

개요
헥사고날 아키텍처(Hexagonal Architecture)란 무엇일까요?
이번 포스팅 에서는, 헥사고날 아키텍처(Hexagonal Architecture, 육각형 아키텍처)에 대해서 알아보고 간단한 예제를 통해 실제로 어떻게 헥사고날 아키텍처를 적용 하는지에 대해서도 알아보도록 하겠습니다.
계층화 없는 코드 = 스파게티
먼저 헥사고날 아키텍처를 설명하기 전에, 제가 첫 프로젝트를 진행했을때의 이야기를 해보겠습니다.
제가 모 기관에서 안드로이드 APK 보안취약점 분석을 수행해주는 서비스를 진행했을때, 저는 모듈화나 아키텍처에 대한 개념이 거의 없었습니다.
그래서 저는 입력값 검증 로직, 실제 비즈니스 로직, 데이터베이스 저장 로직 들을 전부 컨트롤러에 해당하는 메소드에 몰아넣어서 작성 하였습니다.
사실 맨 처음에 개발을 할때는 코드가 몇 줄 되지 않아서 엄청나게 편했습니다.
하지만, 기능이 추가되고 요구사항이 늘어나면서 코드의 크기가 커지면서 점점 코드를 추가하는것이 더욱 힘들어졌습니다.
무엇보다도, 요구사항이 수정되는 경우 코드를 수정 및 추가하는것이 거의 불가능에 가까운 상황이 일어나게 되었습니다.
실제로, 파이프를 이용해서 외부 프로세스와 통신을 하여 결과값을 가져온 뒤, 비동기로 작업이 완료되었다고 알려주는 로직을 작성을 하려고 했지만 코드가 너무 복잡해져서 해당 로직을 추가하지 못하였습니다.
결국 최종발표때, 저희가 목표한 만큼의 퀄리티의 서비스를 만드는것에는 실패하였습니다.
보통 학부 1~2학년때 수행하는 프로젝트 또는 첫 개인프로젝트를 수행했을시, 위와 같은 상황을 겪은분들은 보통 아래와 같이 코드를 작성했을 것입니다.
const express = require('express')
const app = express()
const port = 3000
app.get('/', (req, res) => {
// 비즈니스로직, 입력값 검증, 데이터베이스 CRUD,
// 기타 스케쥴링 작업등 전부 여기 1개 메소드에 전부 작성해버리는 경우
// 거의 한 500~10000줄을 여기다가.........
})
app.listen(port, () => {
console.log(`Example app listening at <http://localhost>:${port}`)
})
결국, 위에서 언급한 상황과 같이 해당 코드는 프로젝트가 조금만 커지게 되어도, 코드에 손을 댈 수 없는 상황이 되어버리고 맙니다.
여담으로 위와 같은 코드의 패턴들을 보통 SmartUI 라는 이름의 안티패턴 으로 불리고 있습니다. 절대 현업 에서는 저렇게 코드를 작성하지 않기를 바랍니다.
또한, 저러한 안좋은 코드들을 보고 스파게티 코드라고 부르기도 합니다.
당연하게도, 저만 이런 문제를 겪었던것이 아닙니다. 몇십년전 부터 이미 수많은 프로그래머들이 소프트웨어의 위기라는 이름으로 이러한 문제에 대해 많은 고민을 하고 있었습니다.
이때, 사람들은 그 고민을 해결하기 위해 객체지향 프로그래밍(OOP) 이라는 패러다임을 도입하였습니다.
재미있는 것은, 객체지향 프로그래밍을 도입 하였음에도 이전보다는 생산성이 약간 늘기는 했지만, 생각 보다 재사용도 잘 되지 않았고, 유지보수도 여전히 힘들었습니다.
결국 객체지향이나 절차지향, 함수 지향 패러다임 이전에 보다 근본적인 원인을 해결하지 못한 것이지요.
과연 무엇이 원인 이었을까요? 바로 코드 의존성과 결합도 입니다. 즉, 코드 의존성(결합도)은 낮추고 응집성은 높여야 된다는 말입니다.
먼저, 코드 의존성(결합도)란 하나를 고치기 위해 수많은 코드를 뜯어 고쳐야 하는 상황 입니다.
글 맨 위에서 언급한 사례가 바로, 각 코드간의 의존성이 너무 높아서 코드를 수정하지 못하는 사례입니다.
그렇다면 코드 응집성(Code Cohesion) 이란 무엇일까요? 또 하나의 예시를 들어보도록 합시다.
