안녕하세요. IMQA 개발팀에서 백엔드 영역의 개발 및 운영 업무를 맡고 있는 황영입니다.
이번 글에서는 Count-Min Sketch라는 Sketch 알고리즘에 대하여 알아보겠습니다.
현재 IMQA의 아키텍처에는 Redis가 시스템의 속도 증가를 위한 캐시의 역할로 주로 사용되고 있습니다. 이 Redis를 활용하여 Count-Min Sketch를 쉽고 간단하게 적용해 보고자 하였습니다. 아직 실무에 적용하지는 않았지만, 앞으로의 IMQA의 개선 방향에 대한 실마리가 되지 않을까 싶습니다.
빈도 계산하기
Count-Min Sketch는 G. Cormode와 S. Muthukrishnan가 2003년에 발표한 sketch 알고리즘으로, 각 항목에 대한 빈도(frequency)를 표현하는 sketch 중 하나입니다. 빈도를 계산한다고 하였는데, 이건 어떤 의미인지 간단히 예를 들어 설명하겠습니다.
예를 들어, 다음과 같은 데이터 스트림이 있다고 가정해 봅시다.
[A, B, B, N, A, R, E, A, R, A, B]이 데이터 스트림에서 문자의 빈도를 세어야 한다고 하면 결과는 아래와 같을 것입니다.
A - 4, B - 3, E - 1, N - 1, R - 2문제점 도출
단순히 문자의 빈도를 세는 것이 아닌, 결과를 일정한 시간 간격으로 집계한다면 어떻게 해야 할까요? 또한 이를 임의의 범위로 조회한다고 하면 가능할까요?
물론 위의 결과를 이용하여 n시간 순서로 집계 및 조회를 할 수 있습니다. 하지만 이러한 데이터 스트림이 계속해서 증가하여 무한하다면 어떨까요?
