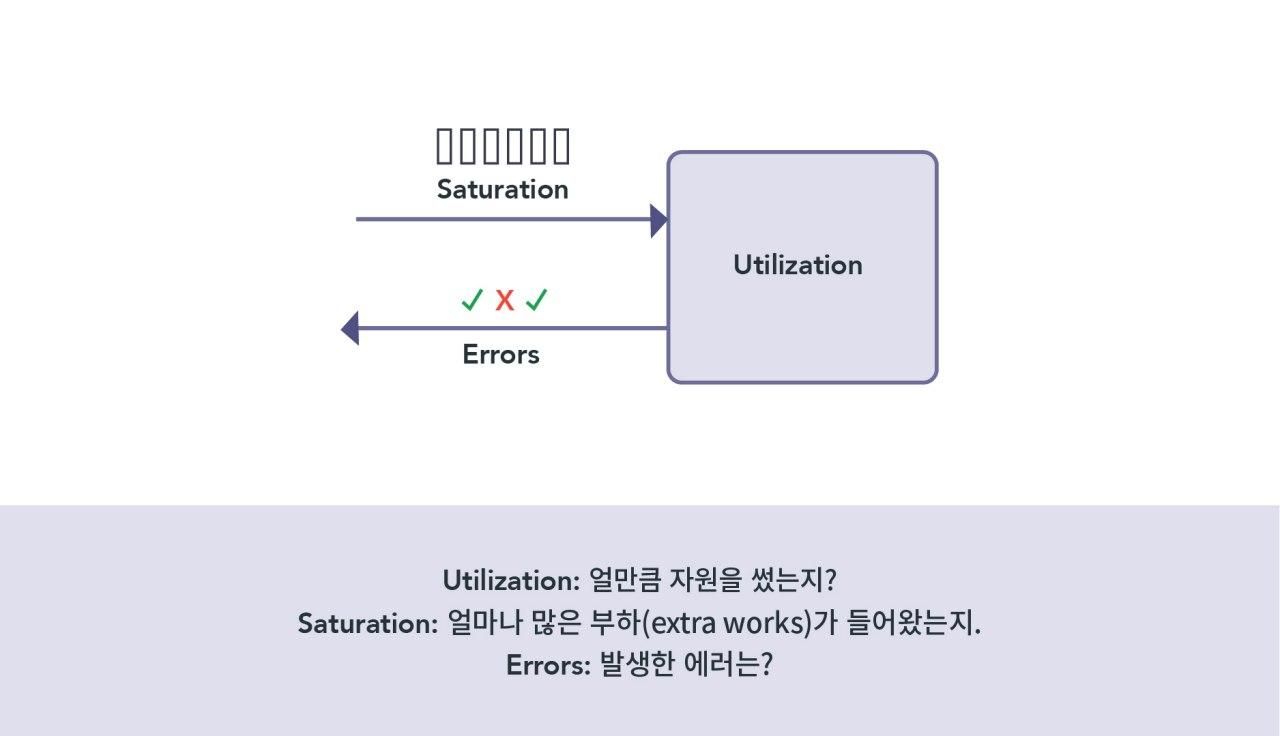
자원의 성능을 바라보는 기본적인 컨셉으로는USE 메서드를 추천드립니다. (이 방식은 Netflix의 성능 엔지니어로 근무하고 있는 brendan gregg의 아이디어)
CPU, Memory 사용률 (Utilization)이 100%를 다 쓴 건에 주목하지 말고 Utilization, Saturation, Error의 관점으로 자원 사용량을 바라보자는 이야기입니다.
- 얼마나 많은 부하(Saturation)가 들어와서
- 이러한 사용률(Utilization)이 나왔는지
- 문제가 발생했다면 에러(Error) 메시지들은 무엇인지
실제 와탭의 인프라 모니터링 화면을 보면 USE 메소드의 컨셉이 잘 반영되어 있습니다.
