안녕하세요. IMQA 백앤드 개발자 최경운입니다.
IMQA에서는 매일, 매 시간 수많은 데이터를 저장하고 있습니다. 데이터를 저장하는 것도 중요하지만, 그 안에서 사용자에게 의미 있는 값을 전달하기 위해서 다양한 지푯값을 제공하고 있습니다.
처음 지푯값을 구할 때는 그냥 구하면 되는 거 아닌가, 라는 생각이 들었습니다. 하지만 수많은 값 중 의미 있는 지푯값을 구하는 과정과 하나의 지푯값을 추출하기까지 확인했던 부분들을 공유해 보려고 합니다.
누구나 빠지기 쉬운 ‘평균의 함정’
모니터링 시스템에서는 수많은 데이터가 매초 발생합니다. 이런 데이터들이 의미 없이 나열되는 것은 의미가 없습니다. 그래서 이런 데이터들을 잘 보기 위해서 자료들을 대표하는 어떤 값이 필요하게 되는데 이를 '대푯값'이라고 합니다.
대푯값은 주어진 데이터의 중심을 대표하는 값으로, 평균, 중앙값, 최빈값 등이 있습니다.
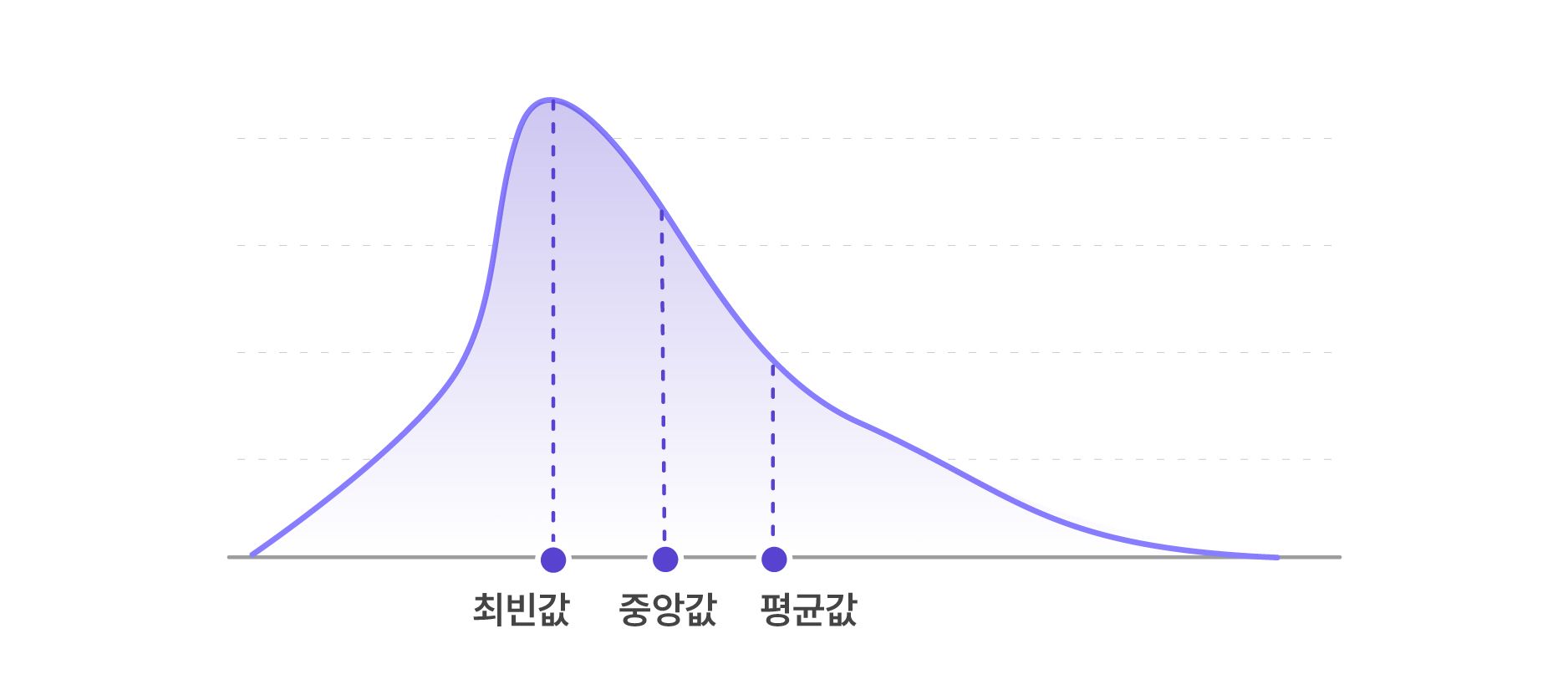
각각의 대푯값들은 다양한 정보를 제공해 줍니다. 평균값은 데이터값의 합을 데이터 개수로 나눈 값입니다. 평균은 자료 전체의 경향을 나타내는 값으로 이용됩니다. 하지만 특별한 이상치가 있는 경우에는 평균이 유의미한 값을 전달하기 어렵습니다.
<예시>
- 전체 데이터 수: 100개
- 95 건의 데이터 값: 1ms
- 5건의 데이터 값: 1,000ms
위와 같은 예시 상황에서 평균값은 ((1*95) + (5*1000))/100 = 50ms로 유의미한 지푯값을 제공해 주지 못합니다.
평균값도 필요한 값이지만 다른 ‘특별한 이상치’가 있을 때 볼 수 있는 지푯값도 필요해 보입니다.
백분위수(percentile)란?
대푯값들 중 성능 모니터링에서 빠질 수 없는 값이 있습니다. 바로 백분위수(percentile) 입니다. 백분위수는 데이터를 크기순으로 나열했을 때, 해당 위치에 있는 값을 의미합니다. 제 96 백분위수는 데이터의 96번 째 값을 의미하는 것이죠. 백분위수는 데이터의 분포를 파악하는 데 유용한 지표 중 하나입니다.
<예시>
- 전체 데이터 수: 100개
- 95 건의 데이터 값: 1ms
- 5건의 데이터 값: 1,000ms
앞서 든 예시 상황에서 96% 값을 나타낸다면 96번째의 값인 1,000ms가 될 것입니다. 평균값인 50ms 과 차이 나는 것을 확인할 수 있습니다.
특히 특정 성능 모니터링 시스템에서 이 값은 필수적입니다. 위의 예시에서는 100건이었지만 모니터링 시스템에서는 데이터가 매우 많고, 이 중 많은 요청이 대부분 정상이고, 아주 소수의 데이터만 문제를 일으키는 경우가 있습니다. 이런 경우 평균의 함정에 빠지지 않고 백분위수로 데이터를 확인하는 것이 효과적입니다.
백분위수를 구하는 건 쉽지 않다
하지만 이렇게 유용한 지표인 백분위수를 구하는 것은 쉽지 않은 일입니다. 백분위수를 구할 때는 다음과 같은 순서로 구하게 됩니다.