실제로 시스템에서는 매일 수백만 건의 데이터가 생성될 수 있습니다. 만약 하루에 1TB의 데이터가 생성된다고 가정해 봅시다. 한 달이면 30TB의 데이터가 생성될 것입니다. 시스템에서 한 달간의 데이터 빈도를 계산할 필요가 있다면 어떻게 될까요? 30TB의 방대한 양의 데이터를 저장하고 처리하는 데는 상당한 공간과 시간, 비용적인 문제가 발생할 수 있습니다.
IMQA에서의 고민 사항
이러한 조회 범위에 따른 공간, 시간 제약 문제는 방대한 데이터를 다루는 실시간 모니터링 솔루션인 저희 IMQA에서도 항상 고민하는 문제입니다.
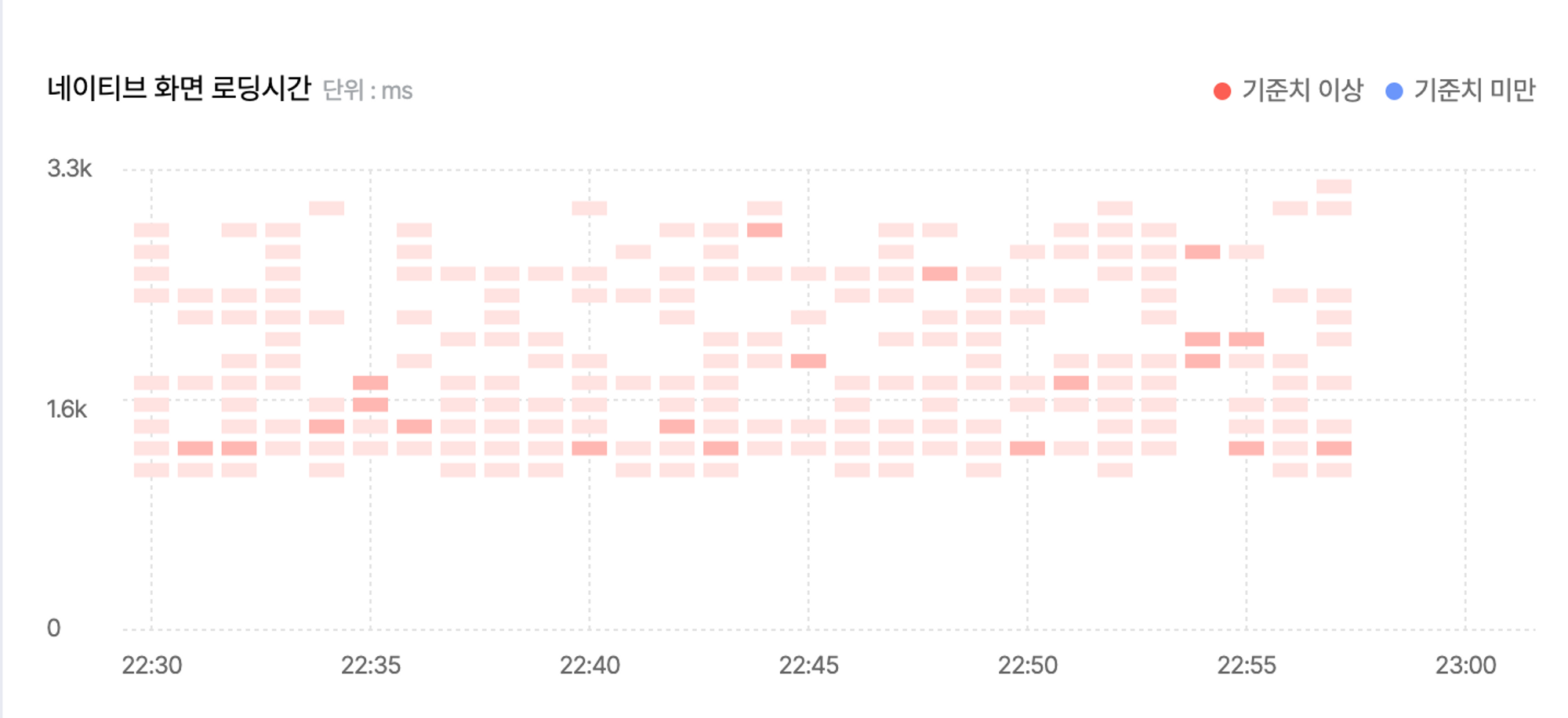
위의 이미지는 IMQA MPM의 ‘통계 > 구간분석’ 화면에서 '네이티브 화면 로딩시간'을 표현한 히트맵 차트입니다. 시간의 범위에 따른 화면 로딩속도를 구간별로 그룹화하여 빈도를 표현하고 있습니다.
저희는 MySQL에 raw 데이터를 저장하고 있고 시간당 많게는 40만 건 정도의 데이터를 조회하여 빈도를 계산하여야 합니다. 이를 실시간으로 조회하기에는 시간의 제약으로 사실상 사용이 불가능한 수준이었습니다.
이를 개선하고자 현재는 30분 단위로 조회 범위를 지정하고 배치를 이용하여 데이터를 집계하고, 해당 집계 데이터를 생성한 후 조회하고 있습니다. 집계가 완료된 데이터를 조회하기에 시간적 제약은 벗어났지만 30분마다 데이터를 집계하기에 선형 공간 사용으로 인한 저장 공간의 문제가 현재도 발생하고 있습니다.
따라서 선형 공간을 가질 여유가 우리에겐 없기에 이를 준선형(Sublinear) 공간으로 바꿀 필요가 있습니다.
준선형(Sublinear)
이러한 문제에 대한 솔루션은 '준선형(sublinear) 알고리즘'을 사용하는 것입니다. 여기서 이야기하는 준선형(sublinear) 공간은 무엇일까요? sketch에 대해 이해하기 위해선 먼저 준선형의 의미를 알아야 합니다.
