어니컴은 AI 검증 매출 섹터에서, 국내 민간 업계 매출(약 30억) 1위를 달성하고 있는 기업입니다. 법무부 AI 출입국 심사 테스트, 관세청 AI 불법 복제 판독 사업, AI 스피커 음성인식 등 다양한 AI 검증 사업을 수행하고 있는데요. AI 모델 및 데이터 품질을 검증하는 기관으로 데이터 검증에 대한 노하우 및 관련 자체 솔루션을 보유하고 있는 기업입니다.
지난 22년 7월 어니컴은 과기부, 경찰청, 정보통신산업진흥원이 함께 진행하는 'AI 모델 개발 및 실증 사업'을 수주하였습니다. 그래서 이번 시간에는 사업을 진행하면서 얻은 AI 모델 검증 및 데이터 검증 노하우와 환경 구축을 위한 일련의 과정을 공유드리고자 합니다.
총 2편에 걸쳐 포스팅할 예정으로, 첫 번째 글은 사업의 개요부터 모델 성능 평가, 리포트 자동 발급까지 설명해 드리겠습니다.
- 사업의 개요
- 평가 지표 선정
- 평가 프로토콜 구축
- 평가 데이터 구성
- 평가 환경 구축
- 모델 성능 평가 리포트 자동 발급
- 데이터 표준화 작업
- 학습 데이터 품질 가이드
- 학습 데이터 품질 검증
- 최종 리포트 발행
1. 사업의 개요
이 사업은 각 구청에 있는 최소 HD급 이상의 CCTV 수 천대에서 빠르게 실종자를 찾는 AI를 만드는 것이 목적입니다. 개인정보보호 이슈로 별도 용역을 진행하여, 학습 데이터는 각 컨소시엄에서 별도의 액터를 채용하여 학습하고 전부 비 식별화하여 수집을 진행하였습니다.
이 사업의 시나리오는 다음과 같습니다.
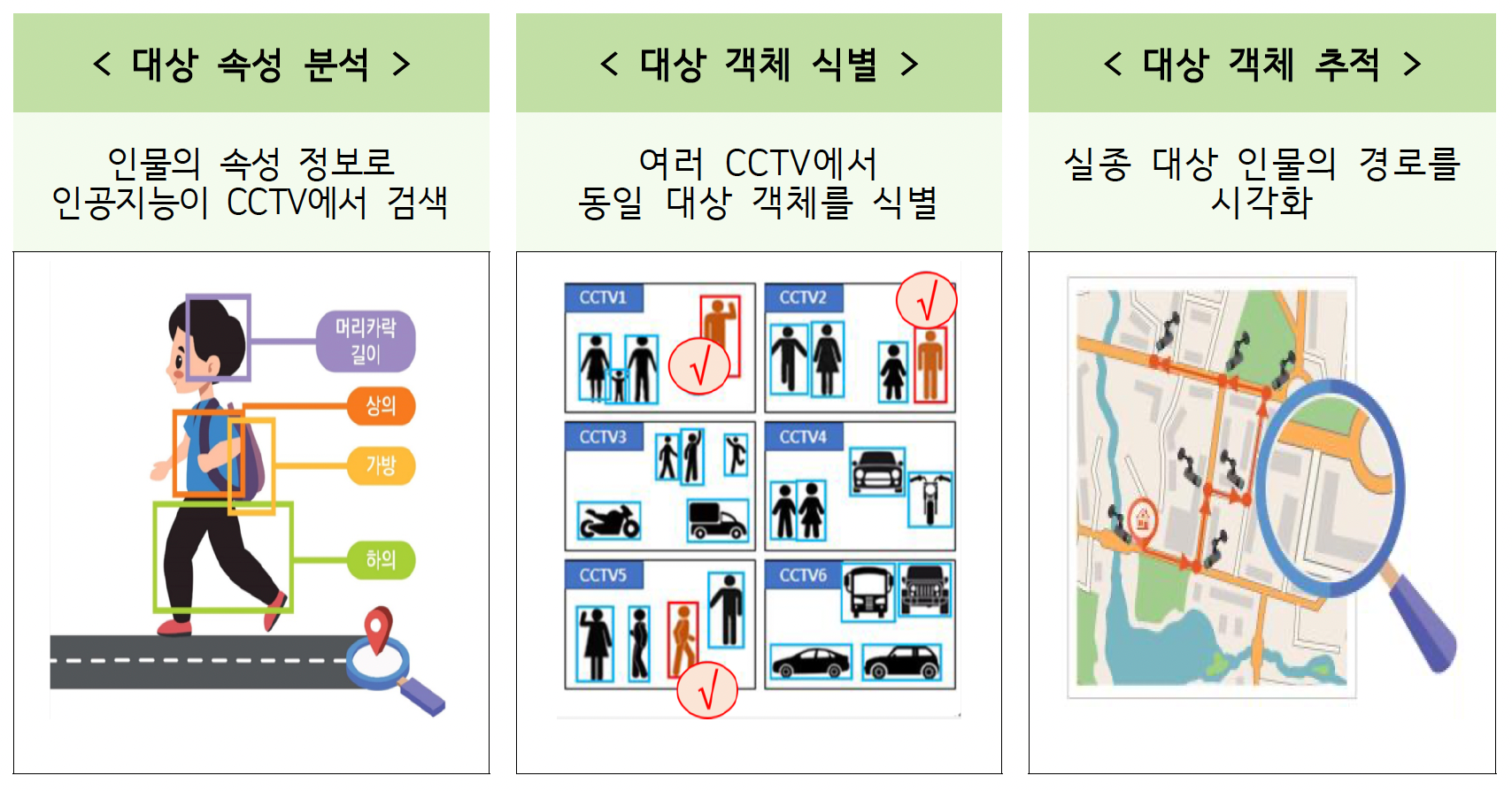
- 대상 속성 분석- 자연어 기반으로 상의는 긴팔 스타일에 흰색, 하의는 반바지 스타일에 초록색과 같은 json 속성 정보를 기반으로 빠르게 후보군 영상을 식별해 냅니다.
- 대상 객체 식별- 위 대상 속성 분석을 통해 찾은 영상에서 실종자를 찾아냅니다. 그 실종자의 이미지를 Crop하여 이미지 기반으로 수천 테라의 영상으로부터 해당 실종자를 빠르게 찾는 것을 검증합니다.
- 대상 객체 추적- 영상으로부터 실종자의 경로를 추적하여 실제 이동한 경로를 맞추는 부분을 진행합니다.
이 사업의 중요한 점은 일반적인 ReID(재인식)와는 접근 방법이 다르다는 겁니다.