- 모집단이 되는 값을 수집한다.
- 정렬한다.
- 백분위수에 맞는 값을 추출한다.
이렇게 3가지 단계로 계산합니다. 위 순서에서 가장 많이 시간이 걸리는 부분은 값을 정렬하는 부분입니다. 데이터가 100건이라면 금방 처리되었겠지만, 모집단이 늘어나면 늘어날수록 정렬 속도는 느려지게 됩니다.
또한 최댓값이나 최솟값을 구하는 것은 분할 계산이 가능하지만, 백분위수는 분할 계산을 할 수 없습니다.
예를 들어 100개 값 중에 최댓값을 구한다고 하면 50개씩 나눠서 계산하고, 최종으로 나온 두 개의 값만 비교하면 됩니다.
ex) 최댓값 비교시
∙ A = {1,2,3,….49,50}
∙ B = {501, 502,…. 550}
- A에서 나온 50, B에서 나온 550을 서로 비교
- B에 있는 값들이 {601, 602,…. 650} 으로 바뀌면..?
- A에서 나온 50, B에서 나온 650을 비교하면 됨
- A에서 나온 값을 다시 계산할 필요 없음하지만 백분위수는 50개씩 나눠서 계산한다고 했을 때, 추가로 들어오는 50개의 값에 따라 50% 값은 25가 될 수도 있고 1,000이 될 수도 있습니다.
ex) 50% 값 구할시
∙ A = {1,2,3,….49,50}
∙ B = {501, 502,…. 550}
- A에서 나온 50%값은 25, B에서 나온 50%값은 525
- 두 집합의 50%의 평균(550/2) = 275
- 두 집합의 50% = 501위에서 보는것처럼 두 집합의 50%의 평균과 전체 집합의 50%는 서로 다르며, 분할 계산이 불가능합니다. 또한 B에 있는 값들이 {61, 62, 63, …. 110} 으로 바뀌면 A에서 나온 값을 다시 계산해야 합니다.
따라서 백분위수는
→ 전체 값이 다 있어야 계산을 할 수 있다.
→ 미리미리 계산할 수 없다.
모니터링 시스템에서는 많은 양의 데이터가 실시간으로 생성됩니다. 여기서 백분위수를 구하기 위해서 모든 데이터를 저장하고 처리하기가 어렵고 비효율적입니다. 또한 미리 계산할 수도 없어서 해당 지표를 구하기 위해 많은 시간이 처리됩니다.
제가 소개할 DD-Sketch는 이러한 문제를 해결하기 위해, 데이터를 추정하는 기술입니다. 데이터 스트림의 요약 정보를 유지하면서도 상대 오차를 컨트롤할 수 있는 방법을 제공합니다.
DD-Sketch는 (Distribution Data Sketch)?
거대한 데이터의 백분위수를 추정하는 기술은 HDR Histogram이 대표적으로 사용되어 왔습니다. 흔히 사진을 찍을때, 너무 밝게 찍히거나, 어둡게 찍힌 이미지를 보정하는 기술로 사용되고 있습니다
HDR (High Dynamic Range) Histogram은 사전에 min - max의 범위 (최소-최대값)를 알때 사용 할수 있으며, Bucket 사이즈를 정규분포에 가깝게 나누어 빠르게 추정하는 기술로 사용을 했습니다 .
DD-Sketch (Distribution Data Sketch or Data Dog Sketch)는
- 범위를 모를때 , 즉 최소, 최대값을 모를때도 사용이 가능하며,
- 데이터의 범위를 나누어 , 병렬적으로 수행하여, 빠르게 데이터의 백분위를 추정
하는 기술입니다.
주어진 데이터를 일정한 크기의 버킷으로 나누고, 각 버킷에 값을 저장합니다. 값은 상대 또는 절대 오차를 사용하여 저장하고 알고리즘이 오차를 조절할 수 있습니다.
데이터의 추가 및 집계 과정에서 메모리 사용량을 최적화하기 위해 동적으로 버킷의 크기를 조정합니다.
DD-Sketch 기본 원리
DD-Sketch에서 insert 하는 알고리즘입니다. 정확한 이해를 위해 논문에 일부를 첨부합니다.
(아래 내용 및 수식, 일부 이미지는 논문에서 참고, 발췌하였습니다. 해당 논문에 대한 정보는 하단에서 확인하실 수 있습니다.)

간단 용어 설명을 하자면 다음과 같습니다.
- B(버킷) : 일정한 크기로 나누어진 구간을 의미하고 특정한 값의 개수를 세는 역할
- α(accurate) : 상대적 오차를 결정하는 매개변수
- γ(감마) : 상대오차를 고려하여 값 범위를 조정하기 위해 사용
x를 insert 할 때,
1. 아래 식으로 index를 구합니다.
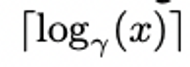
2. index를 구하기 위한 γ(감마)는 (1+α)/(1−α) 수식으로 구합니다.
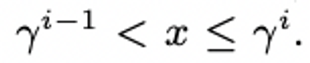
3. 버킷에 해당하는 index에 count +1 합니다.
한 줄로 요약하자면 임의의 구간으로 나눠서 버킷이라는 곳에 count를 저장합니다. 아래 그림으로 보면 100ms에 3건, 102ms에 2건 이렇게 저장될 것입니다.
이렇게 버킷으로 나누게 되면 정렬을 수행하지 않고도 빠른 집계 결과를 제공합니다. 이는 대용량 데이터의 실시간 분석에 유용합니다. 또한 버킷으로 구간을 나누었기 때문에 구간이 동일한 버킷의 count를 더하는 원리로 분할 계산(mergeable)이 가능해집니다.
sketch는 사용자의 상황에 따라서 정확도를 조절할 수 있게끔 파라미터를 제공합니다. 이 정확도 파라미터는 메모리 사용량과 비례합니다. 정확도가 올라가면 메모리 사용량이 올라갑니다.