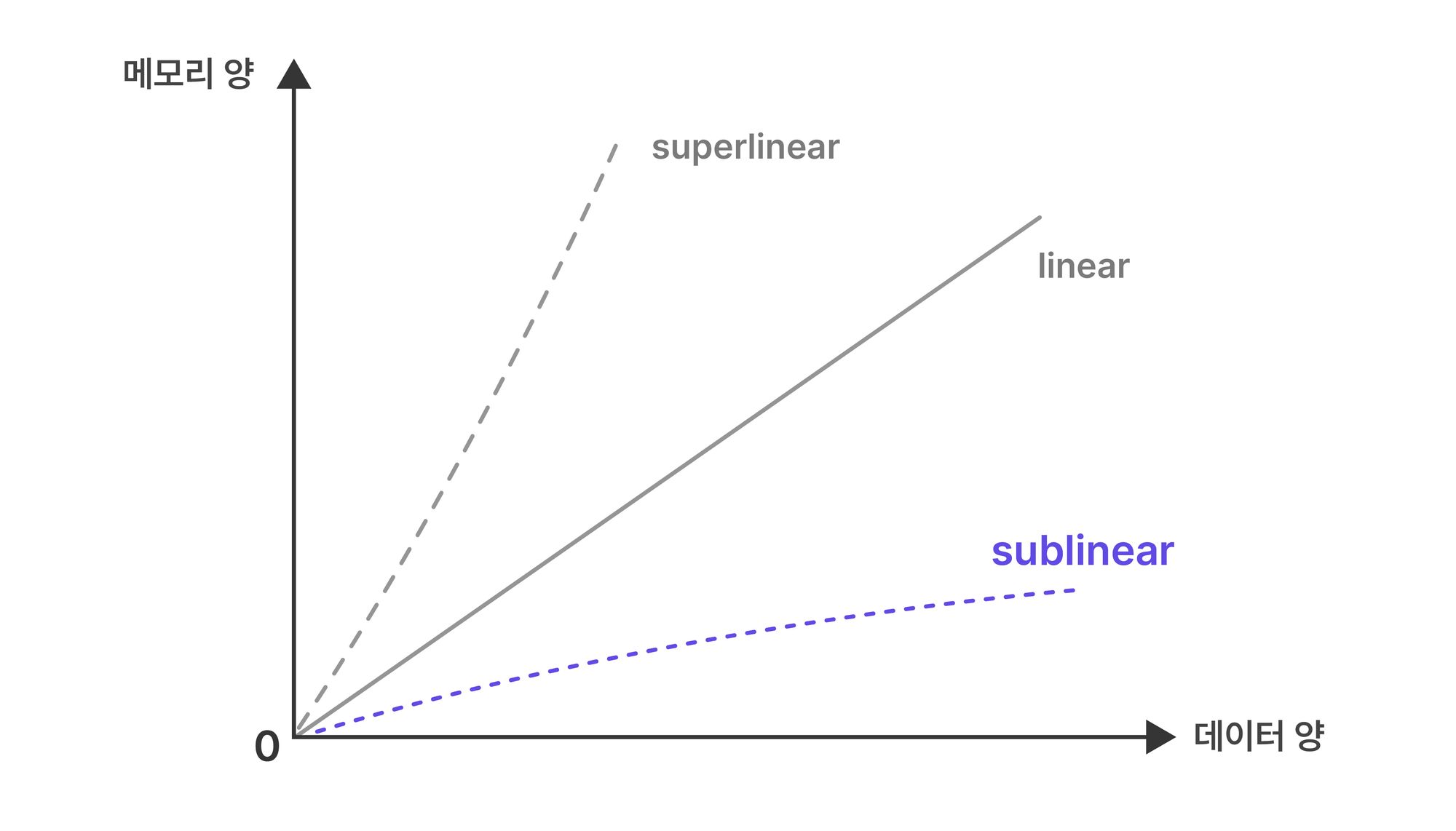
위의 이미지를 보면 데이터의 증가함에 따라 공간, 즉 메모리의 소비도 같은 방식으로 증가하게 되는 선형 그래프를 볼 수 있습니다. 반면, 준선형은 선형처럼 많은 데이터를 소비하지는 않지만, 비슷한 결과를 나타낼 수 있습니다.
준선형(sublinear) 알고리즘을 사용 시 데이터를 압축하여 작은 공간에 저장하므로 데이터 손실이 있을 수 있습니다. 즉, 약간의 부정확성이 발생합니다.
