




IMQA에서는 stack을 수집하여 성능이 느린 원인을 찾아주고 있습니다. 이번 포스팅에서는 stack에 대해 알아보겠습니다.
Stack이란?
기본적으로 Stack이 무엇인지 알기 위해 구글에 검색해보면 다음과 같은 결과가 나옵니다.
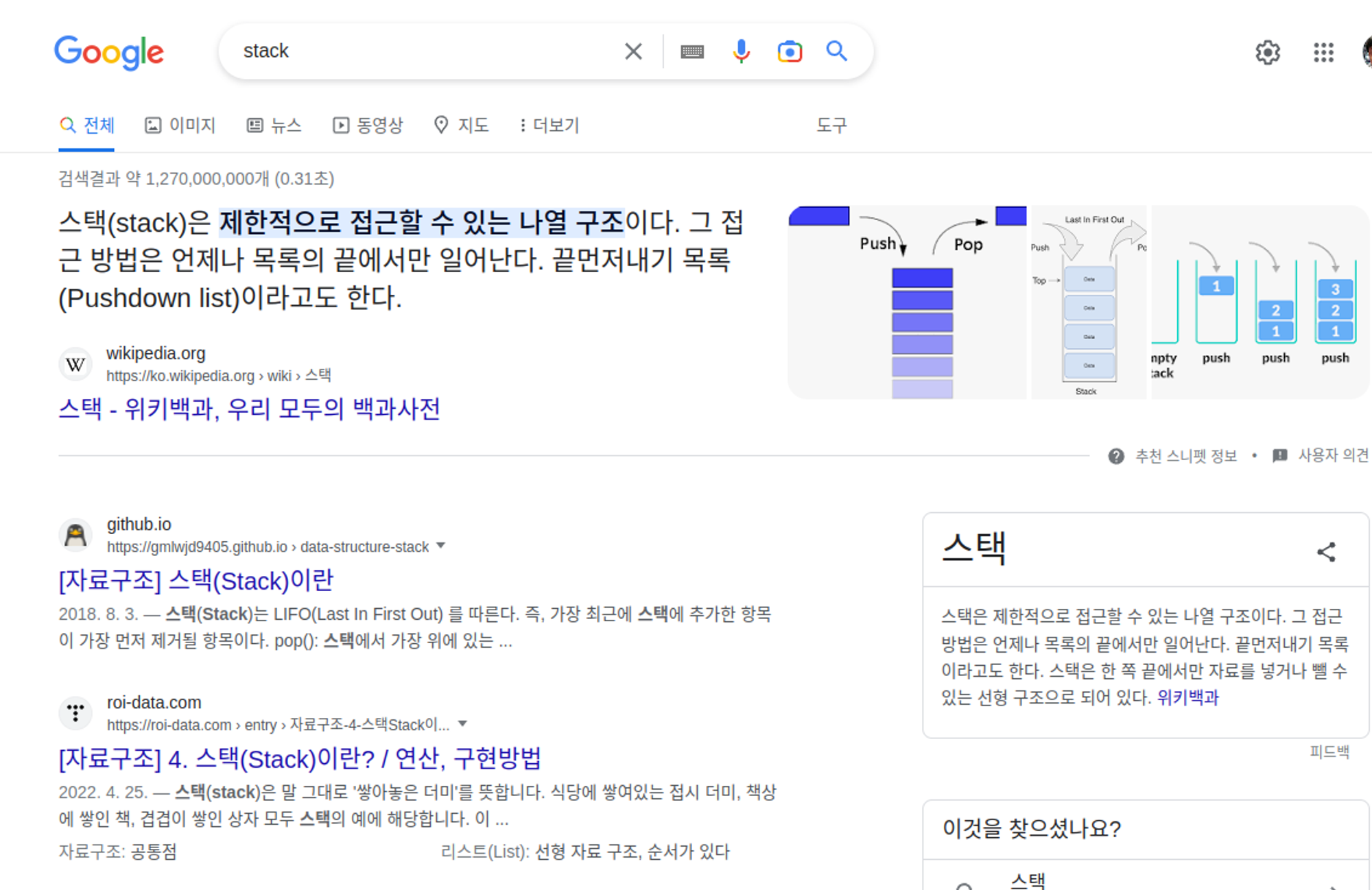
'스택(stack)은 제한적으로 접근할 수 있는 나열 구조이다.'