다양한 Sketch 알고리즘의 특성
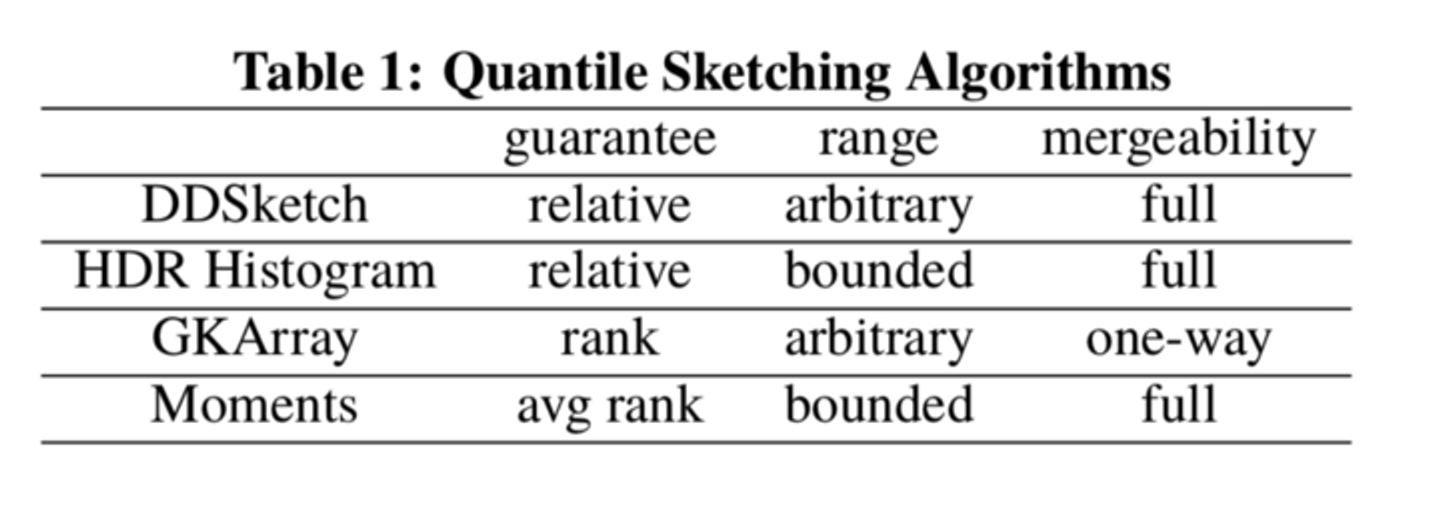
Sketch에는 각각 상황에 따라 선택할 수 있는 알고리즘이 있습니다. 단순 백분위수를 구하는데 어느 것이 이 특이점을 만들어 내는지 확인해 보겠습니다.
Guarantee - 보장
Sketch 알고리즘은 Rank-error(순위에러)라는 것을 사용합니다. Rank-error(순위에러)라는 것을 사용합니다. Rank-error는 보장을 1퍼센트로 잡았을 때, 95번째의 백분위수를 구한다면 94번째에서 96번째를 보장해 줍니다.
하지만 이런 보증은 유용하지 않습니다. 왜 유용하지 않을까요?
백분위수를 보통 응답시간에 대해 많이 쓰는데 응답시간 대부분은 1초 안으로 측정이 됩니다. 하지만 문제가 되는 응답시간은 몇십초가 걸리고 몇분이 걸리는 경우도 있습니다. 그래프를 그려보면 아래처럼 파레토 분포를 따릅니다.
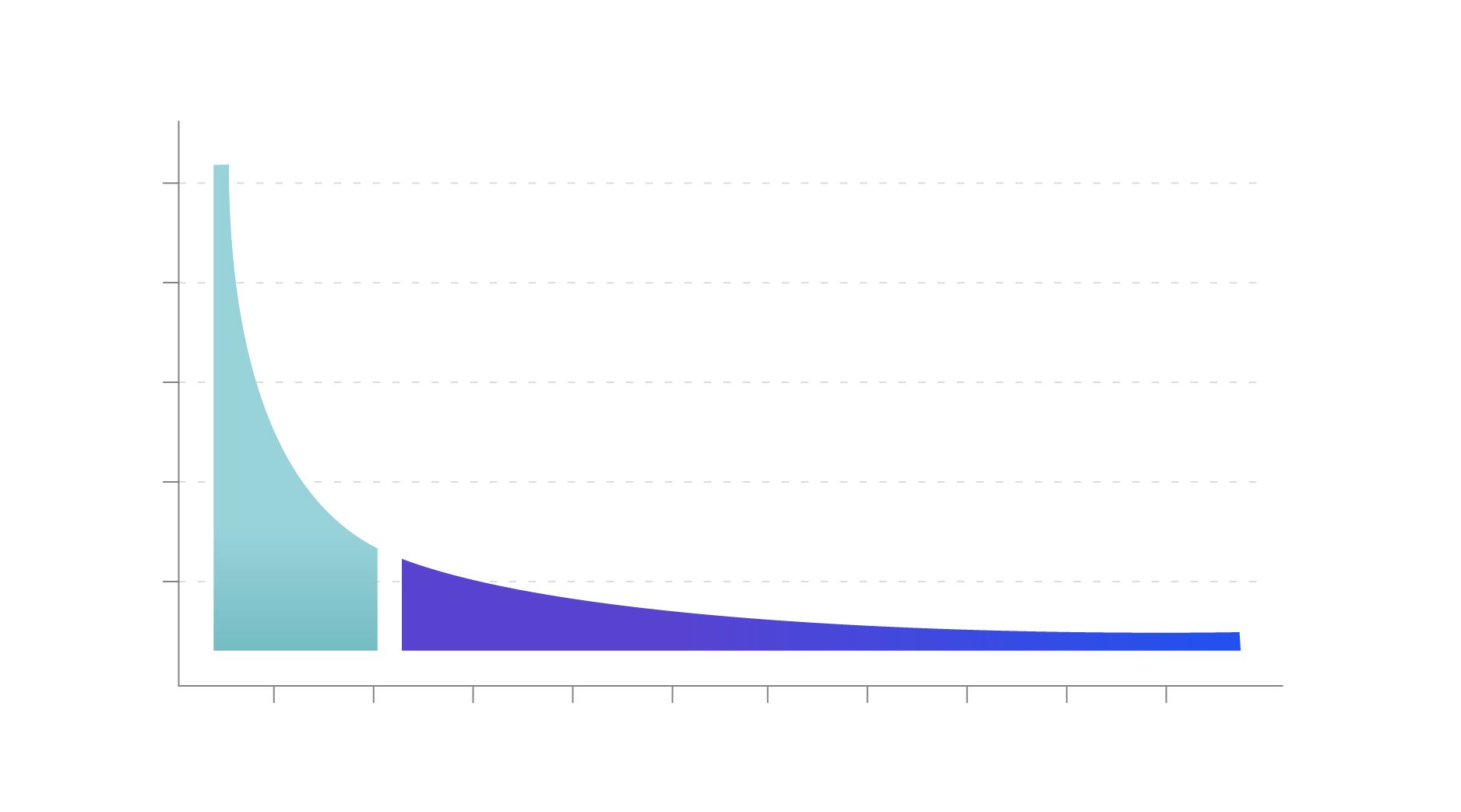
응답시간은 아래처럼 짧은 부분에서 대부분을 처리하고 시간이 지날수록 처리 속도가 늘어납니다. 아래 예시를 통해 살펴볼까요?
<예시>
∙ 조건: 95번 째의 데이터를 가져, 2퍼센트의 보증율
→ 93~97번째 값을 가져옴문제는 모니터링 시스템에서 느린 부분은 긴 꼬리처럼 파레토 분포를 따르고 있어서 93번째~97번째의 값이 드라마틱하게 달라집니다. 그래서 DD-Sketch가 사용하는 Relative-error를 사용하면 더 정확하게 값을 얻을 수 있습니다.
