



지난 22년 7월 어니컴은 과기부, 경찰청, 정보통신산업진흥원이 함께 진행하는 'AI 모델 개발 및 실증 사업'을 수주하였습니다. 그래서 사업을 진행하면서 얻은 AI 모델 검증 및 데이터 검증 노하우와 환경 구축을 위한 일련의 과정을 공유드리고자 합니다.
이번 시간은 AI 모델 성능 및 데이터 품질 검증 노하우 시리즈 두 번째 시간으로 AI 모델 검증 환경 구축을 위한 과정 중 데이터 표준화 작업, 학습 데이터 품질 검증 및 가이드, 최종 리포트 발행까지 설명해 드리겠습니다.
데이터 품질의 기준을 마련할 때 고려해야 하는 것들, 그리고 품질을 체크하는 방법에 대한 노하우가 궁금하시다면 꼭 읽어보시길 추천드립니다!
▶️ 1편 다시보기
지표 선정 및 평가 데이터/환경 구축
- 사업의 개요
- 평가 지표 선정
- 평가 프로토콜 구축
- 평가 데이터 구성
- 평가 환경 구축
- 모델 성능 평가 리포트 자동 발급
- 데이터 표준화 작업
- 학습 데이터 품질 가이드
- 학습 데이터 품질 검증
- 최종 리포트 발행
7. 데이터 표준화 작업
여러 컨소시엄이 제작한 데이터를 서로 공유해서 사용하기 때문에 데이터의 표준화가 중요했습니다. 또한 데이터의 품질을 체크하기 위한 기준도 마련해야 했습니다.
데이터 표준화를 할 때 중요한 부분은 필수적 구성요소 (mandatory)와 부수적 구성요소(optional)를 잘 구분하는 것입니다. 3개의 컨소시엄마다 AI 모델을 만드는 전략이 달랐기 때문에 라벨링 방식이 일부 다를 수밖에 없었습니다. 예를 들어 대상 객체를 segementation으로 하는 곳도 있지만, BBox로 진행하기를 원하는 기업도 있었습니다.
컨소시엄 대표와 품질 평가 기관이 모여 데이터 안을 제시하고, 일부 수정사항을 받아들이면서 합의를 이끌었습니다. 그리고 다음과 같은 데이터 표준화 가이드라인을 만들어 공표했습니다.
8. 데이터 품질 가이드
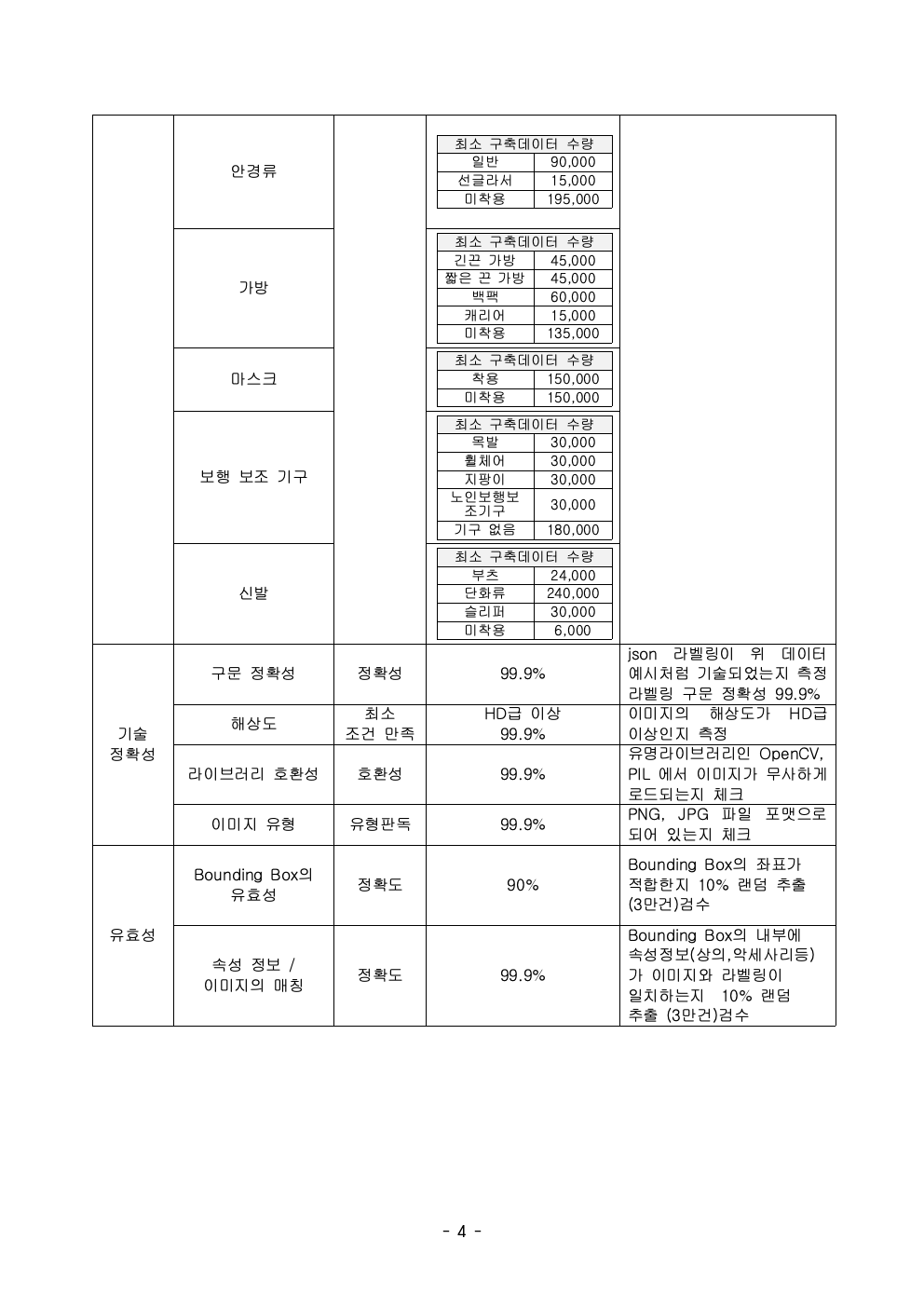
표준화 작업에 이어서 품질에 대한 기준 라인을 만들어야 합니다. 보통 NIA(한국정보화진흥원)의 데이터 생성 사업에서 사용하는 가이드를 준수하시면 됩니다. 몇몇 중요하게 지켜야 하는 품질 속성은 다음과 같습니다.