구글에서 검색해 보니, '자료 구조'라고 나오는데요. 말 그대로 '자료(데이터)를 저장하는 구조'라는 것이겠죠?
Stack의 특징은 LIFO(Last-In First-Out, 후입선출)라는 것인데요. 먼저 들어간 것이 나중에 나온다, 나중에 들어간 것이 먼저 나온다는 것이죠. 그렇다면 왜 이런 자료 구조가 필요한 것일까요?

접시를 생각해 볼까요? 저는 집에서 접시를 잘 사용하지 않지만(정확히는 밥을 잘 안해 먹지만), 접시를 쌓아둘 때는 차곡차곡 쌓아 놓은 다음에 가장 위에 있는 접시부터 사용하는데요. 이러한 접시를 쌓아 놓고 사용하는 구조가 우리가 일상생활에서 stack을 사용하는 좋은 예시가 아닐까요?
하지만 stack이라는 자료 구조 용어는 우리의 일상생활에서도 많이 사용합니다. 저는 문제가 발생할 때마다, 즉 문제 더미(stack)가 여러 개 쌓이면(stack) 커피를 마셔줘야 하는데요. 무언가를 쌓아 올리거나 묶을 때도 stack이라는 말을 쓰는 것 같죠?

IMQA에서 말하는 Stack이란 무엇일까요?