∙ 조건 : 95번째의 데이터를 가져옴, 2퍼센트의 보증율
→ 95번 째의 값이 1초라고 할때
→ 0.98초 ~ 1.02초 사이를 보장다음 그림은 Rank Error와 Relative Error의 정확성의 값을 비교한 자료입니다. P50과 P75에서는 큰 차이를 보이지 않지만, 파레토 법칙에 따라 값이 클수록 노란색과 파란색(Relative Error Sketch)의 선이 일치하는것을 확인할 수 있습니다.
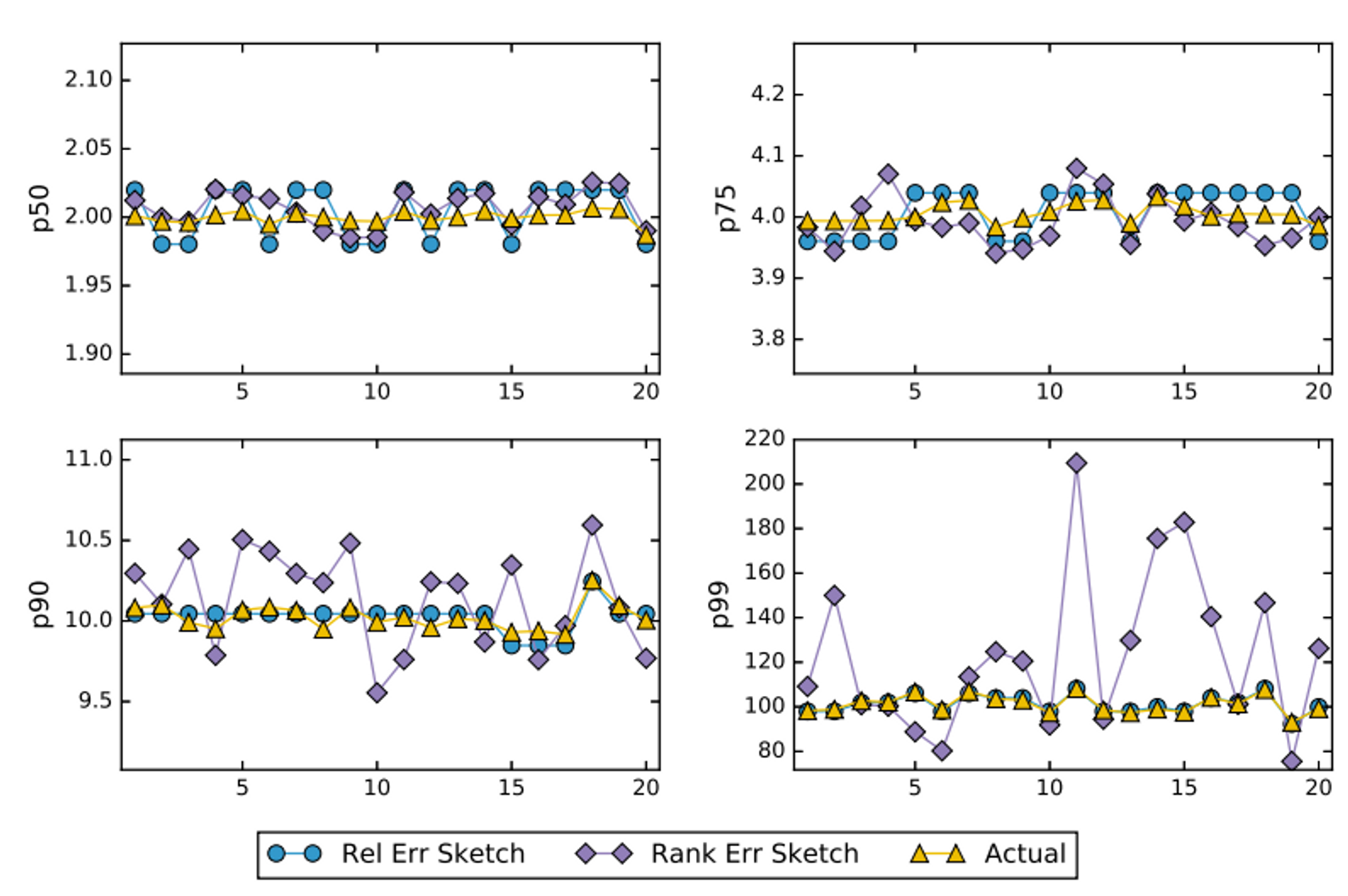
Relative-Error는 추후 나올 테스트 코드에서 중요한 파라미터로 쓰입니다.
Range - 범위
DD-Sketch 와 HDR Histogram 과의 가장 큰 차이점은 Range입니다. HDR Histogram은 Range Bounded이고 DD-Sketch는 Range Arbitrary입니다.
Range Bounded는 최솟값과 최댓값으로 제한된 범위를 가지는 것을 의미합니다. 숫자가 1부터 100 사이에 있어야 한다면, 해당 값의 범위는 1과 100 사이라는 제한이 있습니다. 100에 범위를 벗어난 값은 무시합니다.
특정 범위를 넘어서는 값들은 저장하지 않으므로 메모리 사용량을 줄이고 기록 속도를 빠르게 만들 수 있고, 이는 특정 범위에 대한 히스토그램을 작성하는 데 적합합니다.
Range Arbitrary는 데이터의 최소값과 최대값에 대한 범위를 정적으로 정의하지 않고, 데이터를 저장하는 과정에서 동적으로 범위를 조정합니다. 모니터링 시스템에서 자주 발생하는 드물게 발생하는 큰 값(특정 상황에서의 응답속도 분포)에 대해서도 처리할 수 있도록 설계되었습니다.
테스트 코드
이제 코드를 통해서 살펴보겠습니다. 해당 테스트는 라이브러리 안에 있는 테스트 코드에 테스트하기 편하게 조금 수정을 했고 사전 작업은 다음과 같습니다.