동일인을 찾는 문제가 아닌 철저하게 해당 옷과 액세서리 등의 속성만 찾는 방법을 진행했습니다. 그래도 ReID와도 유사한 부분이 있으니 아래 영상을 참고하시길 바랍니다.
2. 평가 지표 선정
적절한 평가 지표 선정, 이 부분이 가장 어려웠습니다. 3개의 컨소시엄이 서로 우위를 겨루어야 하다 보니, 몇 번의 수정을 거쳐야 했습니다. 그리고 최종적으로 다음과 같은 지표가 선정되었습니다.
대상 속성 분석
- 재현율@10(Recall@10): 실제 참인 경우 중 알고리즘이 최대 10개의 후보군 내에서 참으로 예측한 비율

대상 객체 식별
- 재현율(Recall): 실제 참인 경우 중 알고리즘이 참으로 예측한 비율
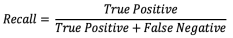
- 정밀도(Precision): 알고리즘이 참이라고 예측한 경우 중 실제 참인 비율

- 조화 평균(F-measure, F1-Score): 두 수치 재현율과 정밀도의 조화 평균

대상 객체 추적
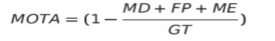
MOTA
객체 추적은 객체 추적률 MOTA (50) + 최종 경로 탐지(50)으로 총 100 합산하여 산출했습니다. 중간 경로를 틀리더라도 최종 실종 지점을 아는 것이 정말 중요하다는 고객의 요구사항을 반영했기 때문입니다.
- 최종 경로 탐지(Final Path): 실종자의 최종 경로(도착점)를 알고리즘이 제대로 탐지한 경우
- 실종자의 경로(GT, Ground Truth): 주어진 질의에 해당하는 실종자의 경로
- 탐지 실패(MD, Miss Detection): 실제 탐지해야 하는 추적 경로 중 알고리즘이 추적 경로를 탐지하지 못한 경우
- 탐지 오류(FP, False Positive): 실제 탐지해야 하는 추적 경로가 없는데 알고리즘이 실종자 추적 경로라고 오탐한 경우
- 매칭 오류(ME, Mismatch Error): 실제 탐지해야 하는 추적 경로 중 알고리즘이 추적 경로를 올바르게 매칭하지 못한 경우
- 객체 추적률(MOTA, Multiple Object Tracking Accuracy): 실제 주어진 질의에 해당하는 실종자 경로(GT)를 올바르게 추적한 비율
대상 객체 추적은 업체들이 오해할 수 있어, 점수 측정 방식을 실제 예를 들어 전달했습니다.