컴퓨터가 프로그램을 실행시킬 때는 다양한 명령어를 호출하는데요. 예를 들어, A 명령어는 B 명령어를 호출하고, B명령어가 C명령어를 호출하고 나서 C명령어가 끝나고, B명령어가 끝나게 되면 A명령어는 D명령어를 호출한다고 보죠.
말이 너무 어렵죠? 명령어를 집안에 연결된 방에 들어가는 식으로 볼까요. 대신 이 집에는 규칙이 있습니다. 방에 들어갈 때마다 각 방에서 주는 방문증을 받아야 하고, 나갈 때는 방문증을 반납해야 합니다. 방문증은 우리가 배운 stack 방식으로 들고 가죠.
그러면 제가 C방에 방문하였을 때 어떤 방문증을 가지고 있을까요? C방문증, B방문증, A방문증 순서로 3개의 방문증을 가지고 있겠죠. 방문증은 Stack 방식으로 들고 갔으니, LIFO에 따라 가장 마지막에 받은 방문증이 제일 위/첫 번째에 있을테구요.
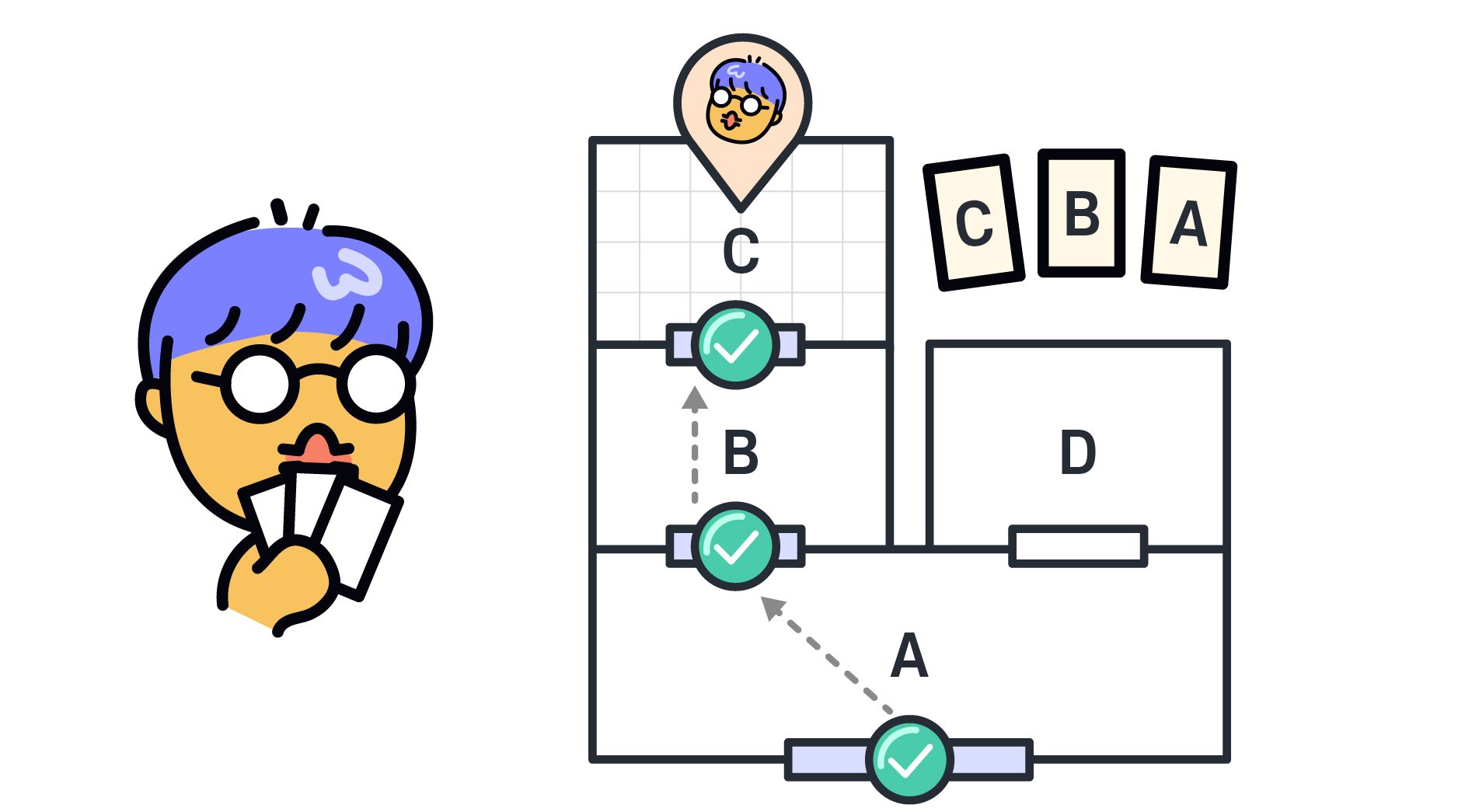
D에 방문하였을 때는 어떨까요? D방문증, A방문증을 들고 있겠죠?
프로그램도 이런 식으로 동작하는데요. 방에 방문한 여러분이 CPU라고 생각하고, 명령을 호출할 때마다 이러한 명령이 stack에 저장됩니다. 그러면 이 stack만 잘 열어보면 동작 중인 프로그램이 현재 CPU가 갔던 방(명령)을 알 수 있죠.
