



트위터는 왜 두 번이나 모니터링 시스템을 직접 개발하였을까요? 대규모 트래픽을 가진 모니터링 서비스를 클라우드에서 구축할 때, 인사이트를 얻을 수 있습니다. 트위터 엔지니어가 거친 시행착오 이야기를 들어보시고, 여러분 서비스를 구축할 때 도움이 되는 인사이트를 얻으시길 바랍니다.
Monitorama 에서 발표한 Building Twitter Next-Gen Alerting System과 여러 컨퍼러스에서 발표한 내용을 정리해서 공유해 드리고자 합니다.
Twitter 초창기 모니터링 시스템 아키텍처
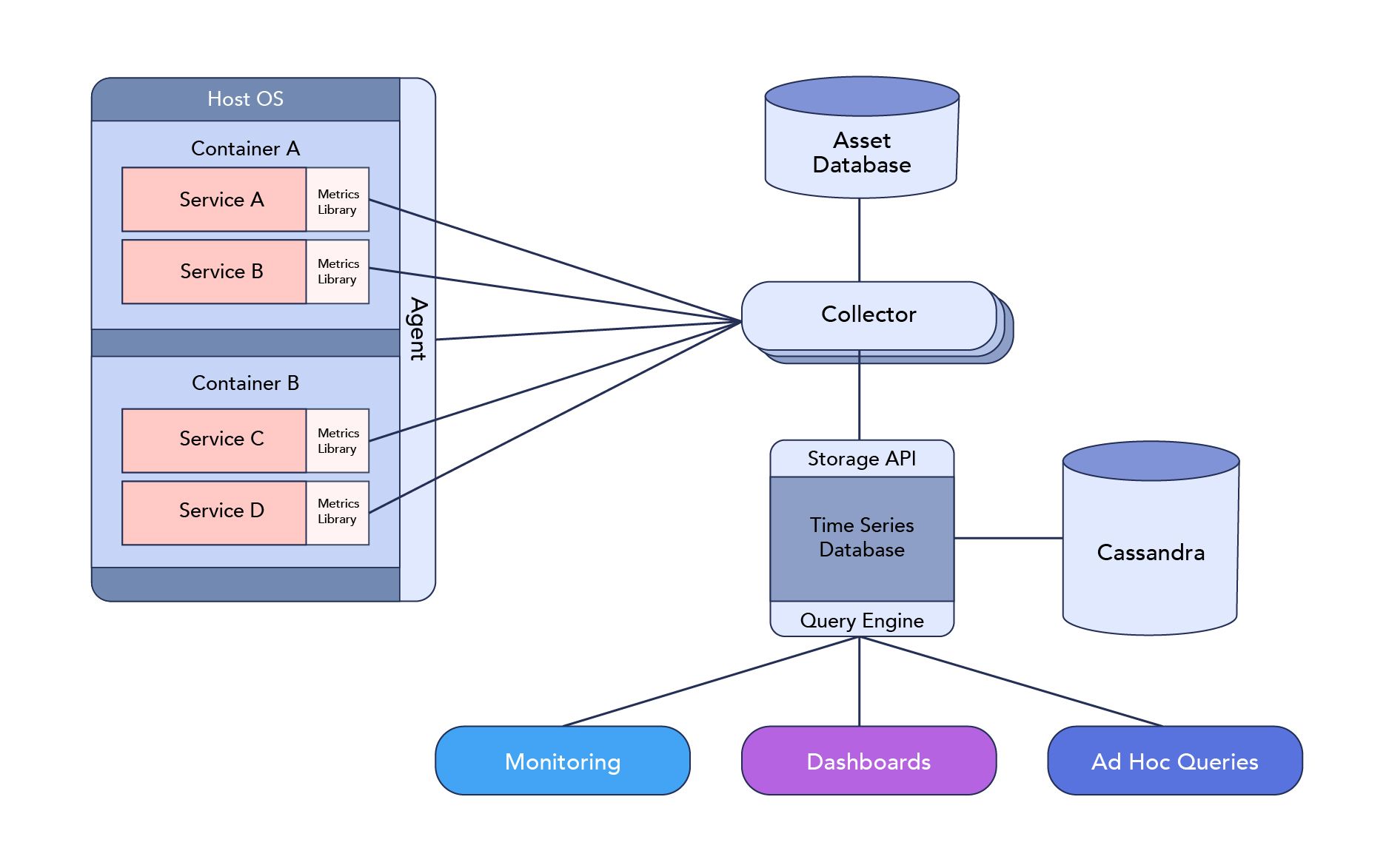
첫 모니터링 솔루션은 위와 같이 아키텍처를 수립하였습니다. 1.0 시스템은 다음과 같은 컴포넌트로 구성되어 있습니다.
- Agent - 데이터를 수집하는 Agent로 시스템 성능에 필요한 여러 지표를 수집
- Collector & Storage API - 수집부에서 데이터를 모아 Storage API를 통해 Time Series Database(Manhattan으로 추정)에 저장하고, 그 정보를 Cassandra에 저장
- Monitoring - Query 엔진으로 데이터를 긁어와 여러 지표를 모니터링
- Dashboard - Alert 과 Dashboard 를 쉽게 구성할 수 있는 Config, DSL을 제공
- Ad Hoc Queries - 상황에 따라 적합한 쿼리를 던질 수 있음
트위터는 왜 모니터링 시스템을 다시 만들어야 했나?
하지만 트위터의 급격한 성장으로 인해, 위 아키텍처로는 더는 트위터 시스템을 모니터링 할 수 없는 상황이 되었습니다.