프로젝트를 하는데, 역시나 이미 코드가 많이 짜여진 상태입니다.
다행히도 당신은 코드 의존성에 대한 개념을 알기 때문에, 모듈을 쪼개면서 개발을 하였습니다.
그러나 너무 코드를 잘게 쪼갠 나머지 단 200줄 짜리 프로그램인데 클래스가 한 40개정도가 되는 상황이 발생했습니다.
결국 당신은 겨우 수십줄의 코드를 고치기 위해 10개넘는 클래스를 돌아다니면서 일일히 다 뜯어 고쳐야 되는 상황이 발생했습니다.
위에서 나온 상황 같이 서로 유사한 역할을 하는 코드들은 같이 모아둬야 한다는 것이 바로 코드 응집성을 말하는 것입니다.
이러한 관계 없는 코드 의존성(결합도)을 낮추고 관계있는 코드간의 응집성을 높여서 재사용성과 유지보수, 개발의 생산성을 높이는 주요한 5가지 원칙이 존재합니다. 바로 할리우드 원칙과 SOLID원칙입니다.
할리우드 원칙은 단 한 문장으로 설명됩니다.
You don't call me, I'll call You(당신이 나를 부르는게 아니야, 내가 당신을 부르는 거지)
즉, 프로그램의 전체적인 제어 흐름을 사용자가 아닌 이미 뼈대 코드에 맡기는 것입니다.
이렇게 함으로써, 사용자는 이미 만들어진 흐름에 자기의 코드를 끼워 넣기만 하면 되기 때문에 뼈대 코드와 사용자의 역할이 분리가 되는것이지요.
또한, SOLID는 아래의 5가지 원칙을 말하는 것입니다.
- Single Responsibility Principle(단일 책임의 원칙)
- Open-Closed Principle(개방 폐쇄 원칙)
- Liskov's Principle(리스코프의 원리)
- Interface Segregation Principle(인터페이스 분리의 원칙)
- Dependancy Inversion Principle(의존성 역전의 법칙)
즉 요약하면, 한 모듈은 한가지의 일만 잘 해야하고, 기존 코드를 수정하지 않고 코드를 추가하는것이 두렵지 않아야 하고, 인터페이스로 역할을 분리하여 코드간의 의존성을 낮춰야 된다는 말입니다.
(사실 리스코프 원칙도 비슷한 관계, 즉 상속관계에 있는 객체 간에 있어서 부모 클래스 대신 자식 클래스로 대체해도 된다는 말이니 코드 유지보수에 결국 도움이 되는 원칙이지요.)
사실 객체지향 언어가 아닌 절차지향적 언어인 C로도 이러한 5가지 원칙과 할리우드 원칙을 잘 지켜서 프로그래밍 하고 있는 아주 거대한 프로젝트가 존재합니다. 바로 리눅스와 유닉스 커널 입니다.
아래가 리눅스 커널에서 C로 인터페이스를 구현한 예제입니다.
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iopoll)(struct kiocb *kiocb, bool spin);
....
};
그리고 실제 C로 프로그래밍 하는 사용자는 다음과 같이 프로그래밍 하면 됩니다.
#include<stdio.h>
#include <fcntl.h>
int main()
{
int fd, sz;
char *c = (char *) calloc(100, sizeof(char));
fd = open("foo.txt", O_RDONLY);
if (fd < 0) { perror("r1"); exit(1); }
sz = read(fd, c, 10);
printf("called read(% d, c, 10). returned that"
" %d bytes were read.\\n", fd, sz);
c[sz] = '\\0';
printf("Those bytes are as follows: % s\\n", c);
}
즉, 파일을 어떠한 방식으로(어떤 파일시스템을 쓰는지) 읽고 쓰는지 실제 사용자가 전혀 알지 못하더라도 이와 같은 추상화를 통해 역할을 분리 함으로써 여러가지 디바이스나 파일시스템에 대응해서 I/O 작업을 수행할 수 있는 겁니다.
이제, 이러한 분리(패키징) 방식에는 어떤 종류 들이 있는지 차근차근 알아보도록 합시다.
계층 기반 패키징
먼저, 가장 흔히 쓰이는 방식은 통칭 MVC 아키텍처 라고도 불리는 수평 계층형 아키텍처 입니다. 보통 아래와 같이 controller, model, view 와 같이 패키징을 해서 코드들을 분리합니다.