Stack을 어떻게 봐야 성능을 알 수 있는 걸까요?
stack을 보면 프로그램이 무엇을 하고 있는지(어느 방에 갔는지) 감시할 수 있습니다. 이것으로 어떻게 성능을 분석할까요?
1. 시간으로 성능 측정하기
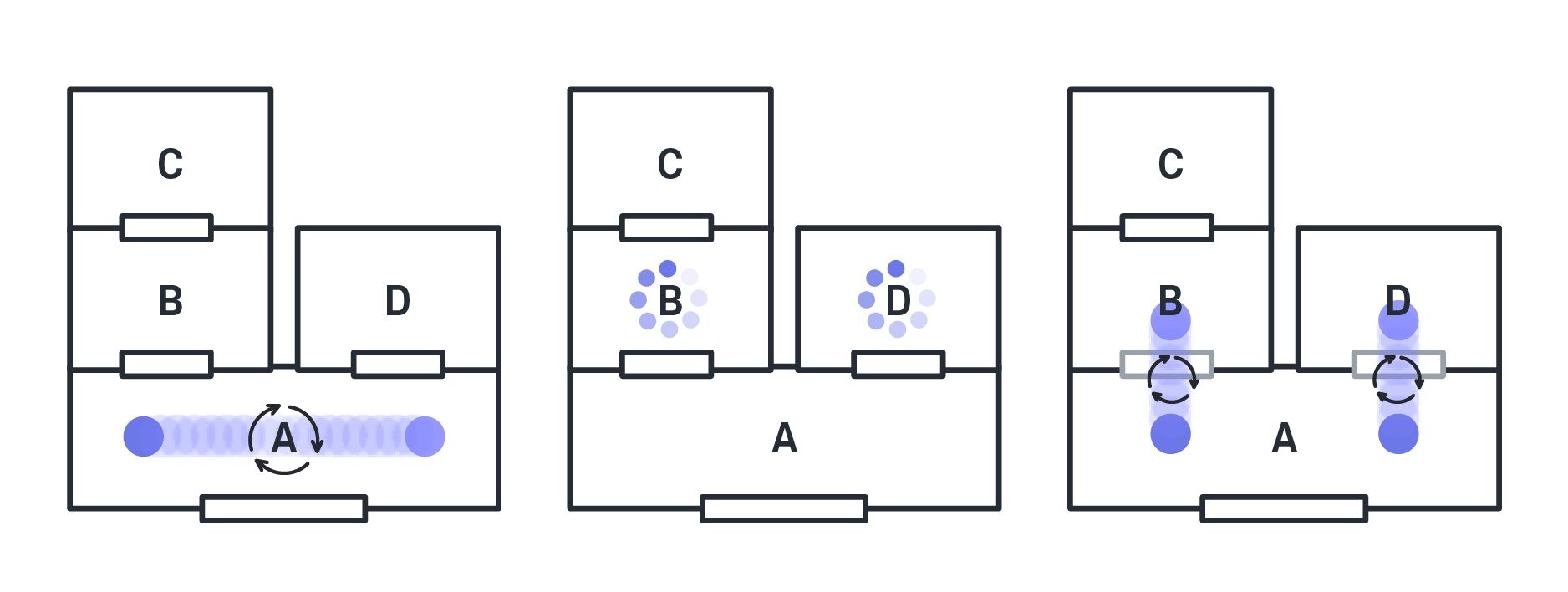
성능이 느리다는것은 그 작업을 오랫동안 한 경우로 볼 수 있는데요. 위에서 예시로 든 방으로 봤을 때, 방에 오랜 시간 머문 경우라고 할 수 있겠죠.
만약 A가 동작하는 시간이 오래 걸렸다면, B가 오래 걸린 것인지 D가 오래 걸린 것인지를 확인하고, 해당 코드를 고치면 되겠죠.
하지만 이런 경우도 있습니다. A가 오래 걸려서 봤더니 B와 D를 100번 방문해서, 즉 방문을 많이 해서 오래 걸린 경우가 있을 수 있겠군요.
2. 사용량으로 성능 측정하기
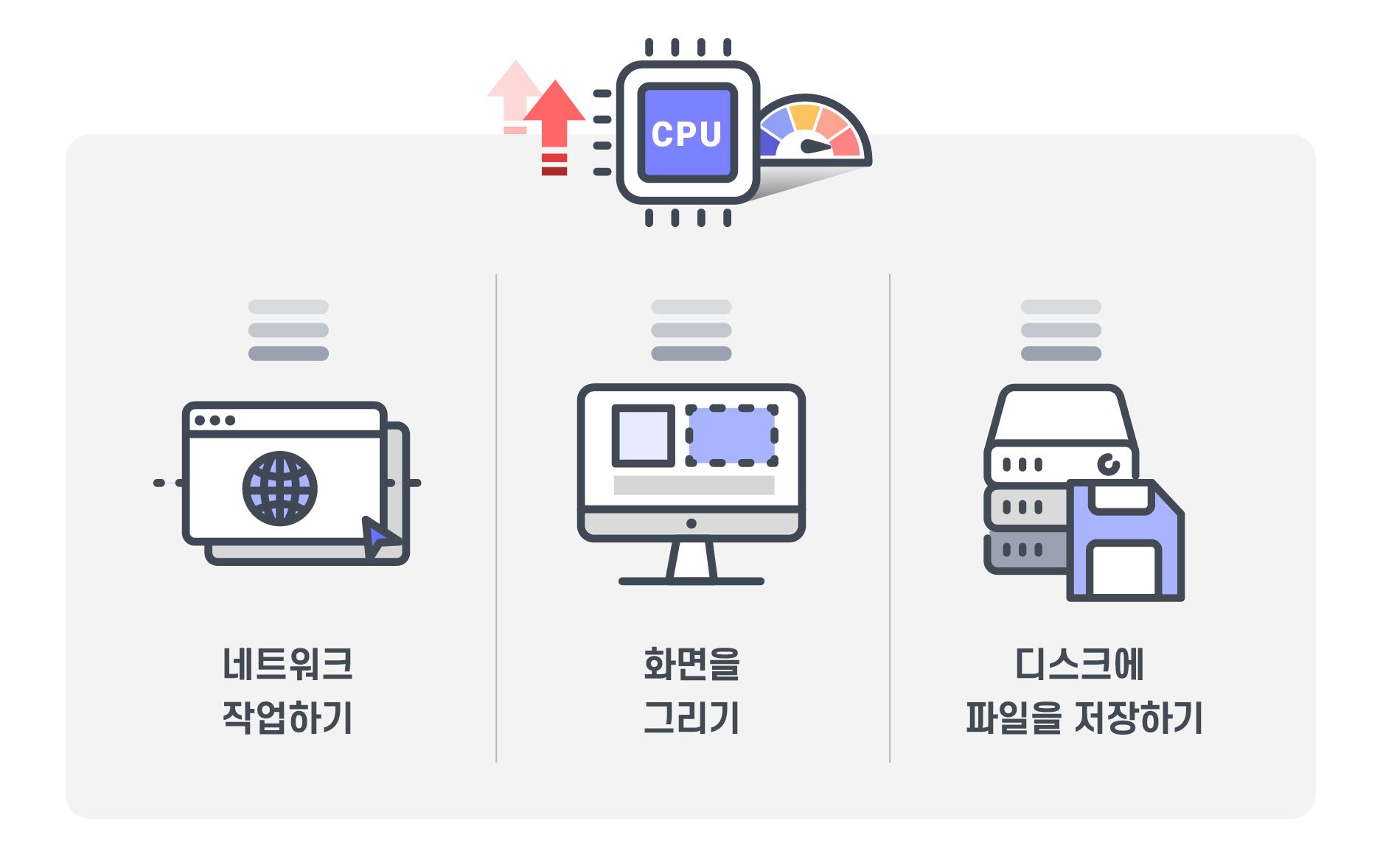
CPU의 사용량은 일을 많이 하면 올라갑니다. 네트워크 작업을 했을 수도 있고, 화면을 그리는 일을 했을 수도 있고, 디스크에 파일을 저장하는 것들 모두 CPU가 해야 하는 일입니다.