준선형으로 변경을 위한 쉽게 떠올릴 수 있는 방법으로 Hash table와 샘플링(Sampling) 등이 있습니다. Hash table의 유일한 단점은 매우 드문 경우로 해시 충돌로 모든 빈도를 재계산하여야 하는 경우가 발생할 수 있다는 것입니다.
샘플링을 사용할 경우, 우리가 얻을 수 있는 스트림은 특정 기간이나 확률적이거나 무작위로 샘플링하여 빈도를 측정할 수도 있습니다. 하지만 샘플링이 진정한 임의성을 보장할 수 없고 샘플링 방법에 따라 빈도의 집계가 다를 것입니다. 따라서 이 또한 우리가 원하는 진정한 빈도의 집계에는 부족하다고 볼 수 있습니다.
Bloom Filter
Count-Min Sketch를 설명하기 전 Bloom Filter에 대해 간단히 짚고 넘어가겠습니다. Bloom Filter는 확률적인 데이터 구조로, 원소의 존재 여부를 효율적으로 확인하는 데 사용됩니다. Bloom Filter에서는 m개의 비트 배열과 k개의 해시 함수로 구성됩니다. 그리고 각 비트의 초깃값은 0으로 초기화됩니다.
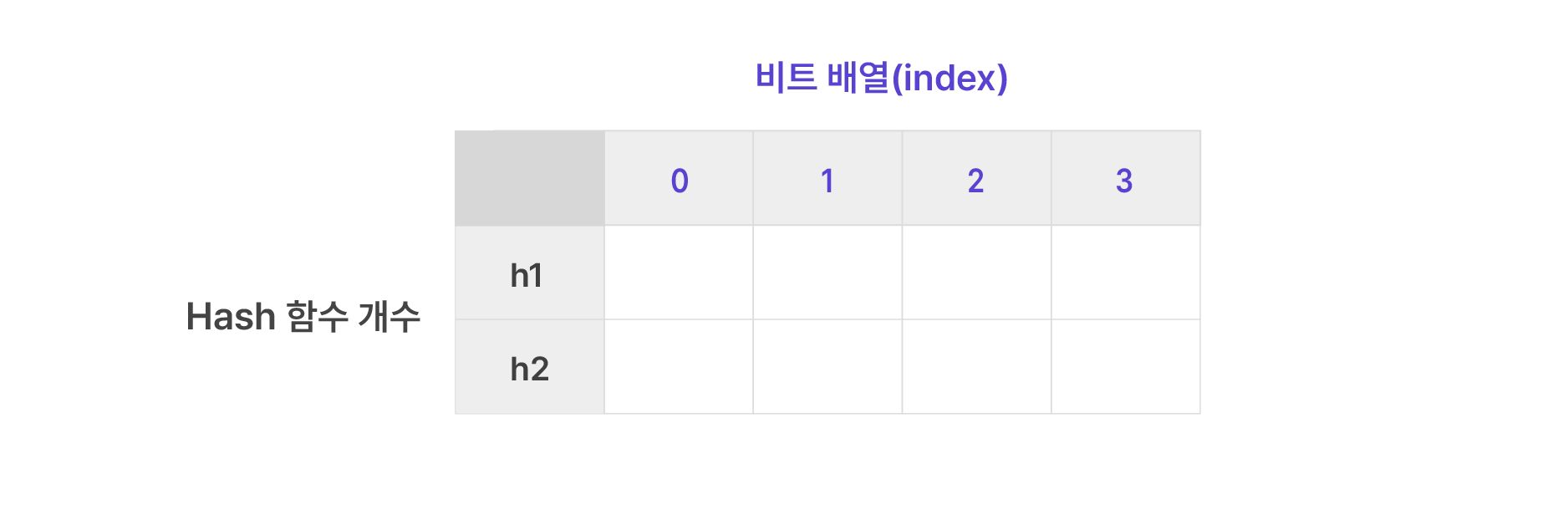
여기에 ‘A’라는 원소가 존재하게 될 경우 이를 해시 함수를 이용하여 비트 배열의 위치를 지정하고 값을 1로 변경합니다.