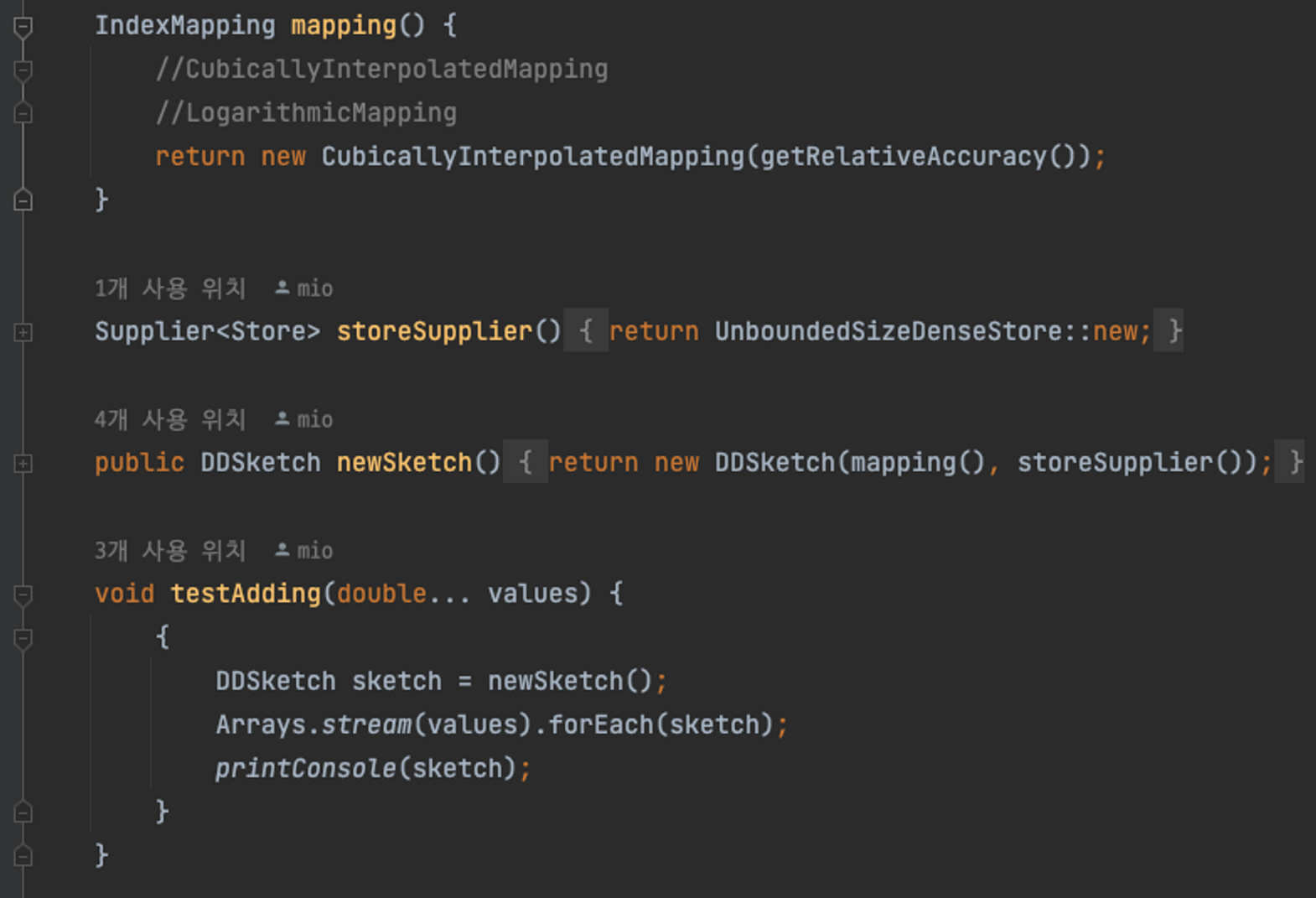
테스트 코드에서는 새로운 DD-Sketch 객체의 생성자로 indexMapping과 Store를 받습니다. 이 두 가지 인터페이스는 다양한 구현체를 가지고 있습니다.
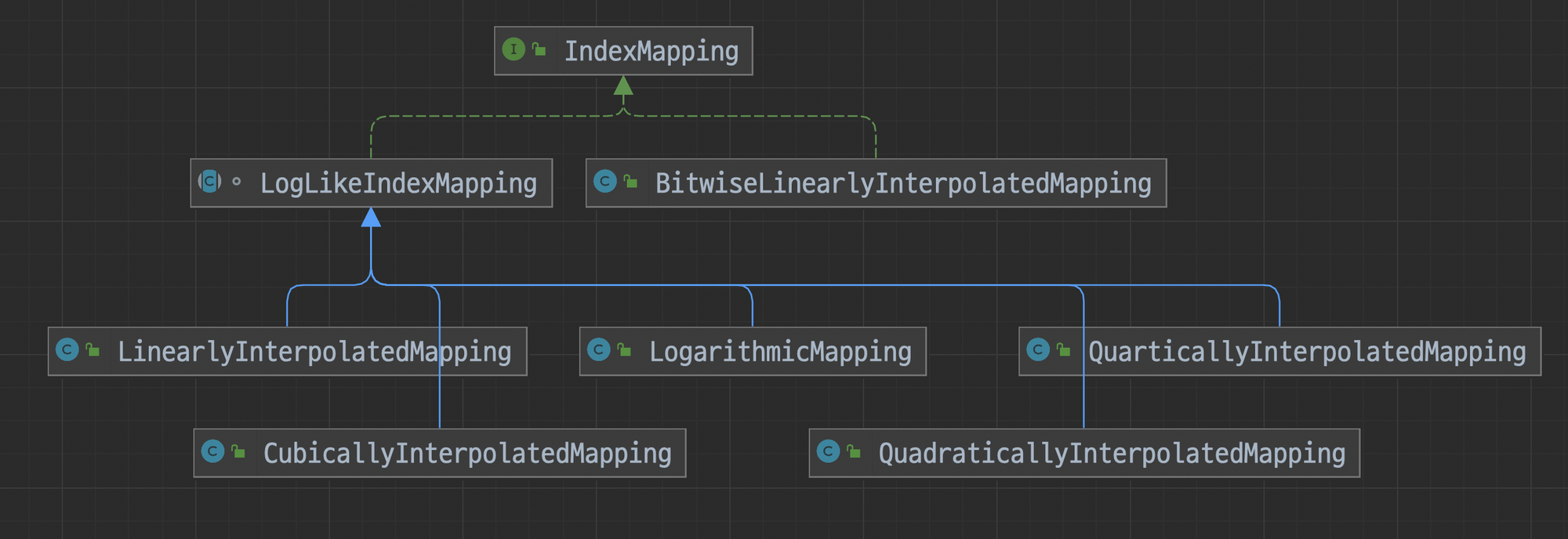
IndexMapping의 원리
DD-Sketch 라이브러리에서는 여러 가지의 IndexMapping을 지원하는데 스케치의 상대적 정확도와 속도에 따라서 사용자는 indexMapping을 선택할 수 있습니다. indexMapping의 종류와 특징은 아래와 같으며, 이 중 제가 선택한 방법은 CubicallyInterpolatedMapping입니다.
- LogarithmicMapping을 사용하는 것이 가장 정확하나 로그를 계산하는 데 비용이 많이 들기 때문에 로그를 근사화해서 하는 방법이 효율적입니다.