CPU의 사용량이 많다면 그때 무엇을 하고 있는지(어느 방에 있는지) 알 수 있도록 스택을 통해 CPU의 행동을 감시하면 어떤 일을 했을 때 CPU사용량이 높아지는 지 알 수 있죠.
3. 내가 원하지 않은 코드가 느리게 만드는지
메모리가 많이 쌓이면 프로그램은 메모리를 비워주는 '혼자서도 잘하는 메모리 청소부 쥐씨(GC)'*를 부릅니다. (GC가 어떻게 동작하는지 잘 모르겠다면, 본문 하단의 영상을 통해 확인해 보세요!)
쥐씨는 메모리 같은 곳을 청소하다 보니 프로그램이 잠시 멈출 때도 있고, 쥐씨가 청소를 하느라 CPU를 과다하게 사용하는 경우도 있습니다. 또 청소해야 할 메모리가 많으면 당연히 성능을 많이 사용하겠죠?
이렇게 내가 짠 프로그램 외에도 OS나, 오픈소스 라이브러리, GC와 같은 무거운 동작이 나도 모르게 동작하기 때문에 꼭 stack을 감시해야 합니다.
IMQA에서 보여주는 Stack
IMQA에서는 크게 MPM에서 보여주는 stack과 Crash에서 보여주는 stack이 있습니다.
가장 먼저 Crash에서 보여주는 stack인데요.