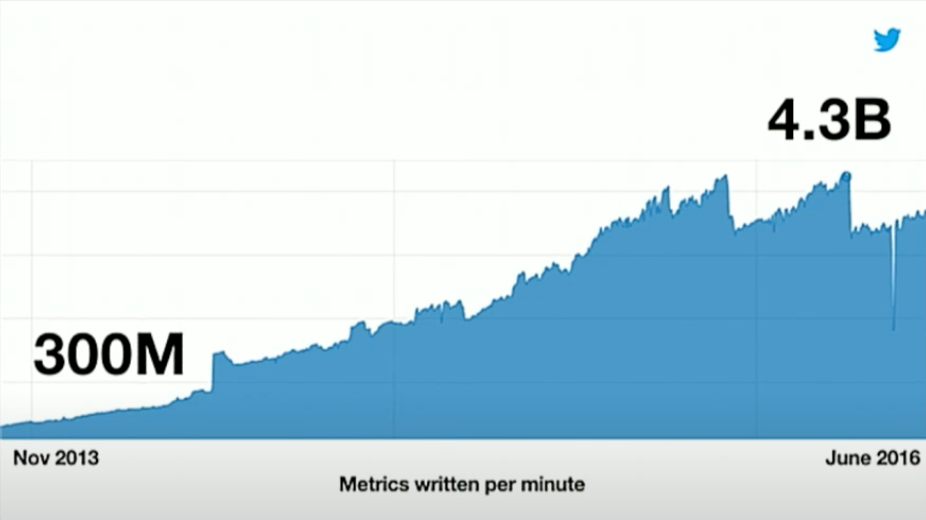
급격하게 늘어나는 수집 메트릭 정보
- 1분당 수집 메트릭이 3년 만에 3억 개(300M)-> 14배로 43억 개(4.3B)로 증가
- 발생하는 알럿의 증가 - 1분당 2,500개 -> 1분당 3만 개로 증가
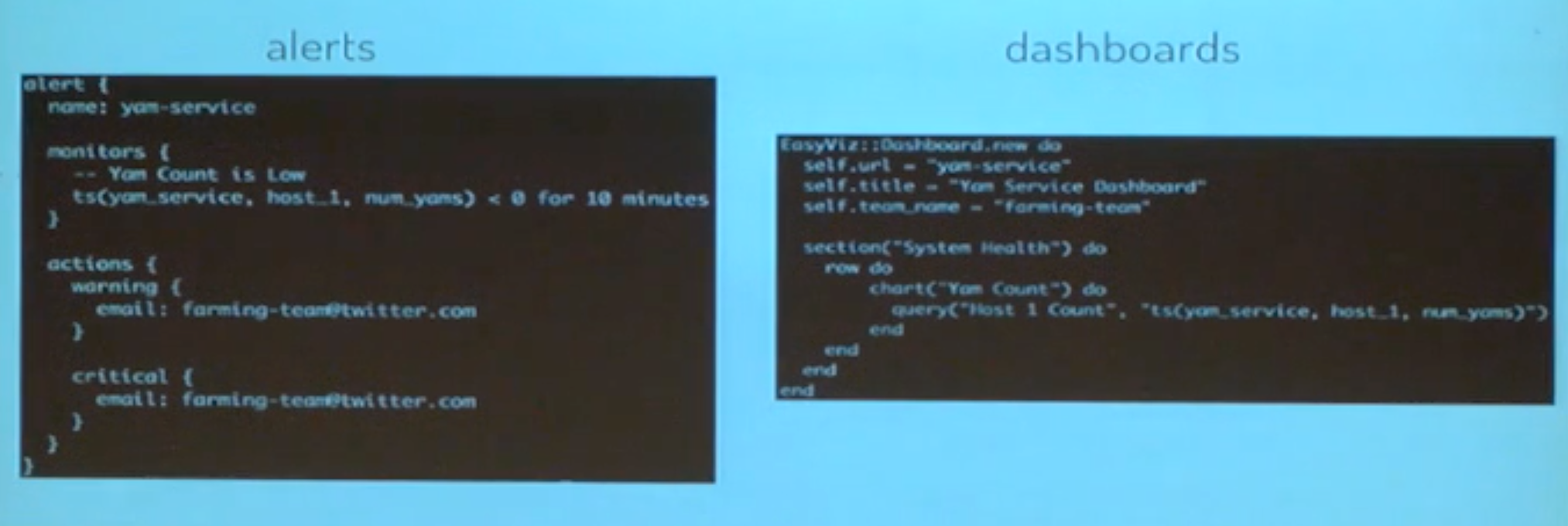
알럿과 대시보드의 불일치
기존 시스템의 Alert 설정은 간단하게 만들어서 올리는 형태로 되어있었습니다.
하지만 Alert config와 dashboard 구성 DSL 간의 관리가 잘 안 되었습니다.
알럿을 설정했지만, 대시보드 구성에 빠져서 정작 데이터는 못 보는 문제들이 발생하였습니다.