예를 들어 ‘A’ 원소를 h1 해시 함수를 이용하여 값을 구했을 때 값이 2라면 Bloom Filter의 h1 열의 1번째 비트 배열의 값(h1, 1)을 1로 변경하는 것입니다. 마찬가지로 h2 해시 함수의 결과가 3이라면 h2 열의 3번째 비트 배열(h2, 3)의 값을 1로 변경합니다. 이를 이미지로 표현하면 아래와 같습니다.
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| h1 | 0 | 1 | 0 | 0 |
| h2 | 0 | 0 | 0 | 1 |
추가로 ‘B’라는 원소가 추가되어 존재하게 된 경우 해시 함수의 결과가 h1(B) = 2, h2(B) = 3이라면 어떻게 표현이 될까요?
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| h1 | 0 | 1 | 1 | 0 |
| h2 | 0 | 0 | 0 | 1(충돌) |
h2(A)와 h2(B)의 결과가 3으로 동일하게 값이 나왔습니다. 이미 h2(A) 해시 함수의 실행 결과로 h2 열의 3번째 비트 인덱스의 값이 1이므로 h2(B) 해시 함수의 결과는 처리되지 않고 1로 유지됩니다. Bloom Filter에서는 값의 존재 여부만을 확인하기에 해시 함수의 값이 중복되어 나타나도 1을 유지하게 됩니다.
그렇다면 ‘A’ 원소의 존재 여부를 어떻게 확인할까요?
‘A’ 원소를 h1, h2 해시 함수를 통과시켜 비트 배열의 인덱스를 구합니다. 이미 보신 것처럼 h1(A) = 1, h2(A) = 3일 것입니다. 그리고 해당 위치의 비트 값을 확인합니다. (h1, 1) = 1, (h2, 3) = 1 로 확인이 가능합니다. 즉 모든 해시 함수의 결과로 비트의 값이 0에서 1로 변하였으므로 ‘A’ 원소는 존재한다고 할 수 있습니다.
물론 제한된 공간으로 인하여 모든 해시 함수의 비트 인덱스가 1이 될 수 있습니다. 따라서 100% 정확한 결과를 보장하지는 않습니다.
Count-Min Sketch
지금까지 Bloom Filter 설명한 이유는 Count-Min Sketch 알고리즘이 Bloom Filter 알고리즘을 확장한 개념이기에 먼저 설명을 해드렸습니다. 이렇게 준선형과 Bloom Filter의 기초 지식을 가지고 본격적으로 count-min sketch에 대하여 알아보도록 하겠습니다.
Count-Min Sketch는 2차원의 행렬 또는 배열 형태를 가집니다. 행(row)는 우리가 사용할 해시 함수의 수 입니다. 해시 함수의 수는 우리가 지정할 수 있습니다. 더 정확한 값을 원하는 경우 더 많은 해시 함수를 사용할 수 있습니다.
아래 예시에서는 간단히 확인하기 위해 4개의 해시 함수를 사용하였습니다. 열(column)은 해시 함수를 통해 출력하는 최대 수로 Count-Min Sketch에서 미리 정의된 크기로 표현하게 됩니다. 이러한 데이터 구조로 Count-Min Sketch는 준선형(Sublinear)이라고할 수 있습니다.

앞에서 사용하였던 예제를 Count-Min Sketch를 이용하여 표현해 보겠습니다. 지금은 단순히 알파벳을 사용하였지만, 실제로는 문장이나 숫자 등 여러 가지 값이 될 수 있을 것입니다.