- 라이브러리 호환성
이미지 같은 경우 OpenCV, PIL과 같은 주요한 이미지 제어 라이브러리에서 잘 열리는지 확인해야 합니다. 이미지의 몇 바이트가 잘려나가더라도 OpenCV는 이미지를 복원해 주는 기능이 있으나 PIL은 그렇지 않습니다. 그래서 두 가지 라이브러리에서 다 열리는지 체크해야 합니다. - 이미지 유사도 측정
최악의 경우, 업체들은 동일한 이미지를 가지고 2~10장 정도의 학습 이미지를 만들었다고 주장할 수 있습니다. 그러면 유사도 몇 % 이상까지 동일한 이미지라고 판단하는 기준이 필요합니다. - 구문 정확성
Json 또는 XML로 라벨링을 할 경우, 라벨링 규칙을 잘 지켰느냐입니다. - 학습 데이터의 이미지 해상도
HD급 이미지에서 액터를 추출할 경우, BBox로 액터의 최소 해상도의 기준은 얼마까지로 볼지 서로 정의해서 협의를 해야 합니다. - 다양성
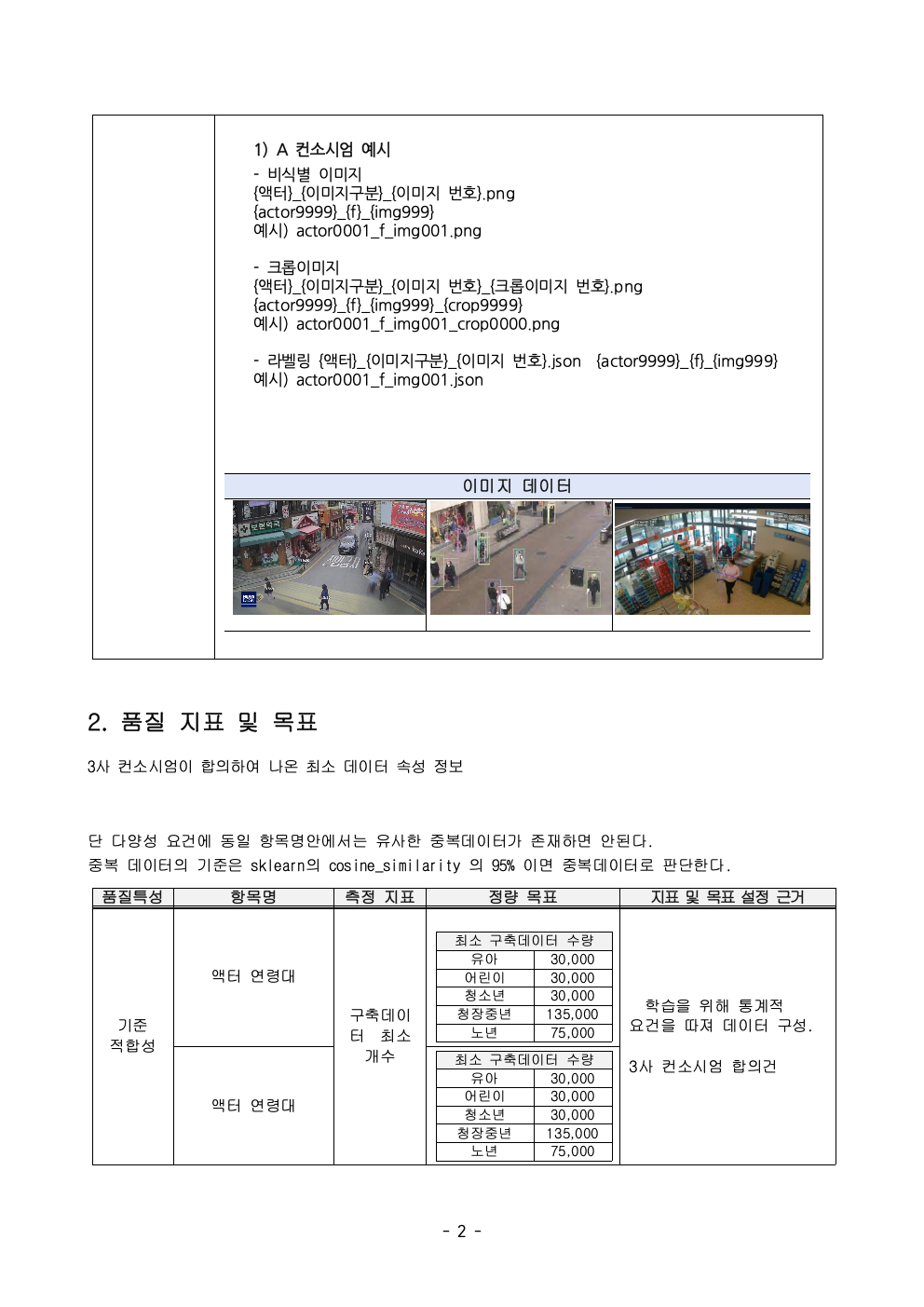
데이터의 다양한 속성의 분포에 대한 기준입니다. 이 사업에서는 실종자의 다양한 옷 유형과 색상 등을 라벨링 해야 하는 최소 기준을 마련했습니다. 통계적 요건으로 각 요소가 (예 상의- 빨간색은 10% 이상) 꼭 지켜야 하는 최소 수량이 있는지 아니면, 자유롭게 수집해도 되는지 기준을 정해야 합니다. - 의미 정확성
실제 라벨링 된 json과 이미지가 과연 1:1 매칭이 되는지 일일이 눈으로 점검하는 작업입니다. 30만 장을 다 눈으로 체크한다면 수십 일이 걸릴 수 있으므로 보통 5 ~ 10% 정도만 랜덤 샘플링해서 육안으로 확인하기도 합니다.
이러한 기준들을 반영해서 다음과 같이 품질 지표 가이드라인을 만들면 됩니다.



9. 학습 데이터 품질 검증
데이터 품질을 체크하는 도구인 자사 솔루션 AIQA를 이용해 의미 정확성을 제외하고 모두 자동화하여 리포트를 추출했습니다.