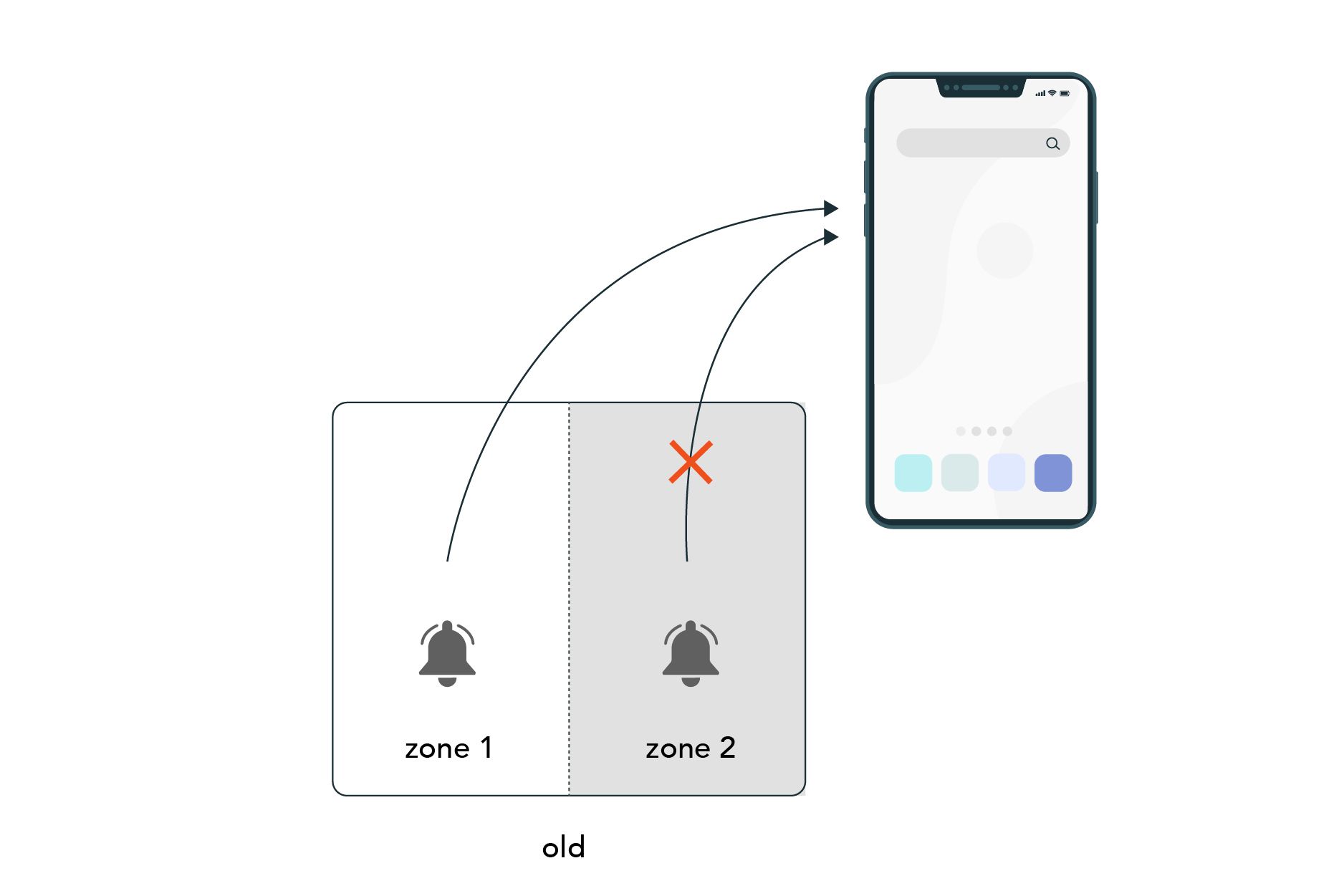
Alert Zone의 이중화
Alert 시스템을 한 존에서만 운영했는데, 자원을 공유하는 클라우드 환경이다 보니 특정 Zone 자체의 성능이 안 좋아져서 알럿이 안 온 사례도 많았습니다. 이에 Alert 시스템을 이중화하여 Multi Zone으로 구성하였습니다.
이에 동일한 알럿을 두 번 받게 되더라도, 예외처리하는 코드 등이 필요하게 되었습니다.
더 나은 트위터 모니터링 솔루션 2.0 만들기
새로운 모니터링 시스템을 만들기 위해 인터뷰를 진행하였습니다. 페르소나 분석 등 어떻게 개선할지 많은 이야기를 나누었습니다 .
모니터링 시스템 사용자의 요구를 정확히 파악하기 위해 요구하는 Feature에 대해 계속 질문을 하였으며, 답은 유도하거나 제시하지 않기 위해서 많은 노력을 했습니다.
- Usage - 화면을 보게 되었을 때 무엇을 하는가?
- Motivation - 1.0에서 알럿을 받았을 때 왜 반응하거나/ 반응하지 않았는가?
- Pain Point - 사용하면서 좌절하거나, 힘들게 만들었던 요인들은 무엇이냐?
개선된 2.0을 만들기 위해, 인터뷰하면서 다음과 같이 페르소나를 도출하기 위한 노력을 했습니다.

개선된 모니터링 2.0
실제로 어떠한 개선이 이루어졌는지 보시죠. 모니터링 솔루션을 제작하거나/사용하는 입장에서 충분히 공감할 부분들이 많았습니다.