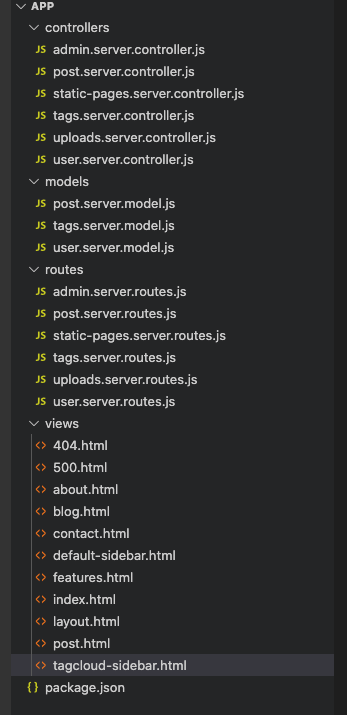
위의 사진에 나온 각 모듈 별 역할은 아래와 같습니다.
| 패키지(모듈) 이름 | 역할 |
|---|---|
| Controller | Model과 View를 이어주는 역할을 하는 코드들이 여기 위치함 |
| View | 비즈니스 로직과 데이터를 읽고 쓰는 코드들이 여기 위치함 |
| Model | 실제 사용자에게 입/출력을 받는 코드들이 여기 위치함 |
먼저 이러한 구조의 장점은, view, controller, model 이렇게 딱 3개로만 분리되기 때문에 소프트웨어의 규모가 작은 서비스의 경우 관리가 용이하다는 장점이 있습니다.
사실 계층 기반 패키징 항목에서 맨 처음 언급한 "계층 기반 패키징 = MVC" 라는 말은 엄밀히 말해서는 잘못된 말입니다.
엄밀히 말하면은 MVC 아키텍처가 계층 기반 패키징에 포함된다고 볼 수 있습니다. (일단 이해를 쉽게 하기위해 편의상 MVC = 계층 기반 패키징 이라고 설명했습니다.)
실제로도 "계층 기반 패키징" 은 보통 "Layered Architecture" 라고 불리고 있습니다.
굳이, Model, View, Controller 말고도 더 많은 방식으로 쪼갤 수 있습니다.
그 대표적인 예가 네트워크 시간에 지겹게 배우는 OSI 7계층 입니다.
하지만, 이러한 수평 계층 기반의 패키징 방식(아키텍처)은 소프트웨어가 커지고 복잡해지면, 잘게 모듈화 하기가 까다롭다는 단점이 존재합니다.
또한, 이러한 수평 계층 기반의 아키텍처는 업무 도메인을 구분할 수 있는 방법이 마땅치 않다는 단점이 있습니다.
그리고, 실제 모델 레이어에 비즈니스 로직이 작성되므로 데이터베이스(DB)와 비즈니스 로직이 강하게 결합되는 단점이 존재합니다.
즉, 전혀 다른 업무 도메인의 코드 라도, 코드 들을 계층형 아키텍처에 따라 작성하는 경우 무조건 view, controller, model 이 3가지 패키지에만 들어가버리기 때문에 해당 서비스가 어떤 도메인으로 구성 되었는지를 파악하는것이 까다롭다는 문제점이 존재합니다.
그렇다면 다른 좋은방법이 없을까요?
기능 기반 패키징
또 다른 방법으로는, 기능 기반 패키징 이라는 방법이 있습니다. 기능 기반 패키징은 서로 연관된 기능이나, 연관된 도메인 개념, 연관된 도메인들의 묶음(Aggregator Root) 을 기반으로 코드들을 패키징 해서 쪼개는 방법이 존재합니다.
보통 아래와 같이 패키징을 해서 코드를 분리합니다.
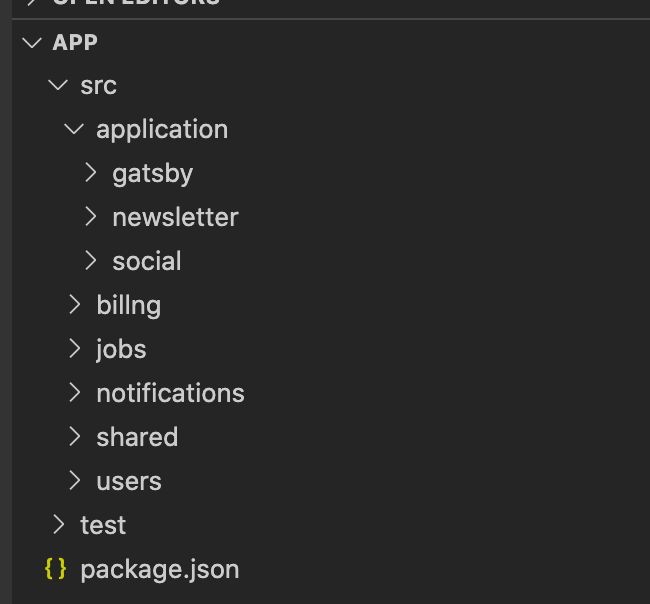
위의 사진에서 보다시피, 기능 기반 패키징은 관련된 도메인(쇼핑, 거래, 결제)나 비슷한 역할을 하는 코드들 끼리 패키징을 하는것을 알 수 있습니다.