- CubicallyInterpolatedMapping(삼차보간법)은 로그 매핑에 비해 메모리 오버헤드가 1%에 불과하고 로그 매핑보다 약 6배 빠르기 때문에 좋은 대안입니다. 아래 LinearlyInterpolatedMapping(선형보간법)에 비해 CubicallyInterpolatedMapping이 더 빠르고 메모리 사용성은 얼마 차이 나지 않습니다. 정확도에서 CubicallyInterpolatedMapping가 더 효율적이라 해당 구현체를 선택했습니다. 참고로 선형 보간법과 삼차 보간법은 수학적인 보간(interpolation) 기법으로, 주어진 데이터 포인트들 사이에서 누락된 값을 추정하는 데 사용됩니다.
- LinearlyInterpolatedMapping은 두 개의 인접한 데이터 포인트 사이에서 선형 방정식을 사용하여 누락된 값을 추정하는 방법입니다. 간단하고 빠르지만, 데이터 포인트 간에 선형적인 관계를 가정하기 때문에 곡선 형태의 데이터에는 정확한 결과를 얻기 어렵습니다.
- CubicallyInterpolatedMapping은 세 개의 인접한 데이터 포인트를 사용하여 누락된 값을 추정하는 방법입니다. 이 방법은 보간 함수를 이용하여 주어진 데이터 포인트들을 정확히 통과하는 곡선을 생성합니다. 삼차보간법은 더 정확한 결과를 제공할 수 있으며, 데이터 포인트 간의 곡선 관계를 더 잘 반영할 수 있습니다. 두 구현체는 선과 곡선에서 정확도 차이가 발생하게 됩니다.
IndexMapping에 다양한 구현체
다음 표는 LogarithmicMapping 매핑의 대안으로 쓸 수 있는 구현체 IndexMapping을 보여줍니다.

구현체 안에서 실질적인 차이점은 아래와 같습니다.
대표적으로 LogarithmicMapping은 log를 e로 계산하지만, CubicallyInterpolatedMapping은 log를 2로 계산합니다.
또한 gamma를 구하기 위한 correctingFactor(보정계수)도 구현체마다 다릅니다. gamma는 아래에서 쓰이는 값입니다.
x를 insert 할 때,
1. 아래 식으로 index를 구합니다.
2. index를 구하기 위한 γ(감마)는 (1+α)/(1−α) 수식으로 구합니다.
3. 버킷에 해당하는 index에 count +1 합니다.

- LinearlyInterpolatedMapping


- CubicallyInterpolatedMapping
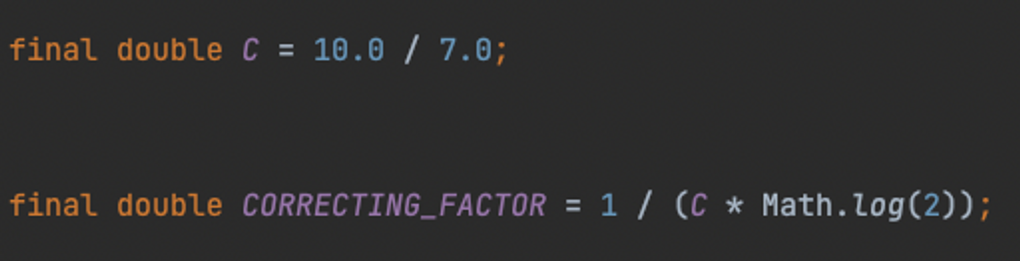
- LogarithmicMapping


이렇게 구현체에 따라 correctingFactor, gamma 값이 다르며, 사용자는 성능과 메모리에 적절한 구현체를 선택할 수 있습니다.
DD-Sketch를 사용했을 때와 비교 테스트 코드
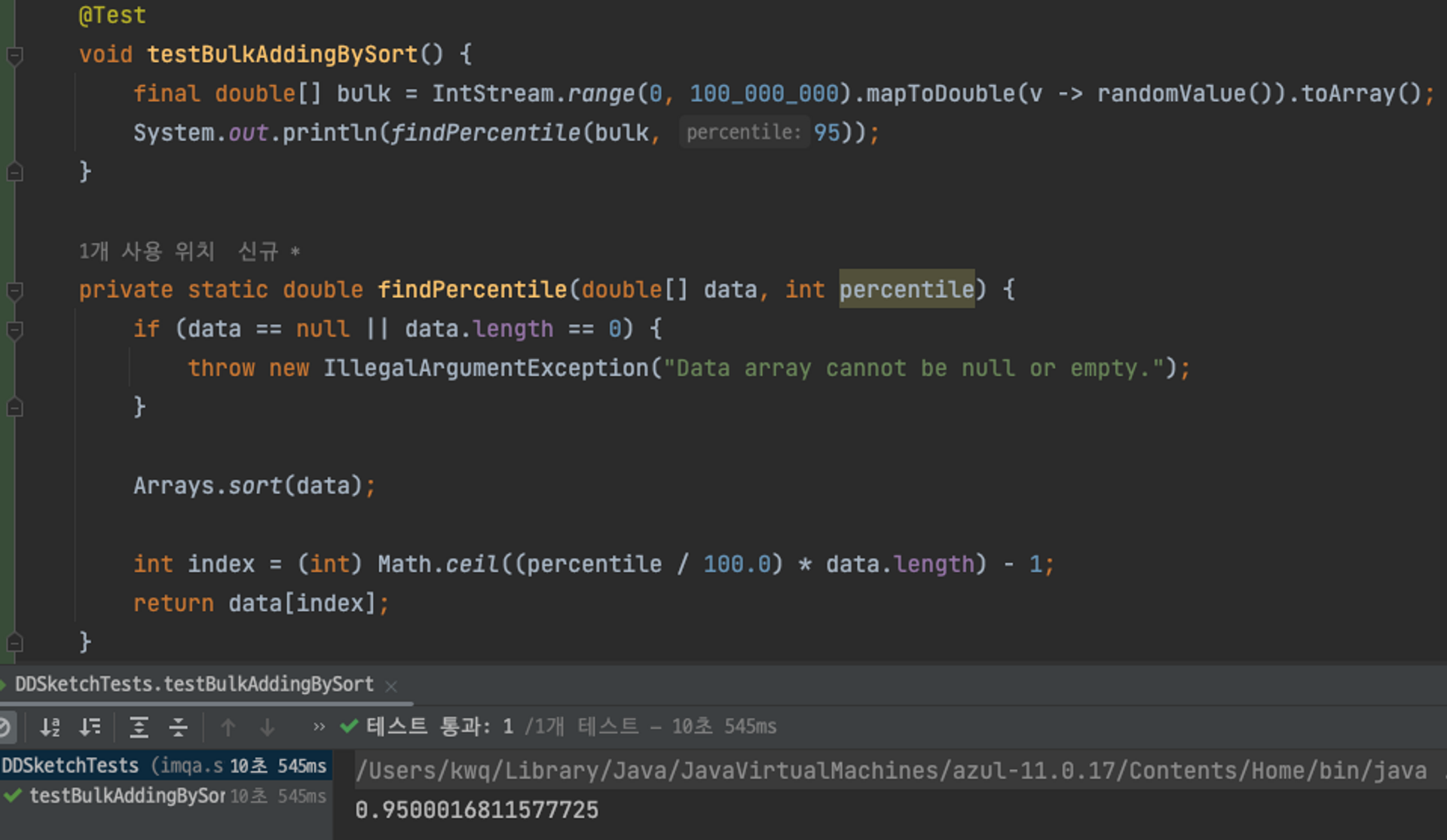
테스트는 아래와 같이 bulk insert와 merge가 잘 되는지 테스트했습니다. 1억 건에 모집단 데이터로 95% 값을 구하는 테스트를 진행했습니다. DD-Sketch를 사용하지 않을 때는 10초 걸리는 걸 확인할 수 있습니다.