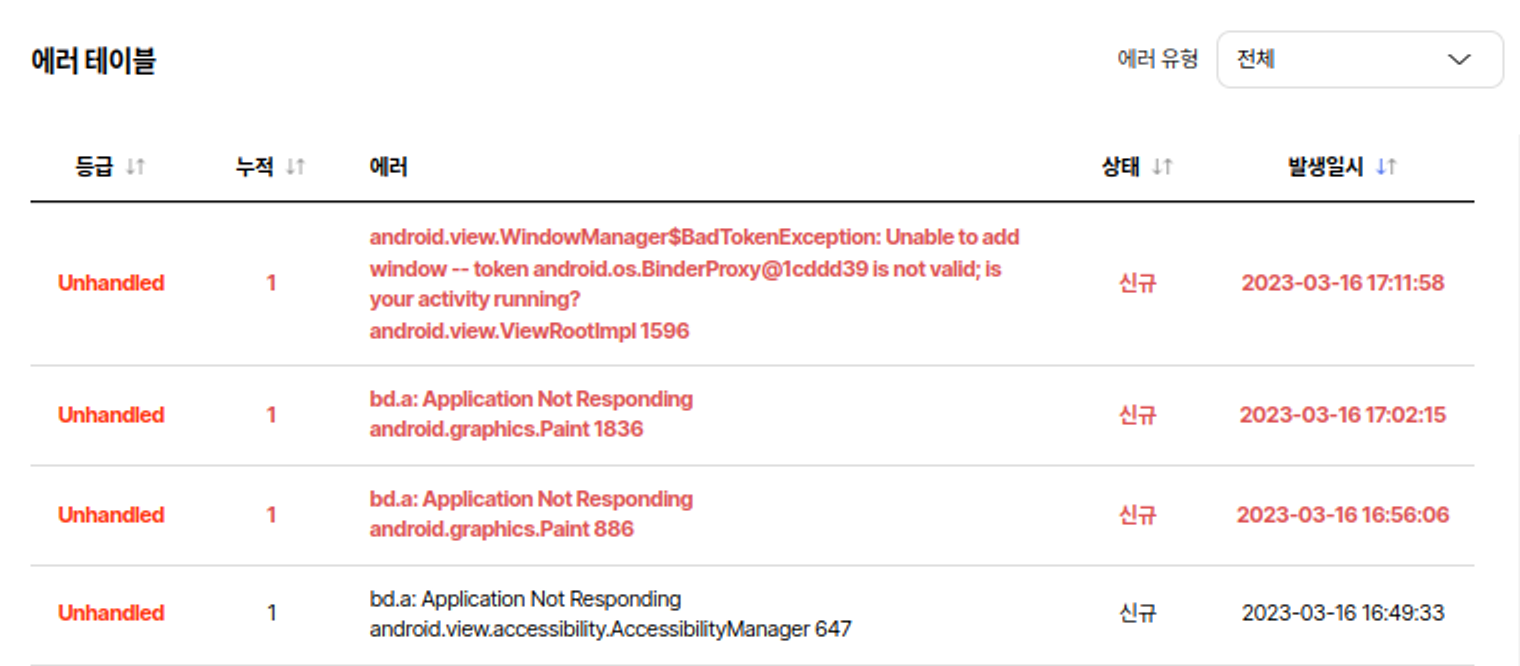
크래시(Crash)라는 용어답게 앱이 꺼졌을 때 stack을 보여줍니다. 마지막으로 방문한 곳에서 문제가 생겨 앱이 꺼졌다면, 문제가 발생한 곳의 방문증을 꺼내오면 되겠죠?
또 ANR과 같이 느린 곳만 특별히 꺼내오는 감시자도 있는데요. CPU가 어느 방에 방문하는지 유심히 보다가 5초 이상 안 나오면 바로 OS한테 일러바치는 녀석입니다.
MPM에서도 stack을 보여주고 있는데요. 기본적으로 CPU가 어떤 작업을 하고 있는지를 알려주는 정보이기 때문에 CPU 리소스에 stack이 저장됩니다.

하지만 우리는 보통 네이티브 화면 로딩시간의 stack을 보고 있죠?