실제로 이와 같이 관련된 도메인을 위주로 개발하는 DDD(Domain Driven Development) 라는 개발방식도 존재합니다.
하지만 기능 기반 패키징 같은 경우에는, 기술과 실제 비즈니스 로직의 분리 를 하기가 약간 까다롭습니다.
뭔가 위에서 언급한 수직적 계층화와 기능 기반 패키징의 장점만을 취한 방법이 존재할 것 같습니다.
과연 그러한 방법은 없는 것 일까요?
Port & Adapter, Hexagonal Architecture
좋습니다, 저희는 기술과 실제 비즈니스로직의 분리 와 각 도메인 별로 비즈니스로직 분리 라는 두마리의 토끼를 동시에 잡고 싶습니다.
이때, 헥사고날 아키텍처(Hexagonal architecture, a.k.a Port & Adapter)라는 아키텍처는 저희에게 좋은 해답이 되어 줄수 있습니다.
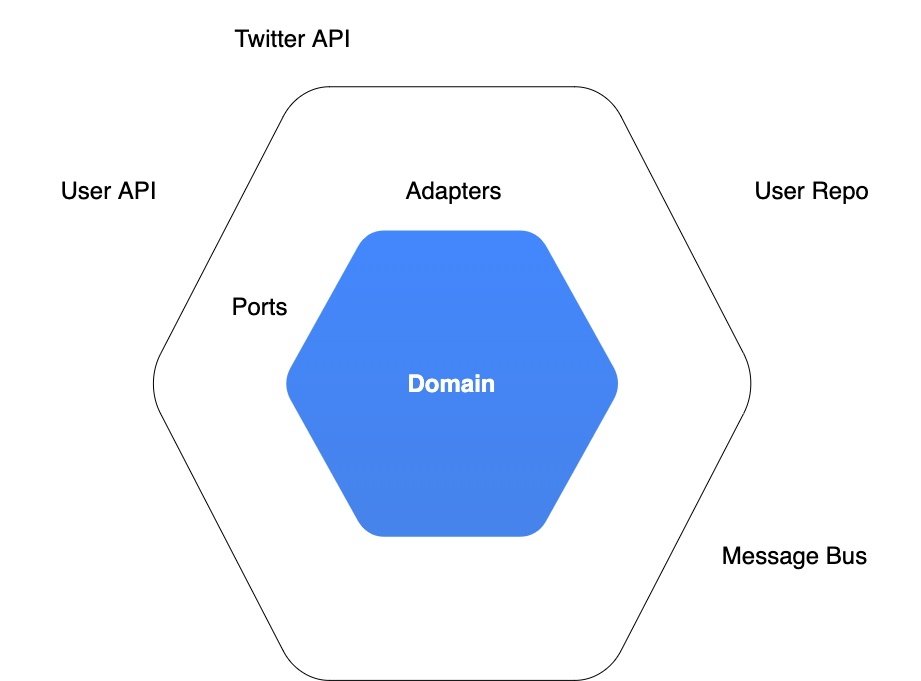
헥사고날 아키텍처의 원리는 간단합니다.
위 그림과 같이 실제 비즈니스 로직이 위치한 도메인 영역과 UI, 데이터 베이스, 입출력 코드와 같은 기술적인 세부사항을 다루는 인프라 영역의 2개 영역으로 나눕니다.
그런 뒤, 아래 2가지의 제약 조건을 지키게 코드를 작성해주면 됩니다.
- 도메인 영역 → 인프라 영역으로는 접근 가능 하지만, 반대로는 불가능 하게 구성 해야함
- 무조건 포트, 어댑터를 통해서만 도메인 영역에서 인프라 영역으로 접근하게 해야함
이렇게 아키텍처를 구성함으로써 느슨한 결합을 유지 할 수 있습니다.