알럿과 대시보드와의 통합
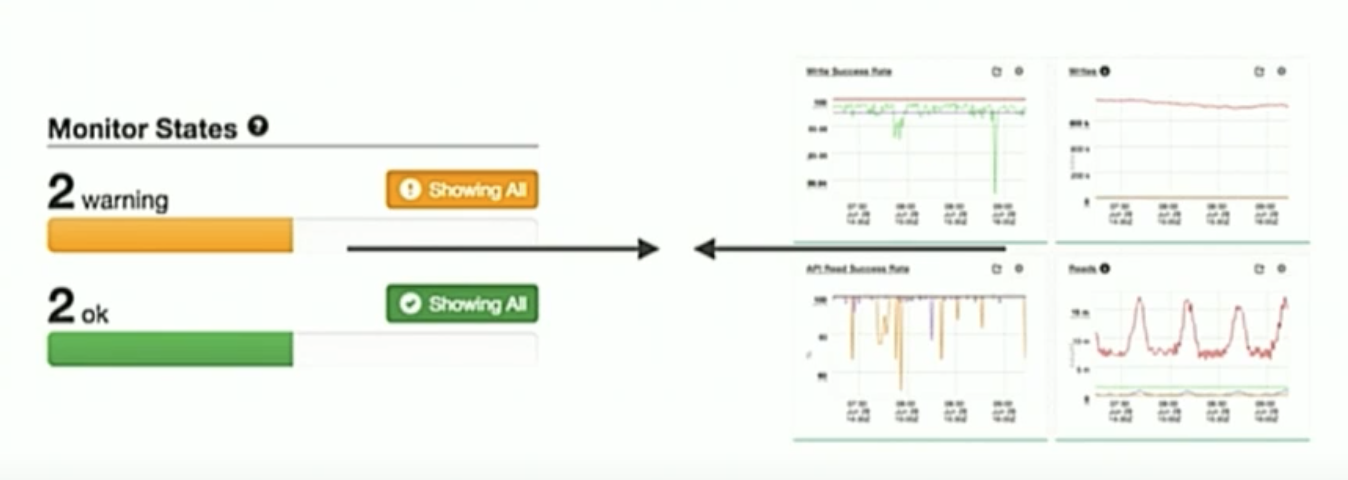
1.0에는 알럿과 차트가 분리되어 있어서 알럿이 발생해도 어느 대시보드에서 있는지 찾기가 어려웠습니다.
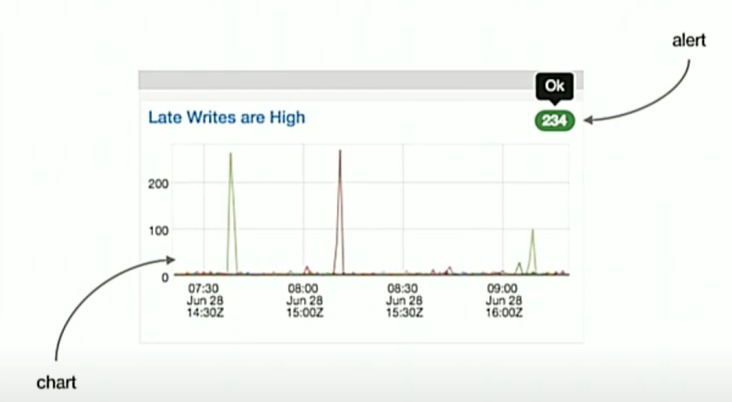
2.0에서는 알럿과 해당 차트가 맵핑됨으로써 차트에서 좋고 나쁜 상태를 확인하고, 알럿이 발생한 차트가 무엇인지 쉽게 찾을 수 있게 UI를 개선했습니다.
설정 언어와 대시보드 변경
기존 대시보드 구성을 DSL대신, python으로 변경하여 더 유연하게, 사전 검증할 수 있게 만들었습니다.

모니터링 하는 대상들을 Python 모듈로 만들어서 쉽게 대시보드에 addin되는 형태로 만들었으며, 배포 전에 server side validator를 통해서 안정성을 검증하는 로직을 강화했습니다.
알럿 신뢰성 확보 문제
1.0에서는 알럿 신뢰성을 위해 멀티 존에서 알럿을 보냈으나, 클라이언트 쪽에서는 두 번 메세지를 체크하는 등에 대한 여러 번거로움이 있었습니다. 그래서 zone의 건강 상태를 체크하고, 상태가 좋은 zone으로 alert 시스템을 rebalnacing하게 만들었습니다.