본 과제의 데이터는 업체의 고유 자료라 외부에 공개할 수 없으며, 어니컴이 참여하는 AIHUB 데이터 생성 과제의 데이터 품질 도출 결과로 대신하여 보여드리겠습니다.
데이터를 파싱 하는 Agent와 화면 구성은 저희가 다 셋업을 해드리니 걱정하지 않으셔도 됩니다. 결과는 AIQA SaaS 서비스를 통해 확인하실 수 있습니다.
이미지 유사도 체크는 많은 분들이 간과하는 영역입니다.
학습 데이터 자체가 편향적으로 될 수 있으므로, 중복된 이미지는 거르는 것이 중요합니다.
데이터 셋에서 중복된 이미지 제거하기 링크를 참고하시길 바랍니다.
이 유사도를 기준으로 인해 AI 모델 기업과 검증 기업 간의 타협점을 찾는 것이 쉽지 않습니다. 동일한 액터가 앞/뒤 모습으로 있긴 하나 실제 걸음걸이, 손동작까지 유사했기 때문에 높은 유사도가 나와 문제를 제기한 컨소시엄이 있었습니다.
반대로 유사도 기준을 너무 낮추면 누가 봐도 거의 동일한 이미지인데 학습 데이터로 볼 수도 있습니다. 결국 엣지케이스를 이야기하면, 누가 봐도 보편타당하게 유사한 이미지를 기준에 만족하는 것으로 하기 때문에, 적절한 합의점을 찾기 위해 외부 공개된 데이터로 기준선을 잡는 것으로 합의했습니다.
AI Hub에서 제공하는 Re-ID(재인식) 이미지 데이터 셋
AIHUB K Re-ID 데이터 셋에서 유사도를 검증하고 측정하고 데이터 제작 기업, 어니컴, NIPA(정보통신 산업진흥원)과 같이 데이터를 기반으로 합의를 진행 했습니다 .
(아래 이미지는 AIHUB K Re-ID의 cctv 촬영본으로 화질이 좋지 않은 점 양해 부탁드립니다.)
95%의 Cosine Similarity




96%의 Cosine Similarity




97%의 Cosine Similarity


물론 더 정확히 측정하기 위해 Pose estimation까지 측정하면 좋겠으나, 여러 데이터를 체크해 보니 Cosine Similarity 95% 까지는 다른 데이터로 보기로 협의를 진행했습니다.