DD-Sketch를 사용했을 때는 1초가 나오는 것을 확인할 수 있습니다.
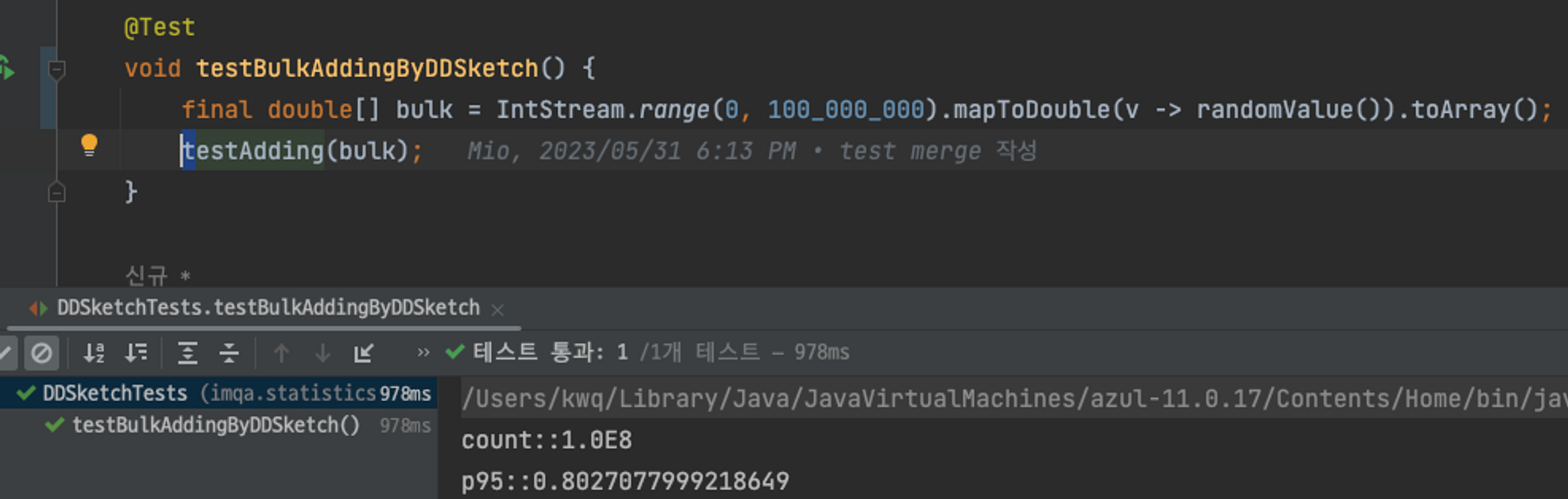
약 10배 정도 차이나는것으로 보여집니다. 데이터 건수가 많아지면 속도 차이는 더 많이 나게 됩니다. 실제로 구한 95%의 값과 DD-Sketch에서 구한 95% 값의 차이를 비교해 보겠습니다.
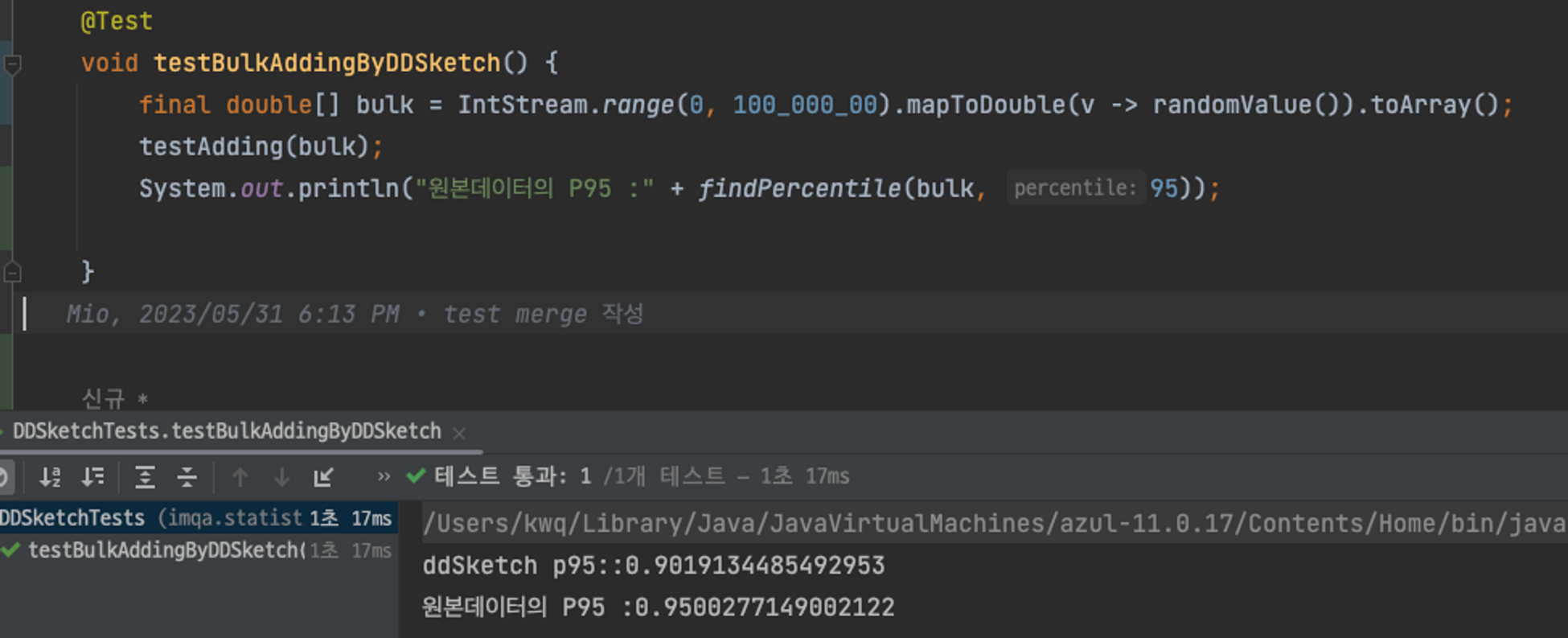
- DD-Sketch 95% 값 = 0.9019134485492953
- 원본 데이터의 95% 값 = 0.9500277149002122
두 값의 차이가 꽤 나는 것으로 보입니다. 이것은 아까 위해서 말한 Relative-error의 값이 0.1로 설정되어서 이런 차이가 발생했습니다. Relative-error 값을 0.01로 설정하고 다시 테스트를 돌려보겠습니다.