Twitter 모니터링 시스템 2.0 아키텍처
위에 대한 고민을 반영하여 새로운 모니터링 시스템을 만들었습니다.
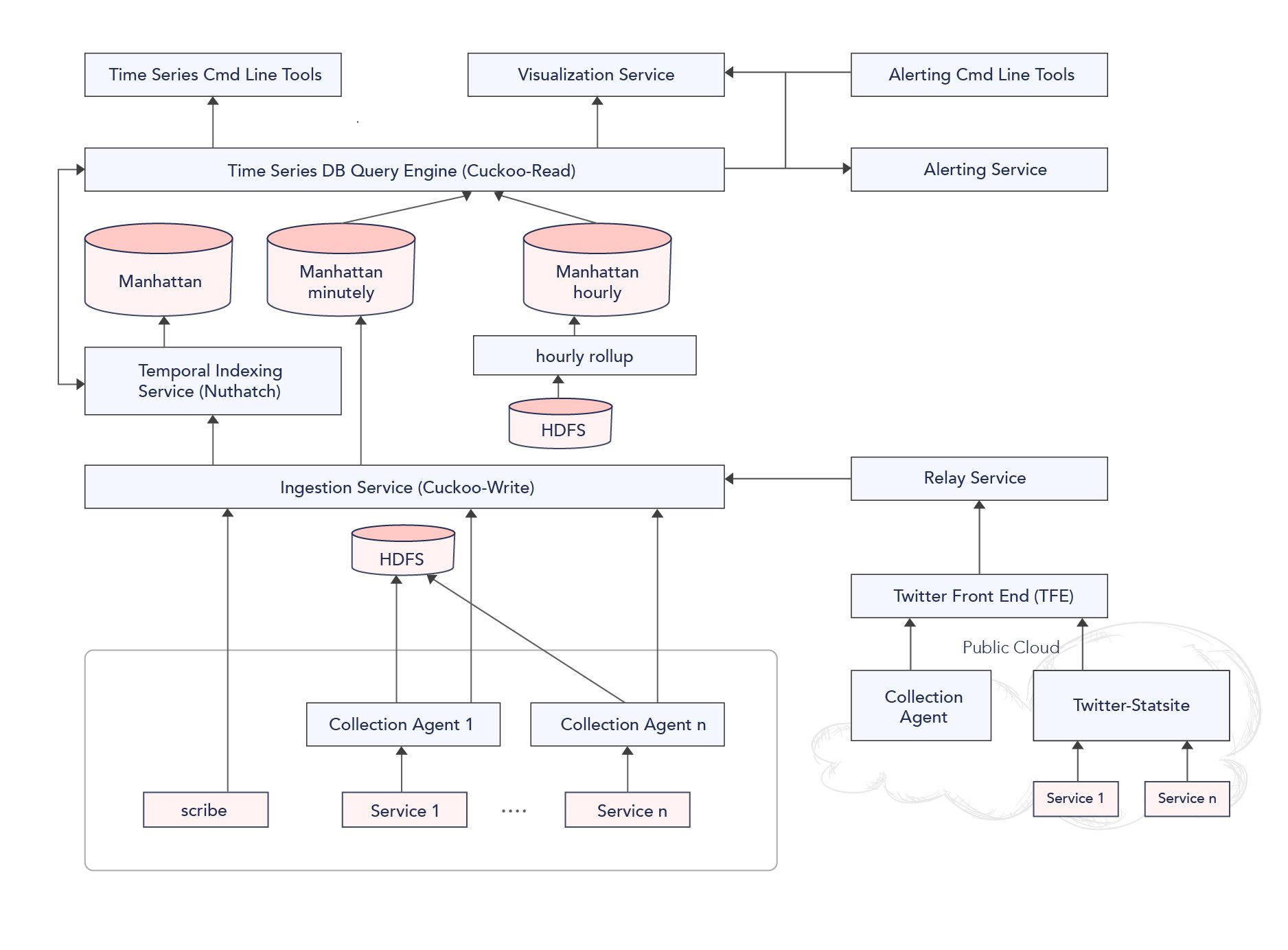
- Agent - Python으로 만들어진 Agent로부터 데이터를 수집
- Ingestion Service - 데이터를 저장 및 조회하는 엔진인 Cuckoo를 별도로 제공. 내부적으로는 트위터가 만든 Time Series DB인 Manhattan에 정보를 저장
- Time Series DB Query Engine - Cuckoo를 통해 원하는 데이터를 조회할 수 있는 CQL을 별도로 제공 (CQL은 내부적으로 다음과 같이 동작합니다)
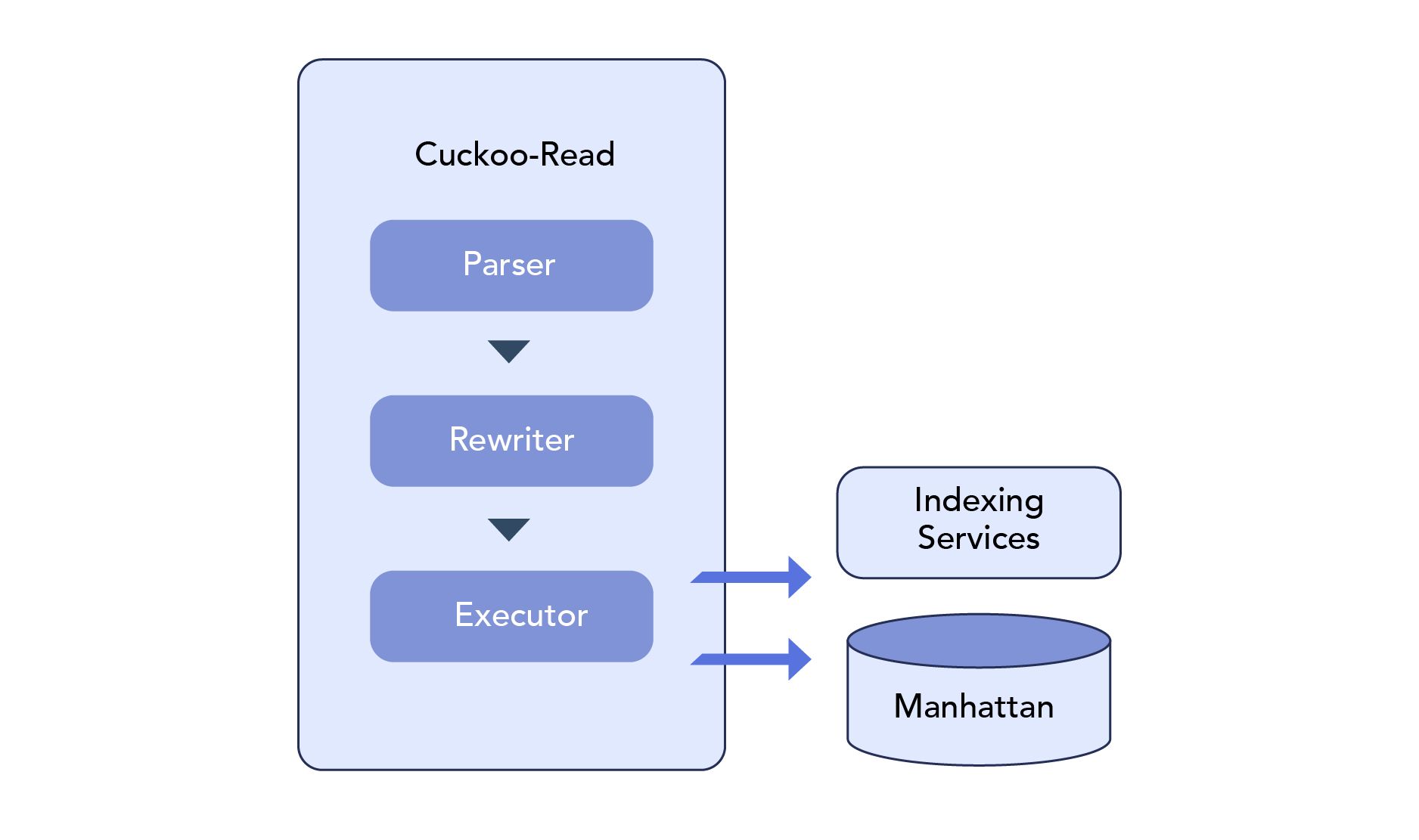
- Parser는 쿼리를 파싱하여 AST(Abstract Syntax Trees)로 만들고, Rewriter는 성능 향상을 위하여 AST 노드를 프로세싱 하고, 성능 향상을 위해 후처리 작업을 진행. 그리고 Executor는 Rewriter의 작업 결과물을 실행하고, output을 도출
- Time Based Aggregation - 입력받은 데이터를 가공하여 분 단위, 시간 단위로 쪼개어 저장.