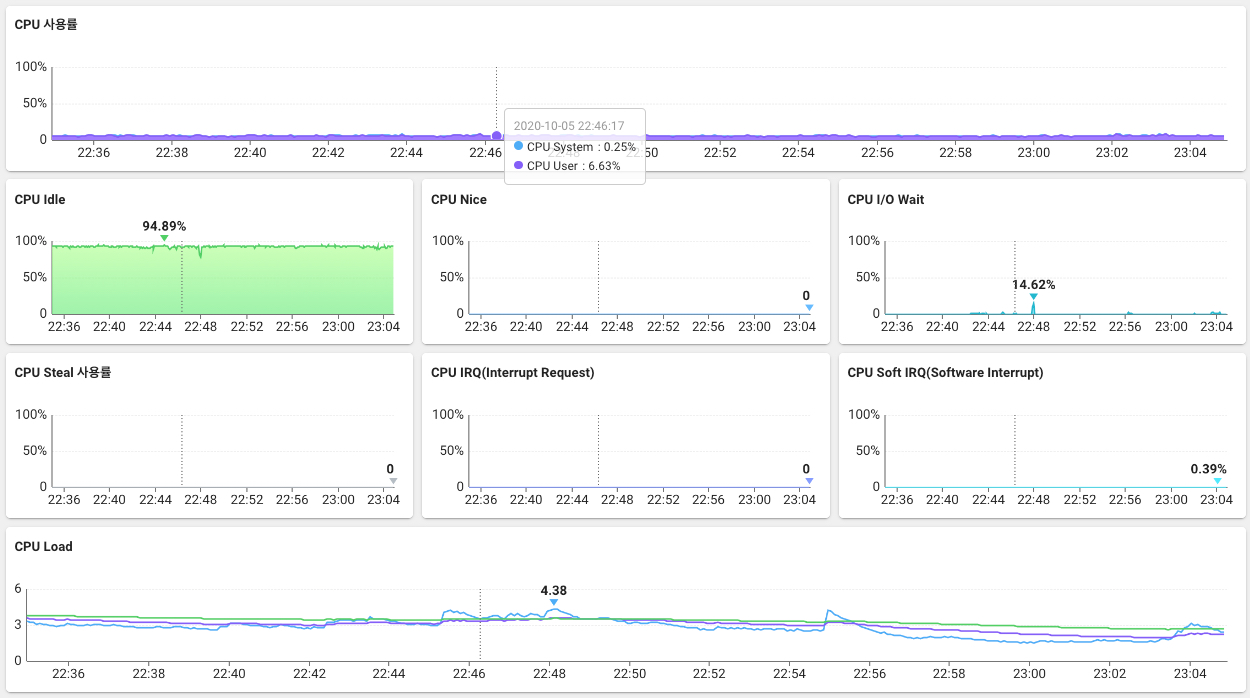
Use : CPU Usage (CPU 사용률 - 현재 CPU 자원을 얼마만큼 들어오는지)
Saturation : CPU Load (얼마만큼의 부하가 들어오는지 CPU 개수 이상의 숫자가 들어오는지)
Error : perf 명령어 또는 과도한 자원을 Process를 찾아 dump를 분석하는 형태로 진행해도 됨
추천하는 인프라 모니터링 툴은 다음과 같습니다.
무료 :
- Zabbix
- ELK Stack의 Beats를 이용해 구성
- Telegraf 스택과 Grafana로 구축
- 가비아 SMS (SaaS형 무료)
- 와탭 SMS (SaaS형 5개 서버 무료, 이후 유료 )
- NKIA (국내 1위의 서버 모니터링 업체)
- DataDog (해외 Cloud 환경의 SaaS 모니터링)
- New Relic Infrastructure 모니터링 (SaaS 1위의 모니터링 업체)
이것 역시 고객의 상황의 맞추어 사용하셔야 합니다. 이미 고객사에서 자체 SMS를 구축해 놓은 경우도 상당수이며, 지표가 부족한 경우 협의해서 적절한 지표를 추가해야 합니다. 또한 외부 보안 이슈가 없다면, SaaS를 이용하시는 게 설치의 번거로움을 줄일 수 있습니다.
결국 많은 지표로 많은 문제를 볼 수 있지만, 그것보다는 핵심적인 지표 몇 개로 대략적인 현상을 파악하고 더 드릴 다운해서 문제를 볼 수 있는 노하우와 경험이 필요합니다.
맺으며
부하 테스트 시 필요한 라이프 사이클에 대해 설명 드렸습니다. 다음에는 실 사례를 통해 장애 현상과 어떠한 상황을 판단해서 해결해야 하는지. 공유드리도록 하겠습니다.
서버 부하 테스트나 기술적인 문의는 아래로 주시면 답변드리겠습니다.