의미 정확성 판독
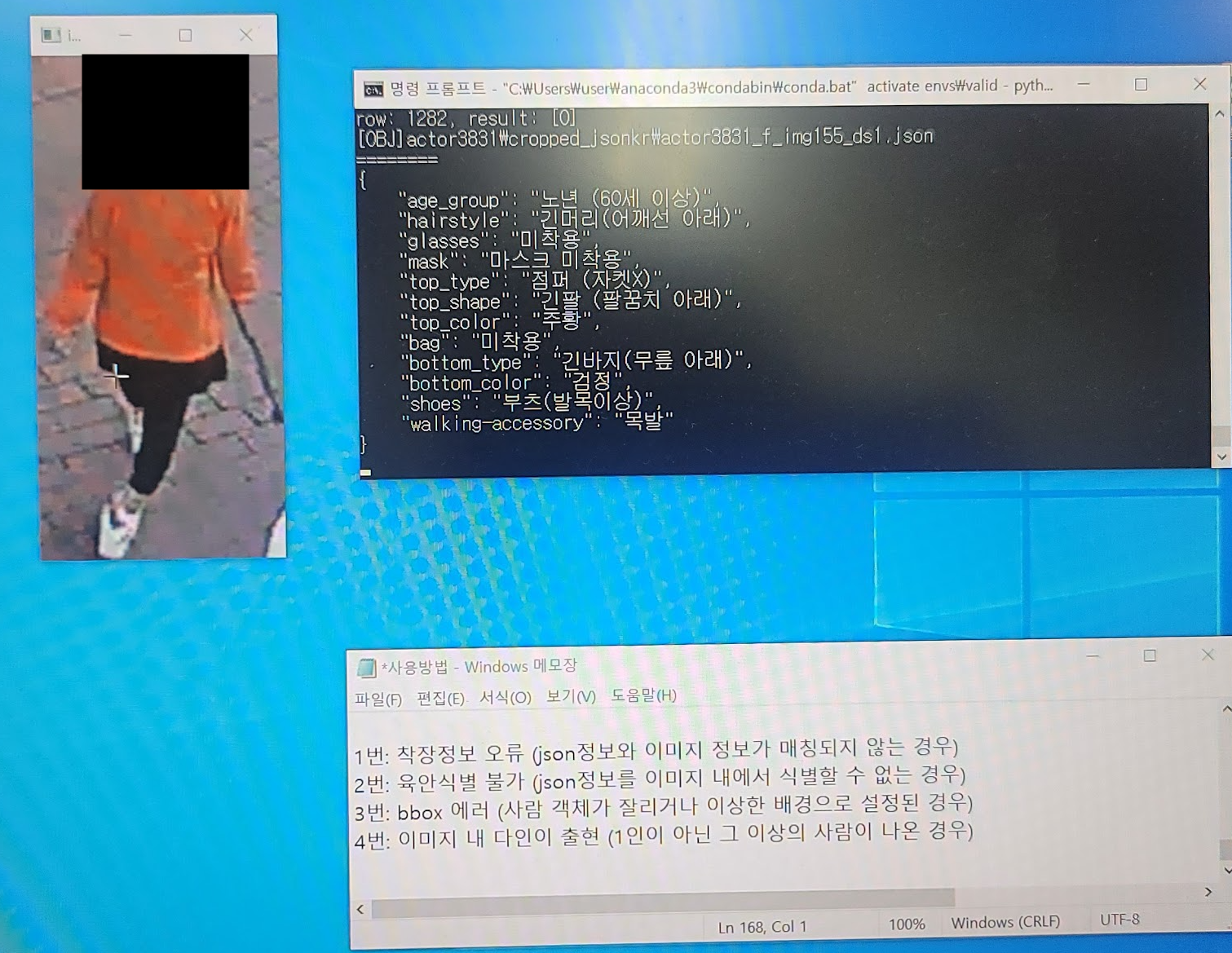
폐쇄망에서 작업을 해야 하다보니, 간단한 Python 프로그램을 개발해서, 키보드만으로 쉽게 데이터를 검수하는 프로그램을 짰습니다. 오프라인에서 폴더별로 특정 갯수만큼 나눠서 눈으로 직접 해당 액터와 라벨링이 맞는지 일일이 대조해서 체크를 진행했습니다. 1,2,3,4번으로 유형을 나눠서 에러들을 키보드로 체크하도록 간단하게 프로그램을 작성했습니다.
10. 최종 리포트 발행
품질 검증 결과에 동의하시면 위 데이터로부터 검증 데이터 리포트를 추출하여, 위에서 언급한 데이터 품질 가이드에 맞추어 리포트를 만들어 제공하게 됩니다. 미진한 부분은 개선할 수 있도록 가이드를 전달드리고 있습니다.
어니컴은 2022년 NIA 데이터 사업에서 4개 사업의 데이터 품질 검증을 수행했습니다. 국민안전사례는 비공개 데이터라 공유드릴 수 없고, 대신 데이터 생성 사업에서 검증한 실 리포트를 공유드립니다. (개별 이미지를 직접 클릭하시면 큰 이미지로 확인하실 수 있습니다.)