- Temporal Indexing Service - 서비스, 소스 및 메트릭을 신속하게 탐색 할 수 있는 색인 서비스를 제공. 지표의 메타 데이터 / 타임 스탬프 등을 추적하고, 멤버 셋(redis 의 smember와 유사한 것으로 추정)에 대한 키 값을 관리
- CLI (command line interface) / Visualization - 고객은 CLI 와 를 시각화할 수 있는 UI를 사용하므로, 이에 적합하게 데이터를 전송
클라우드 존의 상태를 체크하여, 다른 Zone으로 이주(Rebalancing)하는 알럿 시스템 구축
이중화보다는 이사
모니터링에서 핵심 킬러 서비스인 알럿의 비용 절감 및 관리 효율화를 위해, 두개의 Zone에서 이중화하여 사용하는 것보다는, Zone의 상태(사견 : 네트워크 latency, IOPS, CPU StealTime 등을)가 좋지 않다면, 다른 Zone으로 알럿 시스템을 이사(ReBalancing) 할 수 있게 만들었습니다
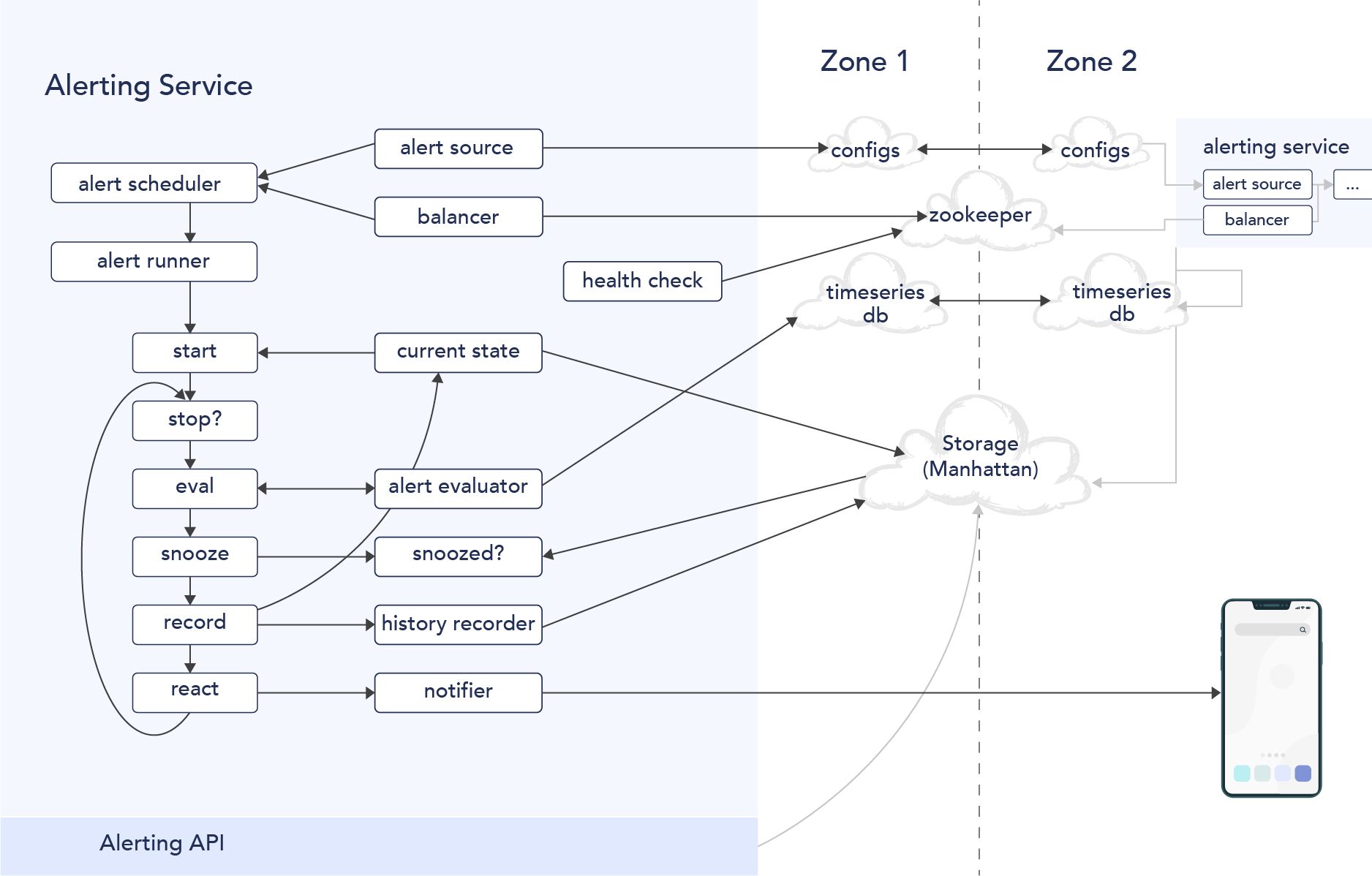
성능이 나오지 않는 존에서 scale out으로 처리하기보다는, 상태가 건강한 존으로 이사를 한다는 것이 눈여겨 볼만한 상황입니다. 이렇게 하기 위해서는 stateless process 기반으로 시스템이 구축되어야 한다는 점입니다. 그리고 상태정보가 저장되는 DB는 두 존에 다 배포되어 동기화된다는 것이 위 아키텍처의 핵심이라고 할 수 있습니다.