[A, B, B, N, A, R, E, A, R, A, B]
각 알파벳을 각 해시 함수를 통과시켜 값을 얻습니다. A를 예로 설명하자면, A를 h1 함수를 통과시켜 나온 결과를 h1(A) = 1 이라고 표현하겠습니다. (각 값은 제가 임의로 정한 결과입니다.) 같은 방법으로 해시 함수 결과를 다음과 같다고 가정해 보겠습니다.
h1(A) = 1
h2(A) = 3
h3(A) = 4
h4(A) = 6
해시 함수를 통해 생성된 결과를 아래 표와 같다고 가정해 보겠습니다.
| h1 | h2 | h3 | h4 | |
|---|---|---|---|---|
| A | 1 | 3 | 4 | 6 |
| B | 2 | 1 | 6 | 3 |
| E | 4 | 6 | 4 | 0 |
| N | 6 | 4 | 1 | 2 |
| R | 0 | 2 | 0 | 4 |
이제 Count-Min Sketch의 2차원 배열에 해시 함수에 의해 도출된 값을 집계하여 보겠습니다. A 데이터를 가지고 집계를 진행해 보겠습니다.
먼저 이전에 해시 함수를 통과시켜 나온 결과는 h1(A) = 1, h2(A) = 3, h3(A) = 4, h4(A) = 6과 같습니다. 이를 해시 함수 위를 y축으로 하고 해시의 결과를 x축으로 이용합니다.
h1 해시 함수인 첫 번째 행에서 A의 해시 함수 결과는 1이므로 컬럼이 1인 위치에 카운터를 하나 증가시킵니다. 마찬가지로 h2 해시 함수 행에 3인 컬럼 위치에 카운트를 하나 증가시킵니다. 동일하게 h2, h3 해시 함수도 진행하면 아래 표와 같이 나옵니다.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| h1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| h2 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| h3 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| h4 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
그리고 같은 방법으로 알파벳 ‘B’의 빈도수도 측정하여 보겠습니다. 해시 함수의 결과로 h1(B) = 2, h2(B) = 1, h3(B) = 6, h4(B) = 3을 가지고 있습니다. 이를 기존의 count-min sketch 배열에 빈도수를 증가시켜 보면 아래와 같이 나타날 것입니다.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| h1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| h2 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| h3 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| h4 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
같은 방법으로 알파벳 스트림의 모든 값을 해시 함수열과 해시 결과로 컬럼의 위치를 지정하여 빈도를 집계한다면 아래와 같이 표현됩니다.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| h1 | 2 | 4 | 3 | 0 | 1 | 0 | 1 |
| h2 | 0 | 3 | 2 | 4 | 1 | 0 | 1 |
| h3 | 2 | 1 | 0 | 0 | 5 | 0 | 3 |
| h4 | 1 | 0 | 1 | 3 | 2 | 0 | 4 |
우리가 이제부터 하고 싶은 일은 값의 빈도를 확인하는 일입니다. 이미 스트림 데이터의 각 값에 대하여 해시 함수와 해시 함수의 결과를 알고 있기에 이를 활용하여 값을 확인할 수 있습니다.
h1(A) = 1
h2(A) = 3
h3(A) = 4
h4(A) = 6
예를 들어 'A'의 빈도를 확인하고 싶다면 (h1, 1), (h2, 3), (h3, 4), (h4, 6)의 해당 위칫 값을 활용하여 sketch 배열에서 위치를 찾아 빈도값을 확인합니다.
A의 각 해시 함수에 따른 빈도 결과
(row, col): 값
(h1, 1): 4
(h2, 3): 4
(h3, 4): 5
(h4, 6): 4
이렇게 얻어진 빈도수는 4, 4, 5, 4로 알고리즘 이름에서 암시하듯이 이 중에서 가장 작은 값 ‘4’를 취하게 됩니다. 우리는 모든 데이터를 sketch 배열 내에서 로드하여 빈도를 증가시켰기에 해시 충돌이 발생하여 값을 증가시킬수 있기 때문입니다. 따라서 Count-Min Sketch는 확률적 데이터 구조라고 할 수 있습니다.
우리의 고민 짚어보기
IMQA의 고민 사항인 히트맵 차트를 표현하는데 있어 문제가 되었던 내용으로 다시 돌아와 보겠습니다.