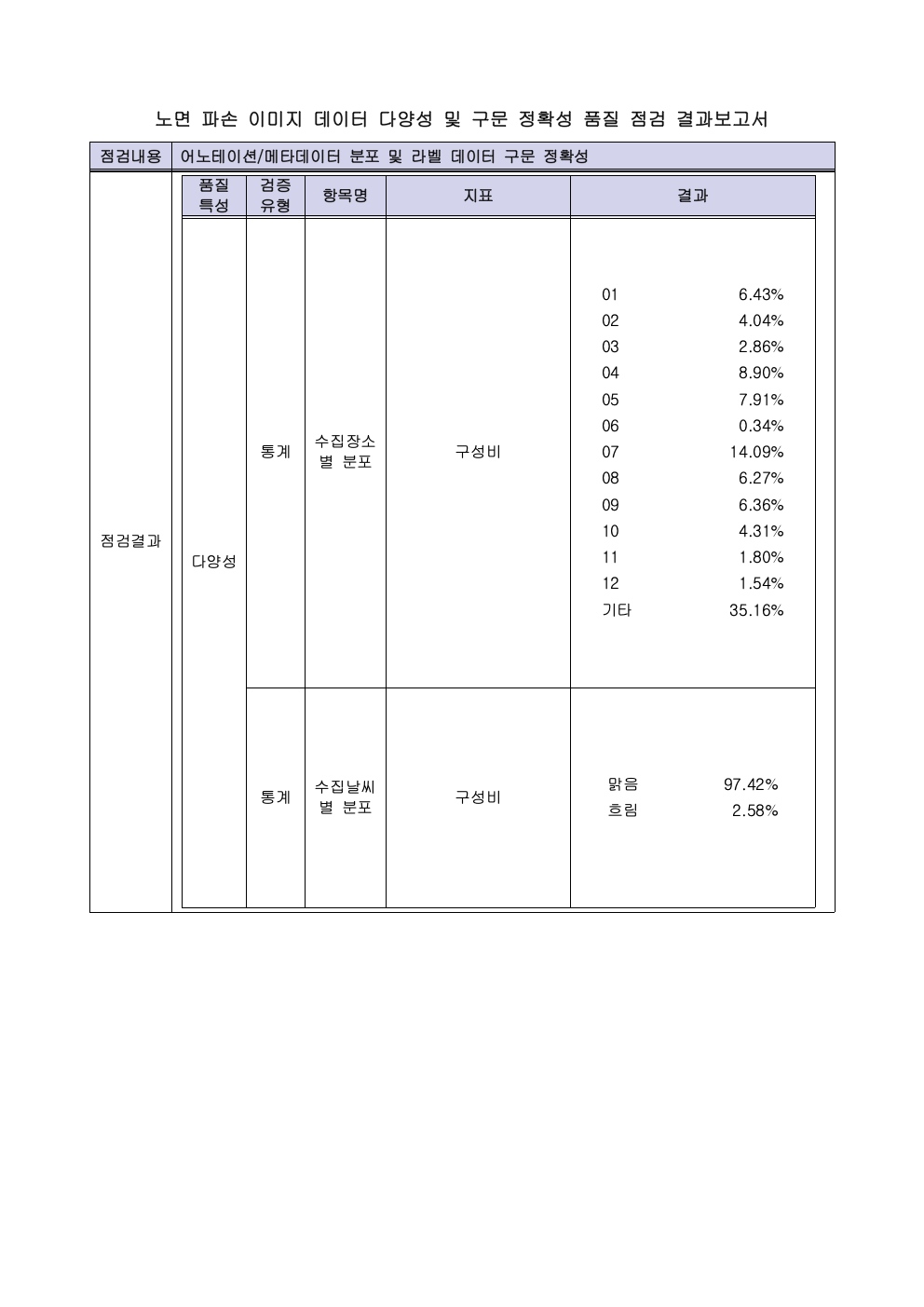
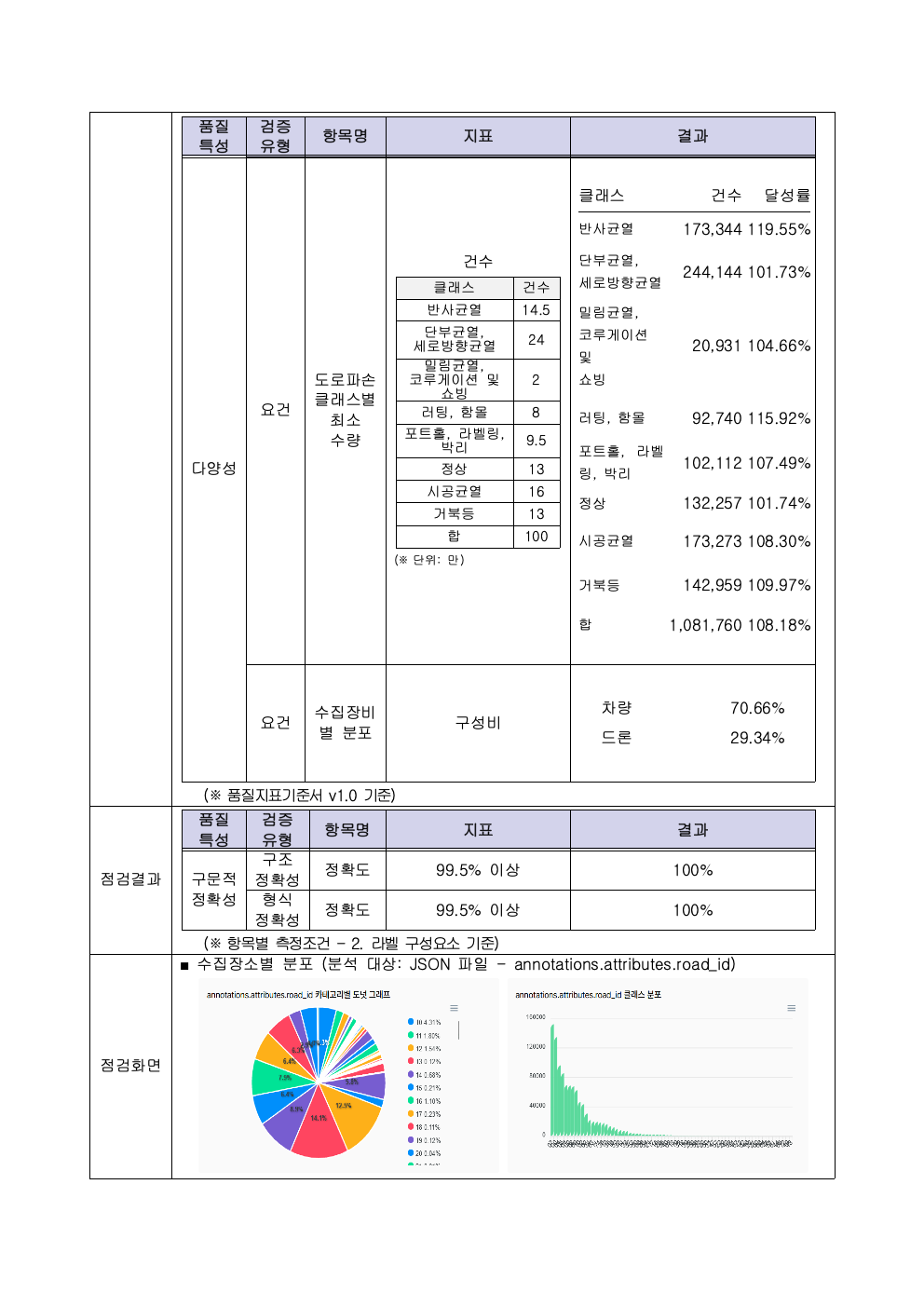
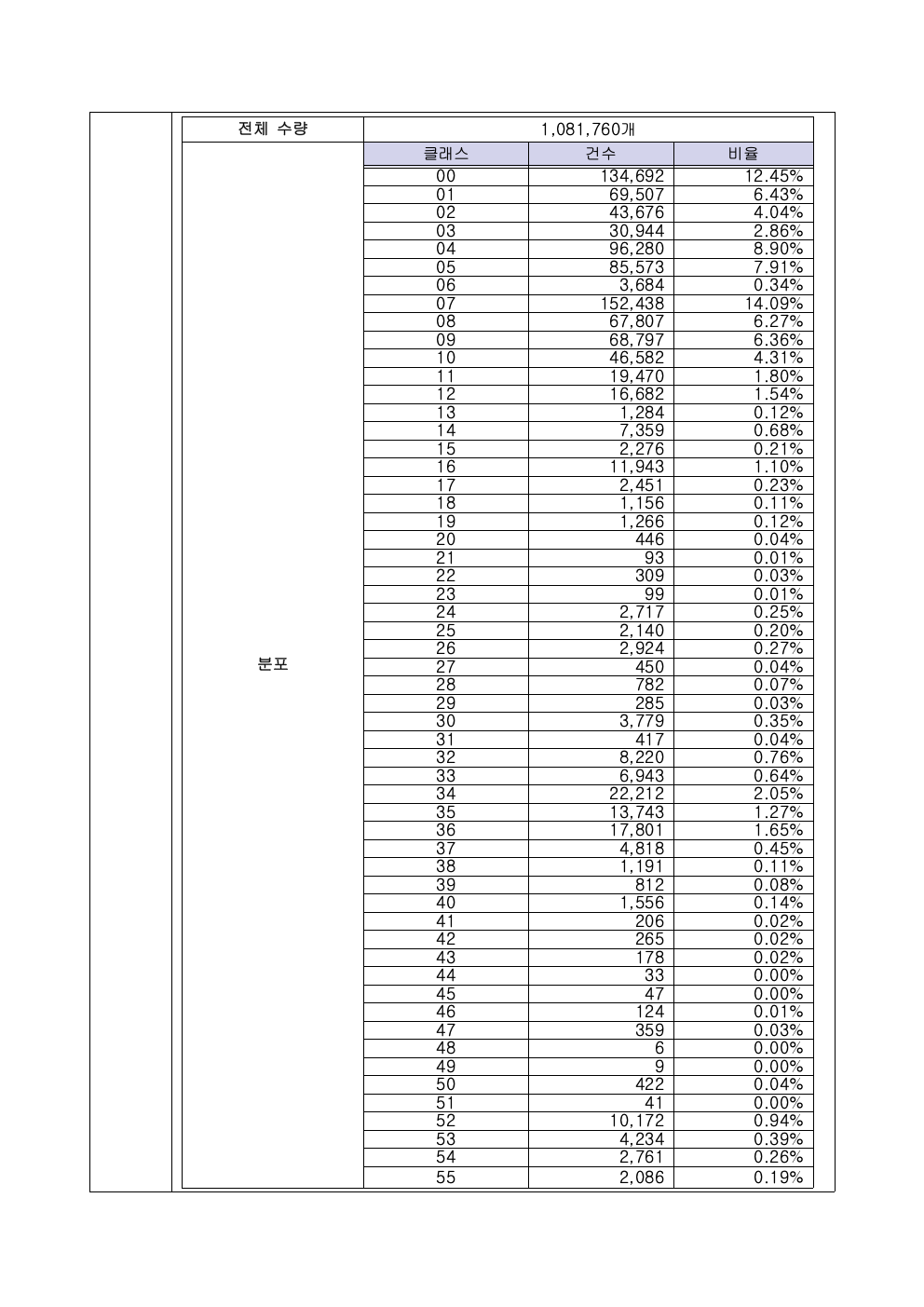