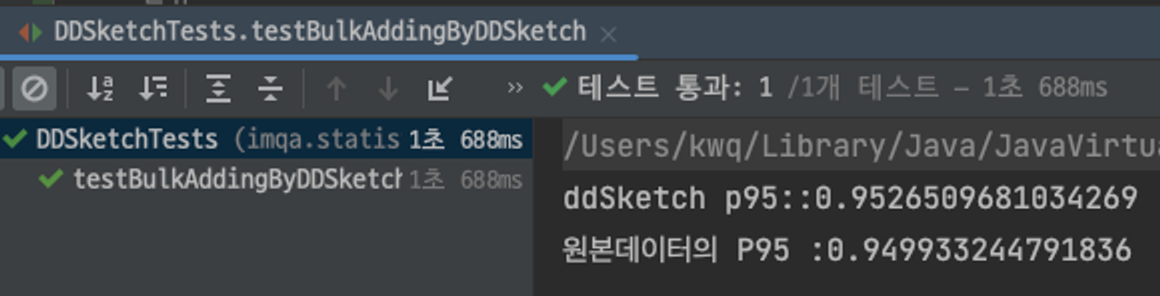
수정하고 돌린 결과,
- DD-Sketch 95% 값 = 0.9526509681034269
- 원본 데이터의 95% 값 = 0.949933244791836
값이 차이가 Relative-error 값대로 줄어있는 것을 확인할 수 있습니다. 이런 파라미터의 조절을 통해서 개발자는 95%에 해당하는 더 정확한 값을 얻을 수 있습니다. merge를 할 때도 서로 다른 두 건의 데이터가 정상적으로 merge가 되고 p95의 대략적인 수치도 잘 나오는 것을 확인할 수 있습니다.
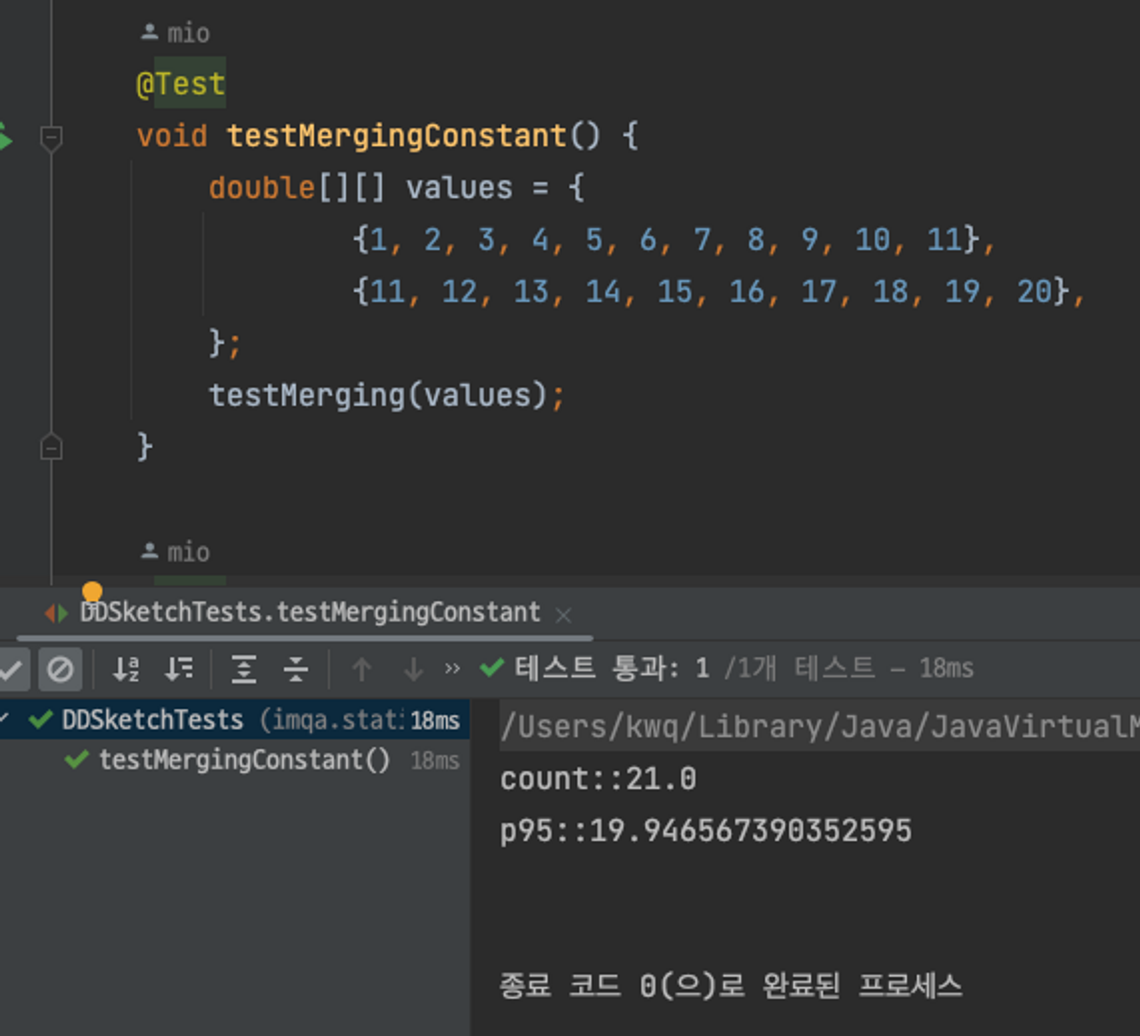
마무리
DD-Sketch는 데이터 스트림의 요약 정보를 효과적으로 유지하면서도 정확도를 유연하게 조절할 수 있는 유용한 알고리즘입니다. 특히 백분위수를 구하는 데 유용하며, DD-Sketch를 사용하면 효율적으로 계산할 수 있습니다. 대량의 데이터를 효율적으로 처리하고 의미 있는 지푯값을 추출할 수 있습니다.
이를 통해 성능 모니터링과 데이터 분석에 유용한 인사이트를 얻을 수 있습니다. DD-Sketch 알고리즘을 이해하고 활용할 수 있도록 도움이 되길 바랍니다.
<참고 자료>
- Charles Masson, Jee E. Rim, Homin K. Lee, "DDSketch: A Fast and Fully-Mergeable Quantile Sketch with Relative-Error Guarantees"
- Datadog, 2019년 9월 23일, Computing Accurate Percentiles with DDSketch, https://www.datadoghq.com/blog/engineering/computing-accurate-percentiles-with-ddsketch/
- IMQA 바로가기: https://imqa.io/