3. 평가 프로토콜 구축
일반적으로 엑셀에서 출력한 결과물로 판단할 수도 있으나, 업체들의 많은 영상을 몇 초 이내에 검색해서 찾아내는지도 중요한 축이기 때문에 API 테스트로 측정을 하였습니다.
json 질의어로 해당 속성을 찾아 검색하는 대상 속성 분석 같은 경우, 어떻게 평가 서버와 통신을 하는지 순서도를 제공하였습니다.
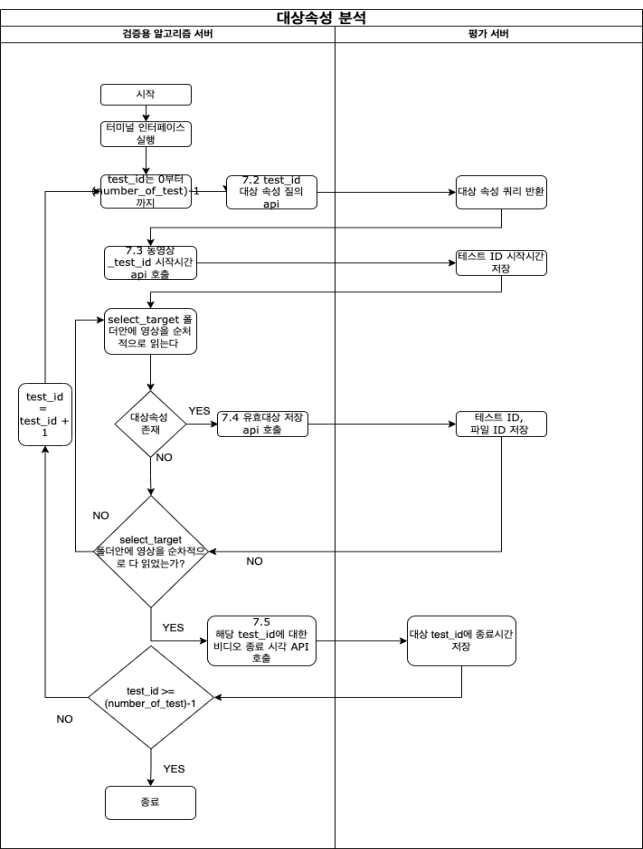
그리고 각 API 호출 시 어떠한 입출력을 주고받는지 정의를 진행했습니다.
한 API의 예를 든다면 아래와 같이 제공합니다.
- HTTP Request: GET
- URL: http://ip:port/select_target/info/{test_id}/{model}
- {model} : 입력 받은 {model} 식별자
- {test_id} : 평가 리스트에서 요청해 결과를 낸 항목 번호, 순차적으로 증가, 0 ~ 9999 (테스트 상황에 탄력적 대체)
- Parameter: 없음
- 예)
http://ip:port/select_target/info/0/onycom_202104141120
- Response:
- Data Type :JSON
- 다음과 같은 형태로 데이터가 전송됩니다.
{
“test_id”:1,
“gender”: “w”,
“age”:“kid”,
“top_type” ; “jumper”,
“top_shape”:“long_sleeve”,
“top_color_pattern”:“red”,
“bottom”: “long_skirt”,
“bottom_color_pattern” : “red”,
“hair”:“long”,
“glasses”:“none”,
“bag”:“none”,
“mask”:“mask”,
“device”:“none”,
“shoes”:“boots”
}
4. 평가 데이터 구성
평가 데이터를 구성하기 위해서는 실 상황과 유사한 데이터를 만드는 게 중요합니다. 우선 서로 간의 기대치를 맞추기 위해서 샘플 데이터 10종을 만들어서 화질, 카메라 각도, 카메라의 화각, 높이 등에 대한 피드백을 받았습니다.

그 결과 적절한 높이, 화질에 대해 3개의 컨소시엄마다 기준이 다르다는 것을 알았으며 이 부분에 대해서 합의를 이루는 과정이 필요했습니다. 그리고 평가 데이터 생성 작업을 진행했습니다.