즉, 데이터베이스가 변경되거나, REST API 에서 메시지 큐로 입출력 부분이 바뀌는 경우와 같이, 기술적인 세부사항이 변경 되더라도 기존 도메인 코드의 수정없이 인프라 코드를 추가해주고, 그에 따른 어댑터 및 포트만 구현을 해주면 바로 대응이 된다는 장점이 존재합니다.
따라서, 수직적 계층화와 기능 기반 패키지 아키텍처의 장점을 동시에 가져갈수 있다는 것입니다.
또한, 이전에 언급한 수직적 계층화의 단점인 데이터베이스와 비즈니스 로직이 강하게 결합되는 문제 또한 피할 수 있습니다.
헥사고날 아키텍처의 세부적인 구조는 아래 그림과 같이 이루어져 있습니다.
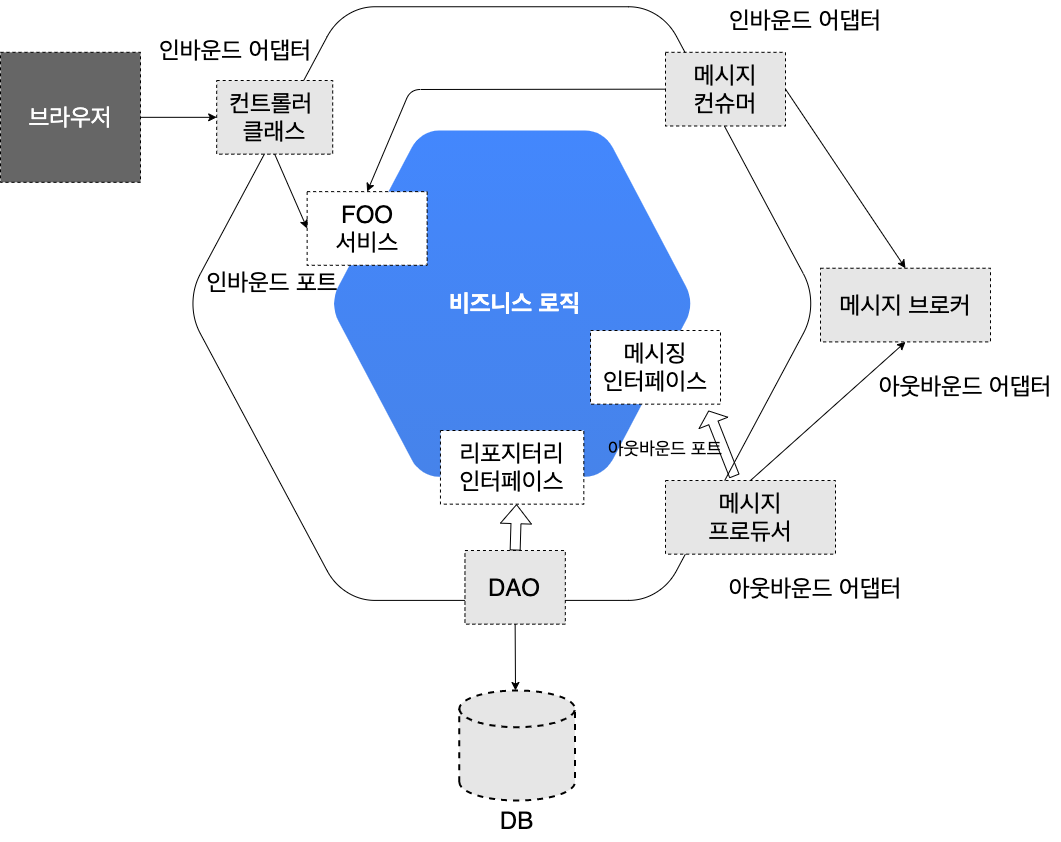
각 모듈 별 설명은 아래와 같습니다.
| 모듈명 | 설명 | 비고 |
|---|---|---|
| 인바운드 어댑터 | 외부에서 들어온 요청을 인바운드 포트를 호출해서 처리 | 예시 : Rest API Endpoint gRPC |
| 아웃바운드 어댑터 | 비즈니스 로직에서 들어온 요청을 외부 애플리케이션/서비스를 호출해서 처리 | 예시 : Database, ORM |
| 인바운드 포트 | 도메인 코드에 접근하기 위한 인터페이스 클래스 | 데이터 흐름 : Endpoint → Domain |
| 아웃바운드 포트 | 도메인 코드에 접근하기 위한 인터페이스 클래스 | 데이터 흐름 : Domain → outbound Adapter |
| 서비스 | 실제 도메인 내용을 처리하는 코드 |
위의 그림과 같이 보통 육각형 안쪽에 도메인 과 관련된 비즈니스 로직이 들어가고, 육각형 바깥에 도메인과 상관이 없는 인프라 코드가 들어가게 됩니다.