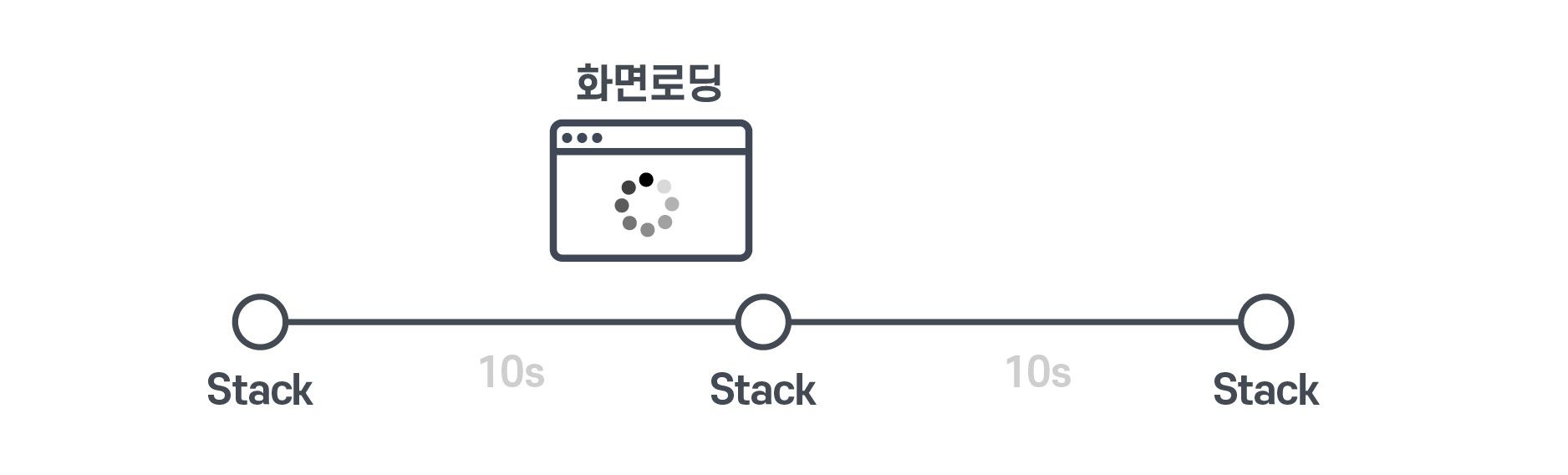
SDK는 우선 기본적으로 수집 주기라는 게 있는데요. 10초에 한 번씩 CPU 정보를 수집하면서 stack을 수집하게 됩니다. 그러다가 어느 순간 화면 로딩이 일어나게 되면, 그때 발생한 stack 정보를 보여주는 것이죠.
하지만 stack을 수집하는 시점과 화면 로딩 시점이 완전히 다르면 어떻게 하죠?
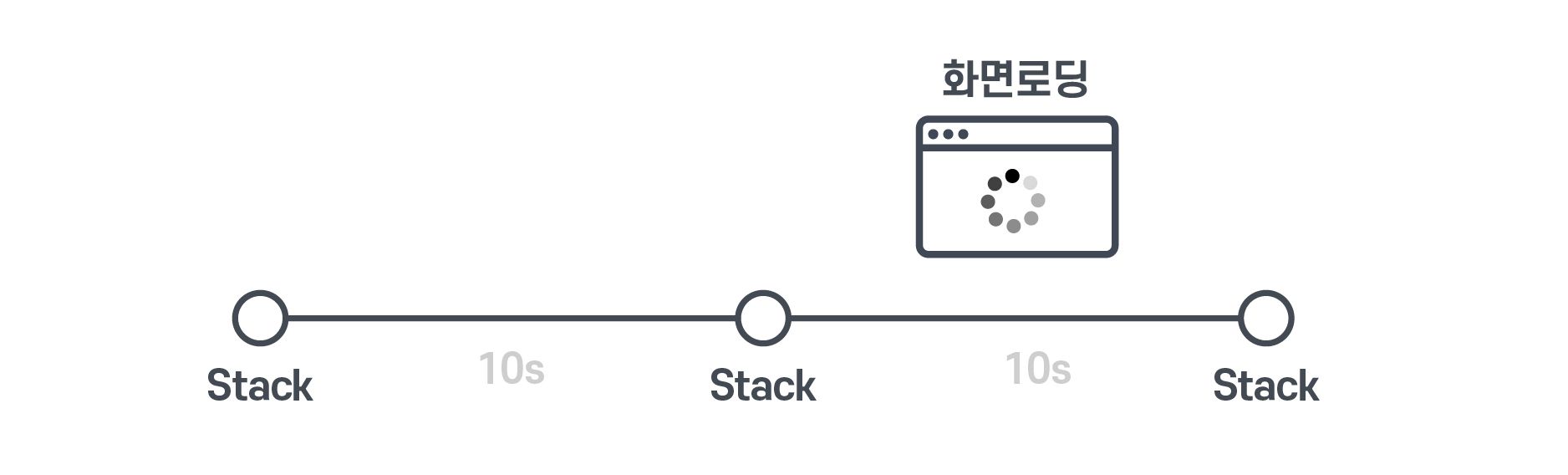
IMQA에서 할 수 있는 쉬운 해답은 stack을 더 촘촘히 수집하는 것입니다.