알럿을 빠르게 전송하기 위해 RuleSet들을 Shard로 나누어 전송.
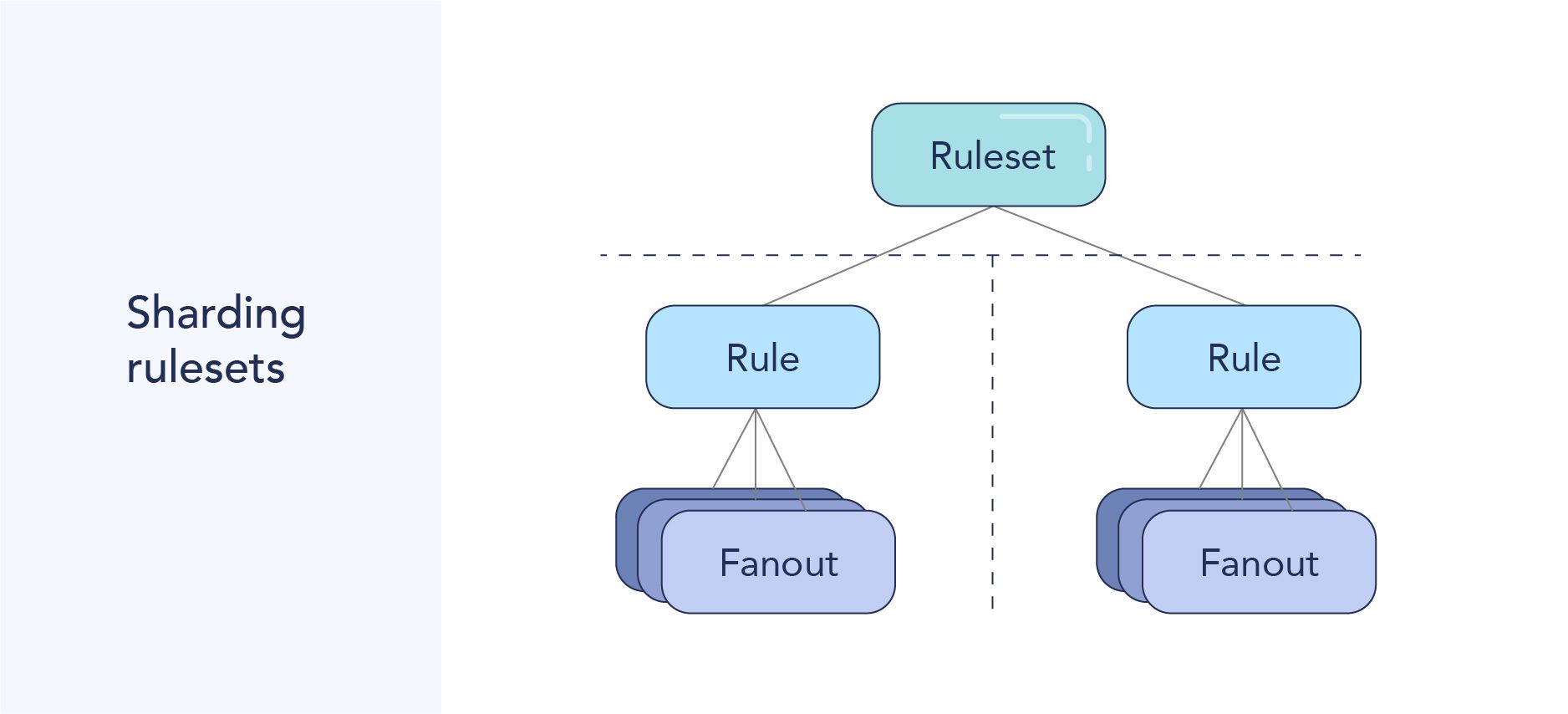
한 서버에 모든 Rule을 다 저장한 것이 아니라, Rule을 샤딩했다는 것입니다. 트위터 알럿 시스템 2.0 아키텍처에서 Balancer가 적절하게 샤드를 나누어서 배분한 것으로 보입니다.
Human Reasoning
장애가 발생하면 사용자가 합리적인 판단을 내릴 수 있게 만든다
고객이 솔루션을 사용할 때, 합리적으로 판단하고 추론할 수 있게 하는 것이 중요합니다.
장애 발생 시 Context를 고려해서 발생한 장애의 Root Cause를 찾는 것이 중요하며 그 유형을 다음과 같이 분류했습니다.