또한, 위에서 설명 하였듯이, 포트와 어댑터를 통해서만 인프라 코드에 접근 가능합니다. 그리고, 경우에 따라서 포트 및 어댑터를 인바운드, 아웃바운드로 구분해서 구현을 하기도 합니다.
그럼 이제 실제로 IMQA 서비스에서 헥사고날 아키텍처(Hexagonal Architecture)를 어떻게 적용했는지 확인을 해보도록 하겠습니다.
실제 적용 사례
저희 서비스의 패키징 구조는 아래와 같이 구성되어 있습니다.
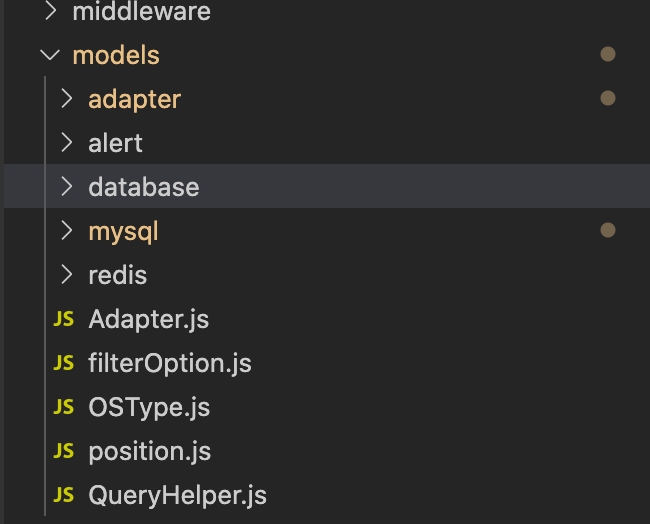
각 모듈 별 역할은 아래 표와 같습니다.
| 패키지(모듈) 이름 | 설명 |
|---|---|
| adapter | 각 구현체를 연결시켜주는 어댑터 |
| model | 데이터 I/O를 담당하는 부분 |
| model/database | 각 데이터베이스 별로 사용되는 인터페이스의 구현체 |
| model/mysql | MySQL 구현체 |
| model/redis | Redis 구현체 |
실제 코드는 아래와 같이 구현 되어 있습니다.
const DBManager = require('../database/DBManager');
const Model = require('../database/Model')
module.exports = class AlertModelAdapter extends Model {
constructor(dbType) {
super();
switch(dbType) {
case DBManager.MYSQL:
this.model = require('../mysql/alertModel')
break;
default:
this.model = require('../mysql/alertModel')
}
}
getModel() {
return this.model;
}
}
const filterOption = require("../filterOption");
const shardControl = require("../../store/shard");
const dbSelector = require("../database/dbSelector");
const alertModel = {
addProject: function(context, { db = dbSelector.getManageDB(), project }) {
return new Promise((resolved, rejected) => {
let queryString = `INSERT IGNORE INTO .........`;
const queryValue = [db, project.package_id, project.project_name];
.....
});
});
},
위와 같이 아키텍처를 구성함으로써, 데이터베이스의 종류가 추가 되더라도 기존 코드를 거의 변경하지 않고도 다른 데이터베이스에 대응이 가능하다는 장점이 존재합니다.
헥사고날 아키텍처(Hexagonal Architecture)란 무엇인지 알아보고, 간단한 사례를 통해 어떻게 IMQA에 적용했는지 정리해 보았습니다.
지금까지 포스팅 읽어주셔서 감사합니다.
출처
클린 아키텍처, 로버트.마틴.C
- Get Your Hands Dirty on Clean Architecture, Tom Hombergs
- https://semtax.tistory.com/22?category=804335
- https://velog.io/@labyu/MSA-2
- https://semtax.tistory.com/96
IMQA와 관련하여 궁금하신 사항은 언제든 아래 연락처로 문의해 주시면 상세히 안내해 드리겠습니다. 이미지를 클릭하시면 1:1 채팅 창으로 이동합니다.
- 02-6395-7730
- support@imqa.io