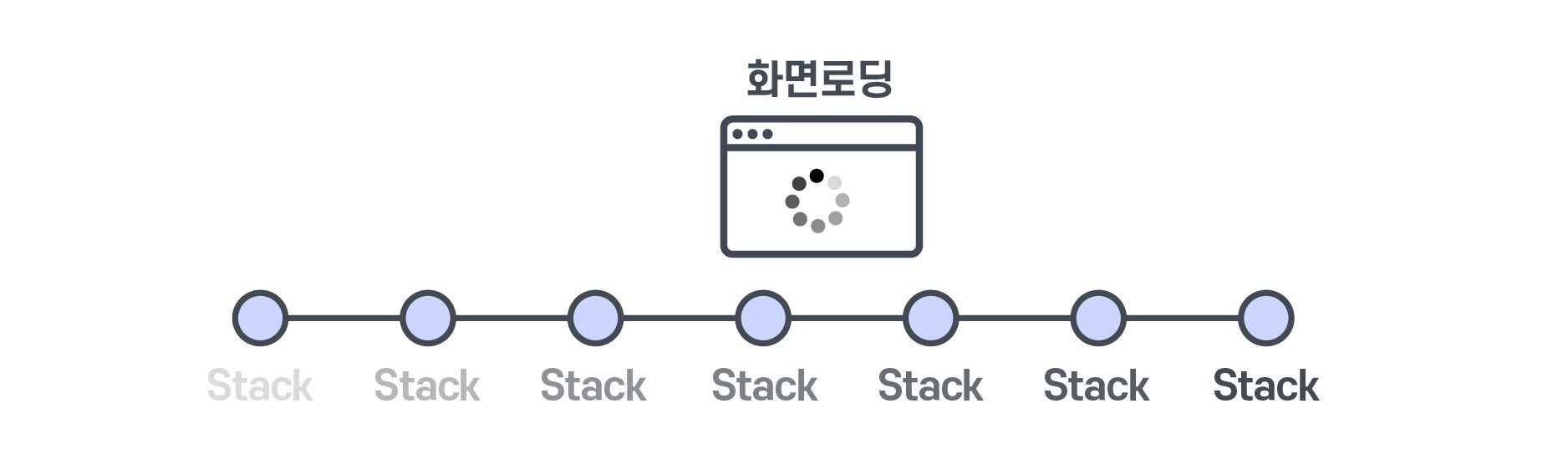
그러면 화면이 로딩될 때 CPU가 무슨 작업을 하고 있는지 우리는 더욱 자세히 감시할 수 있죠!
하지만 이렇게 촘촘하게 할 경우에는 데이터가 너무 많아지는 문제가 발생합니다. 그렇기 때문에 평소에는 기본값을 사용하다가 문제가 발생하면 수집 주기를 더욱 짧게 조정하는 방식을 권장합니다. 또는 더욱 많은 사용자에게 데이터를 수집하여 정확한 문제가 발견될 수 있도록 확률을 높이는 것도 좋은 방법입니다.
마지막으로
IMQA에서는 다양한 형태로 stack을 보여주고 있습니다. 그러나 stack이 익숙하지 않은 분께는 그저 어렵다는 느낌만 주는 낯선 용어일 텐데요. 그래서 stack을 확인해 보시기 전에 stack이란 무엇인지, 무슨 일을 하고, 어떻게 분석할 수 있는지 정리해 보았습니다. 다음번에는 IMQA에서 확인할 수 있는 stack 표기법과 어떻게 확인할 수 있는지 설명해 드리겠습니다.

▼ GC가 어떻게 동작하는지 궁금하시다면, 아래 영상을 확인해 보세요.