다양한 색상별, 상의/하의 타입, 액세서리, 가방, 연령대 등을 고려한 액터들을 동원해 데이터 촬영을 진행했습니다. 데이터를 제작하면서 어려웠던 점은 짧은 기간 안에 많은 데이터가 필요했기 때문에 2~3달에 걸쳐 평가 영상을 제작해야 했다는 것이고, 사람의 액세서리가 명확하게 보일 수 있게 촬영해야 한다는 것입니다.

또한, 일반인을 동의 없이 찍는 것은 불법이므로 개인 정보 보호 이슈가 없도록 사전 동의를 받고 액터가 나오는 영상만 촬영을 해야 한다는 점이 어려웠습니다. 영상을 찍다가 일반인이 나오면 다시 촬영해야 하는 이슈도 있었습니다.
그리고 일반적인 ReID (재인식)과 다르게 얼굴을 비 식별화된 상황에서 철저하게 상하의 색상, 타입, 액세서리, 가방, 보조 기구(휠체어, 목발 등) 만으로 후보 대상을 식별하고 찾을 수 있는 평가 방안에만 집중을 했습니다.
개인정보 이슈로 샘플 데이터를 보여드릴 수 없음을 양해 부탁드리며, 2023에는 제가 꼭 액터로 참여해서 몇 개의 이미지와 영상을 오픈해 드릴 수 있도록 하겠습니다.
5. 평가 환경 구축
평가 의뢰 기관은 평가 기관에게 국민안전 확보 및 신속 대응 AI 모델을 설치하기 위해 필요한 정보를 제공해야 합니다. 정보란 설치하기 위한 방법뿐만 아니라 설치에 필요한 환경 정보, 기타 특이 사항 등을 포함해야 합니다.
설치 방법
설치 방법에는 기본적인 명령어 외에 기타 관련된 제약 사항 등을 명시해야 합니다. 예를 들어 특정한 경로에 설치해야 하는 제약 사항, 경로명에서 한글 제외 등이 있을 수 있습니다.
운영체제 환경 정보
운영체제는 Ubuntu 20.04 LTS 또는 Windows 10(latest version) 중 선택을 권해드립니다.
※ 필요한 운영체제 라이센스는 성능 평가 의뢰 기관에 전달해야 합니다. 본 과업이 종료된 이후에 운영체제 설치 관련 도구는 다 원 소유자에게 반환합니다.
하드웨어 스펙 정보
| 구분 | 서버 스펙 |
|---|---|
| 운영체제 | 리눅스, 윈도우 |
| CPU | 인텔 제온 12코어, 2.2GHz |
| 메모리 | 256GB |
| GPU | RTX2080Ti Turbo 11GB |
| GPU 수량 | 2 |
| SSD | 512GB |
| 네트워크 | 1Gbps / 100MHz |
물리적인 보완 환경 꾸미기

컨소시엄 간에 모니터가 서로 공유되지 않도록 별도의 공간을 제공하고, 더불어 테스트 공간은 별도의 인터넷이 되지 않는 폐쇄 공간을 만들어서 진행했습니다.
업체들마다 할당받은 자유공간(인터넷 가능 환경)에서 모델을 설치하고, 폐쇄망에 서버를 반입하는 순간 사전 프로토콜 데이터, 테스트 평가 데이터를 설치하고 바로 테스트를 하는 형태로 진행했습니다.
테스트 룸에 반입한 경우, 오로지 포맷을 진행해야만 반출이 가능하도록 진행했습니다. 평가 데이터 유출이 민감한 문제이므로, 철저한 보안 환경에서만 진행했습니다.