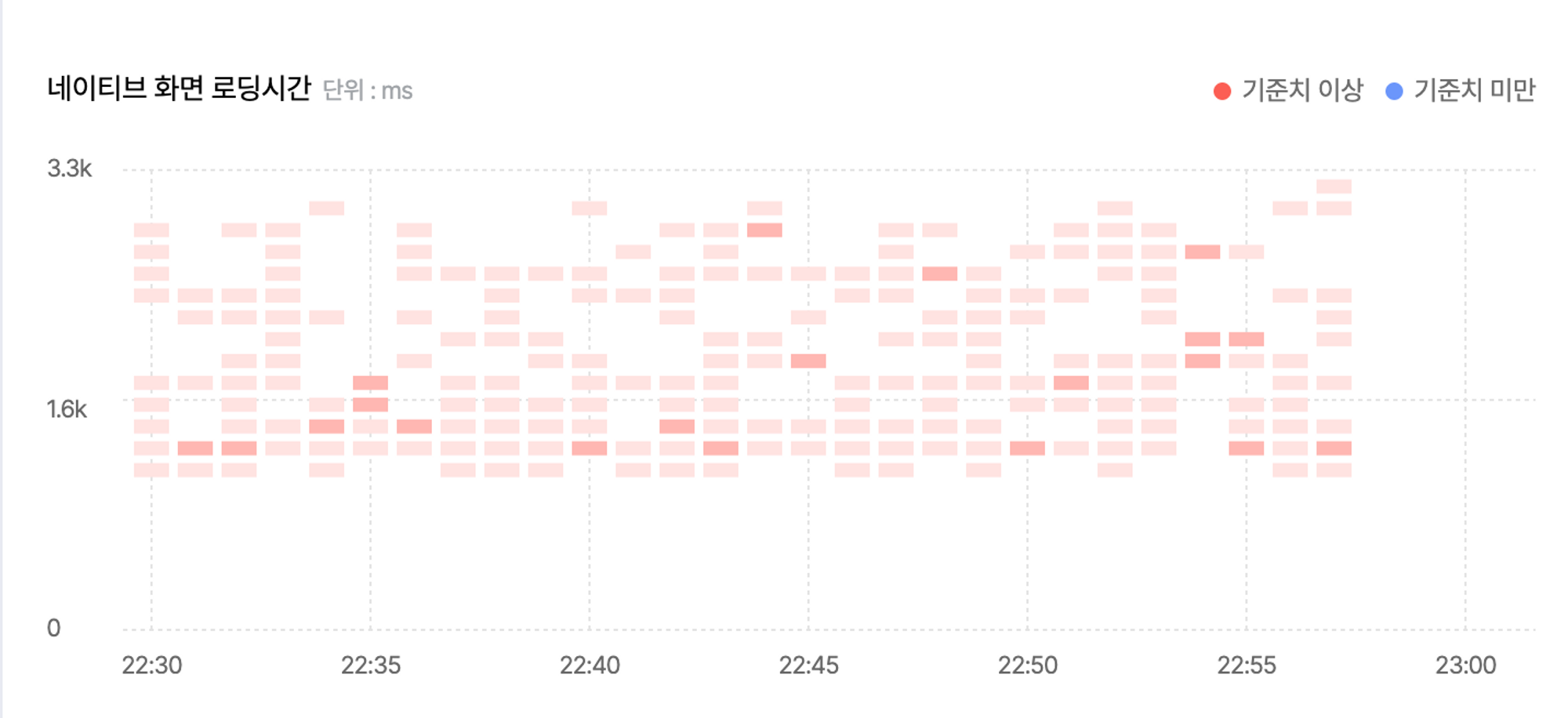
위의 이미지를 x축 기준을 살펴보면 1분 단위로 표현이 되는 것을 확인할 수 있습니다. y축으로는 응답 속도를 작은 단위로 그룹핑하여 빈도수를 측정하여 표현합니다.
즉, 우리는 Count-Min Sketch를 이용하여 분 단위의 저장 공간을 생성하여 측정된 응답 속도를 그룹핑된 대푯값을 이용하여 빈도수를 측정한다면 기존의 데이터를 준선형(sublinear)하게 변경이 가능할 것입니다.