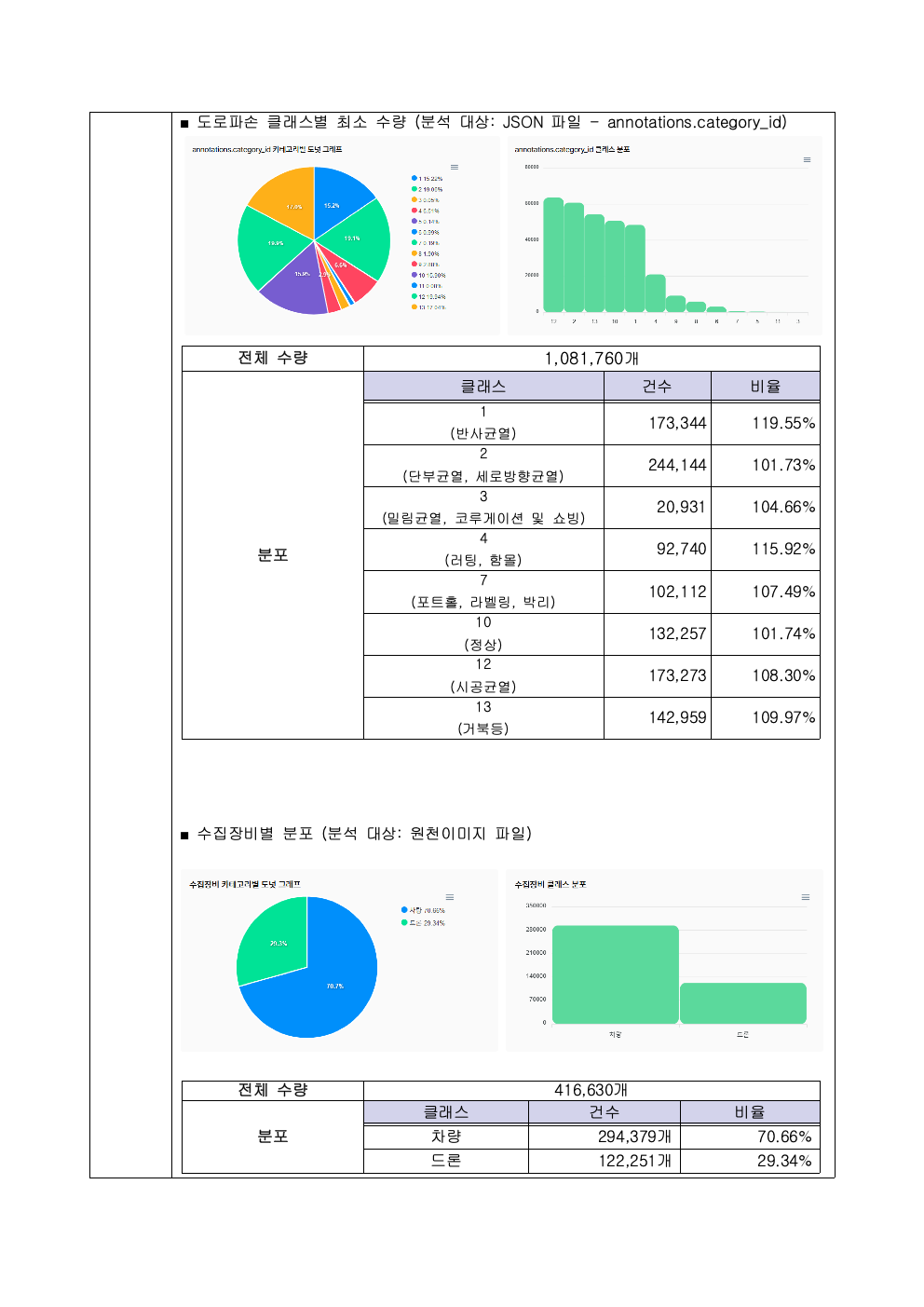
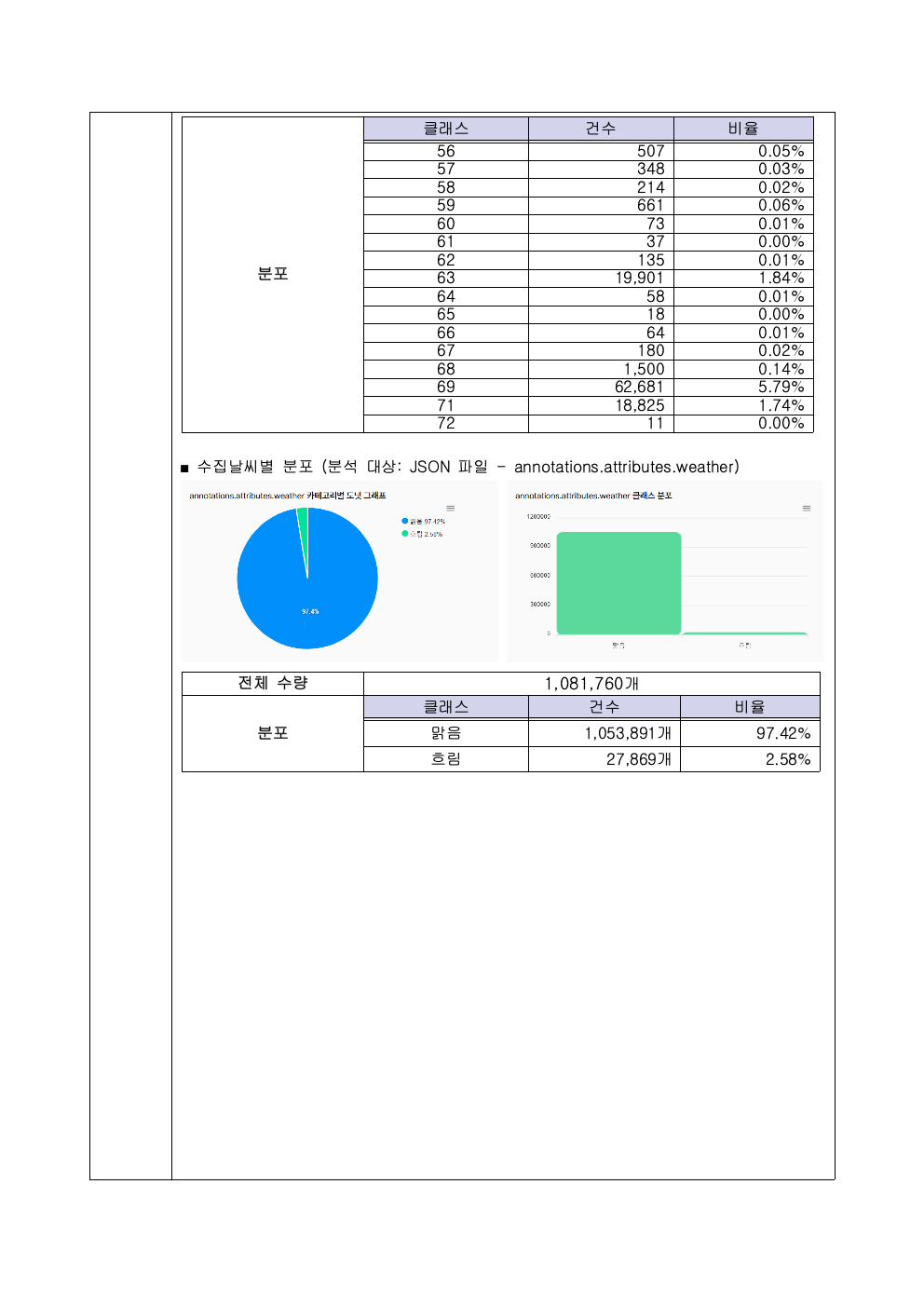
맺으며
어니컴은 이미 다양한 국책 대규모 사업, 민간 기업에서 AI 모델 검증 및 평가, 그리고 데이터 품질 리포트를 제공한 경험이 있습니다. 또한 국내 표준/ 국제 표준을 참여한 경험도 있습니다.
AI 모델 성능 및 데이터 품질 검증 노하우 시리즈가 많은 분들에게 도움이 되기 바라며 글을 맺습니다. AI 성능 테스팅 및 데이터 검증에 대해 궁금하신 사항이 있으시다면 아래로 연락 부탁드립니다.
손영수 ysson@onycom.com /백민경 mkbaek@onycom.com

![[보도자료] 어니컴, 자동차 애프터마켓 카닥에 'IMQA' 공급한다](/content/images/2023/01/1101_Cardoc---.png)