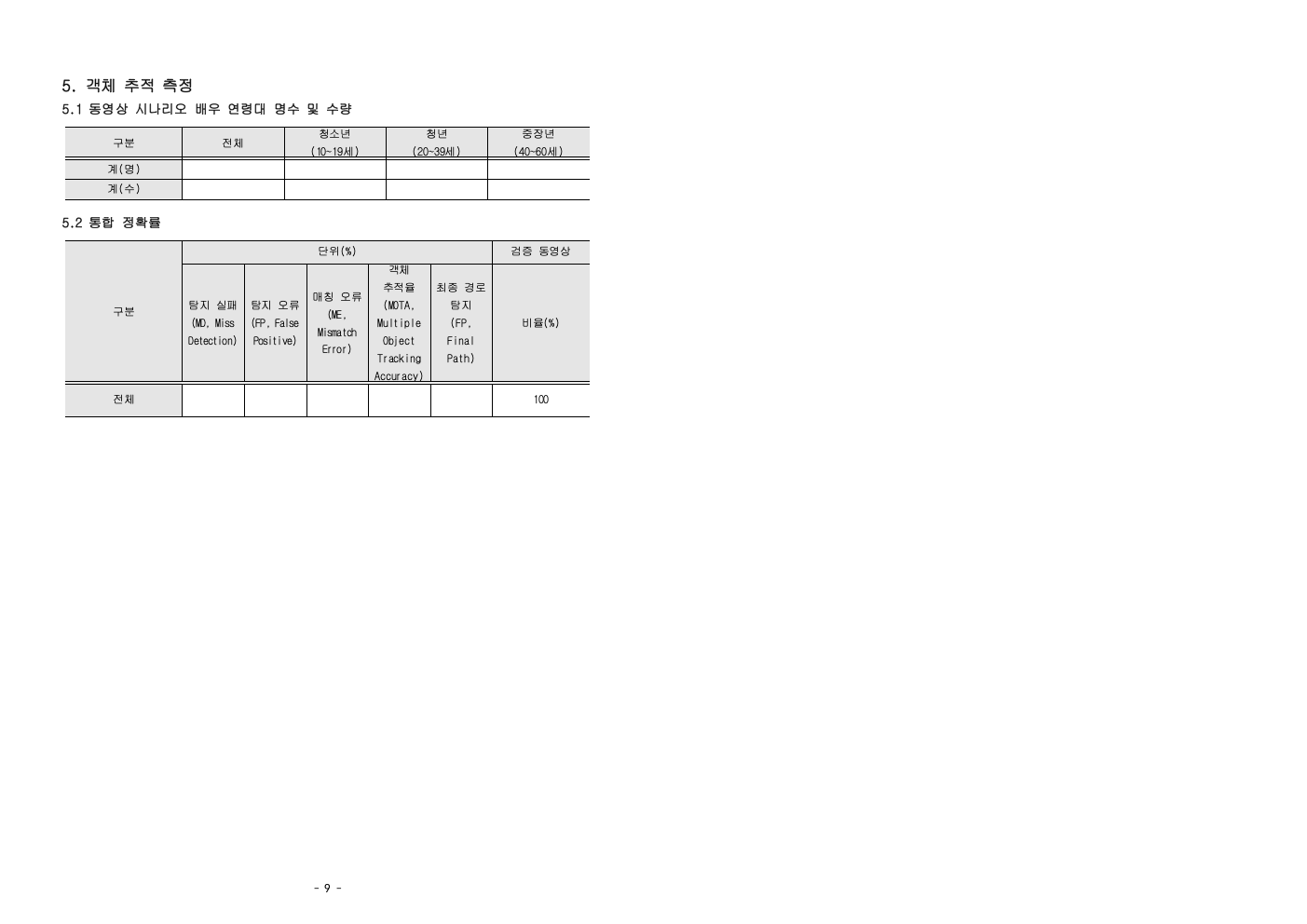
6. 모델 성능 평가 리포트 자동 발급
성능 평가 리포트를 만들 때 2가지를 고려해야 합니다.
- 빠른 테스트 결과 반환
- AI 모델의 취약점을 알려주는 정보 제공
결국 데이터를 기반으로, 평가를 받기 때문에 평가 데이터 구성을 미리 고려해서 만들어야 합니다. 상의에서 못 맞추는지, 하의에서 못 맞추는지, 특정 색상에서 못 맞추는지 알려주기 위해선 라벨링이 세분화되어 있어야 합니다.
평가 데이터가 문제의 난이도를 조정하는 측면, 균등 분포로 알고리즘의 약점을 드러내는 측면도 중요하나 빠른 피드백을 위한 평가 프로그램과의 연동성도 매우 중요합니다. 평가 리포트 템플릿을 만들어서, 어떻게 모델의 장점과 약점을 보여줄지 AI 모델 업체들과 협의를 하여, 리포트 템플릿을 만들면 됩니다. 리포트의 상세한 내용을 확인하시려면 개별 이미지를 클릭하시면 됩니다.




맺으며
다음 글에서는 데이터 품질의 기준을 마련할 때 고려해야 하는 것들, 그리고 품질을 체크하는 방법에 대한 노하우를 전달해 드리겠습니다. 계속되는 AI 모델 성능 및 데이터 품질 검증 노하우 시리즈를 기대해 주시기 바랍니다.
AI 테스팅 및 데이터 품질 검증에 대해 궁금하신 사항이 있다면 아래로 연락 부탁드립니다.
손영수 ysson@onycom.com /백민경 mkbaek@onycom.com