예를 들어 2023.07.06 13:01에 네이티브 응답 속도 1,436ms가 수집되었다고 가정해 보겠습니다. Count-Min Sketch 저장 공간을 일시(2023.07.06 13:01)를 이용하여 구분되게 생성합니다. 그리고 응답 속도는 1,436ms를 5ms 단위로 그룹핑한다고 하면 1,435~1,440ms의 범위에 속하므로 1,435ms를 대푯값으로 빈도수를 증가시키도록 하는 것입니다.
문제는 '어떻게 구현할 것인가'입니다.
RedisBloom
Redis에는 RedisBloom(https://github.com/RedisBloom/RedisBloom)이라는 오픈소스 확장 모듈이 있습니다. 이 모듈은 확률적 데이터 구조를 지원하는 기능을 가지는데 Bloom Filter, Cuckoo Filter, Count-Min Sketch, Top-K, t-digest가 포함되어 있습니다. 이를 활용한다면 Count-Min Sketch를 따로 구현할 필요 없이 간단하게 사용할 수 있습니다. 하지만 이건 모듈이기 때문에 Redis 구성 시 모듈 설치가 필요합니다.
Redis Stack 활용
Redis에서는 RedisBloom을 포함한 여러 모듈을 묶은 Redis Stack을 제공하고 있습니다. Redis Stack에는 아래의 5가지 확장 기능이 추가되어 있습니다.
- RedisSearch -Full-Text 검색 지원
- RedisJSON - 쿼리가능한 JSON 문서 지원
- RedisGraph - Cyper 쿼리언어를 사용한 그래프 데이타 모델
- RedisTimeSeries - 시계열 데이타 처리 (수집 및 쿼리)
- RedisBloom - 확률적 데이타 구조
즉 Redis에 RedisBloom 을 따로 구성을 추가할 필요 없이 Redis Stack 만으로 사용할 수 있습니다. 도커를 이용하여 간단히 실행 후 count-min sketch를 이용한 히트맵 데이터를 생성 및 조회하여 보겠습니다.
// docker-compose
version : "3"
services :
redis:
container_name: redis_container
image: redis/redis-stack:latest
restart: always
ports:
- '6379:6379'
environment:
- REDIS_ARGS=--requirepass password
// 일시를 키로 하고 에러율 0.1%, 확실성 99.8%를 가지는 저장소 지정
> CMS.INITBYPROB 202307061301 0.001 0.002
OK
// native 로딩 속도가 1,435~1,440ms인 빈도수 1 증가
> CMS.INcrby 202307061301 native:1435 1
1) (integer) 1
// 한 번 더 증가
> CMS.INcrby 202307061301 native:1435 1
1) (integer) 1
// natvie 로딩 속도 1,435~1,440ms 조회
> CMS.QUERY 202307061301 native:1435
1) (integer) 2
Redis Stack을 활용하여 간단히 Count-Min Sketch 저장소를 만들고 빈도수를 측정해 볼 수 있었습니다.
결론
이렇게 RedisBloom 모듈과 Redis Stack을 활용하여 Count-Min Sketch를 구현해 보았습니다. 기존의 선형 공간을 필요로 하는 빈도 계산 방식에 비해 준선형(Sublinear) 공간으로 효율적인 결과를 얻을 수 있습니다. 실무에서는 수백만 건의 데이터를 다루는 경우가 많기 때문에 이러한 접근법이 중요한 역할을 할 수 있습니다.
여기서 소개한 예제 코드는 실제 운영 환경에서의 모든 예외 상황을 고려하지 않았으므로, 상용 환경에서 적용할 때는 더 많은 검증과 테스트가 필요합니다.
또한 RedisBloom 모듈을 사용하기 위해서는 해당 모듈을 Redis에 추가 설치해야 합니다. 실제 서비스에 적용하기 전에 충분한 검토와 성능 테스트를 거쳐야 함을 유념하시기를 바랍니다.
더 많은 개발 이야기는 다음에 이어서 하겠습니다!
감사합니다.
- IMQA 바로가기: https://imqa.io/