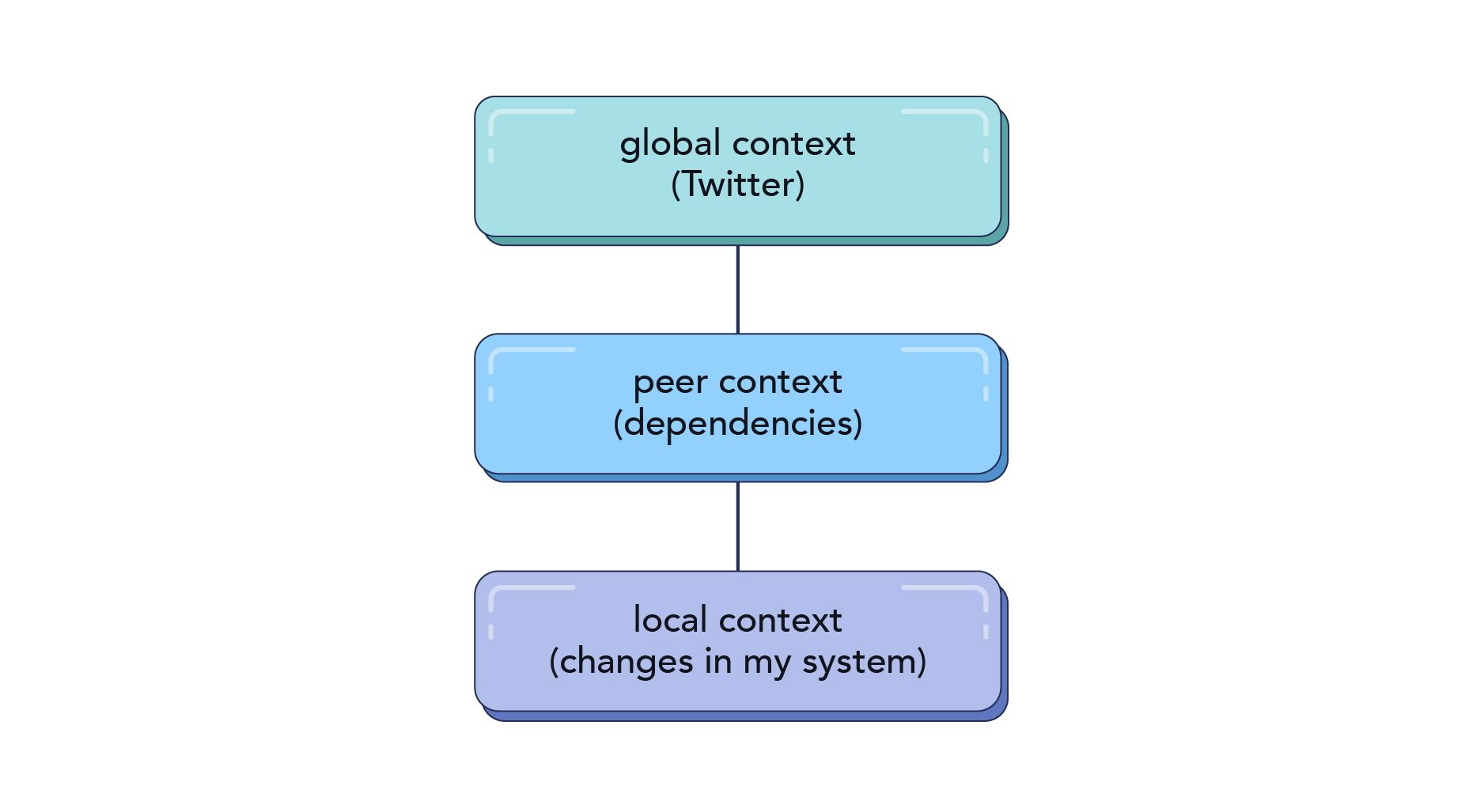
- Global context : backbone component(network.) 장애, 전체에 영향을 주는 장애
- Peer context : peer들 간의 의존 관계로 발생하는 장애 (Storage Layer의 문제)
- Local context : 배포를 잘못한 경우 등
시스템을 다시 안정화할 필요가 있는데, 다음과 같이 구성하여 해결.
실행 지침(list of steps)과 해결이 힘들 경우 escalation할 컨텍 포인트(link)를 제공.
알럿이 발생한 곳과 연관된 차트에 표현하기
사용자의 참여를 강화시켜라 (Empower Human)
2.0을 만들고 나서, 사용자들이 잘 사용할 수 있게, 1차부터 3차까지 전방위적으로 지원하는 체계를 만들었습니다.
1차 지원 - Interaction 접점을 다양하게 제공

기존 사용자가 접근하기 용이한 접점을 고려해서, UI(가능한한 쉽게 만들기), 명령어 도구(도움이 되는 사용 메시지 제공), 설정 라이브러리 형태(사용자가 볼 수 있는 코드 기반의 문서)를 제공하였습니다 .
특히 세 번째 Configuration Libraries 많은 시간을 투자하였습니다.
2차 지원 - 최신의 Documentation 제공하기
특히 코드와 일치가 유지되도록 많은 노력을 진행하였습니다.

3차 지원 - 당번(On Call) 제도 운영
당번을 두어 직접 대응하게 하였습니다.

맺음
클라우드 상황에서 서비스의 안정성을 유지하기 위해서 모니터링은 필수입니다.
- 모니터팅의 핵심인 알럿의 높은 성능을 유지하기 위해 zone의 상태를 보고 이사를 갈 수 있는 시스템을 만들기
- 내부 시스템이지만 1.0 사용자를 인터뷰하면서 2.0 개선안을 도출해내는 점진적 개선하는 모습들
- 알럿과 알럿이 발생한 UI 통합
그리고 이 컨셉들이 향후 IMQA 알럿 및 이벤트 기획 시 많이 도움이 될 듯 합니다.
이 내용인 모니터링 컨퍼러스인 monitorama의 Building Twitter Next-Gen Alerting System 내용과 여러 블로그 글들을 참고하여 요약한 것입니다.
- Observability at Twitter: technical overview, part I
- Observability at Twitter: technical overview, part II
오역 및 부족한 부분이 있을 수도 있으니 support@imqa.io로 연락해주시면 수정하도록 하겠습니다.
이 주제와 연관된 성능 이슈/ 모니터링에 도움이 될만한 글을 추천해 드립니다.

