



이 글은 우버 기술 블로그인 Engineering Failover Handling in Uber’s Mobile Networking Infrastructure를 의역(https://eng.uber.com/eng-failover-handling/) 한 글입니다. 번역하는 과정에서 오역이나 매끄럽지 못한 부분이 있을 수 있습니다. 문의 사항은 support@imqa.io로 주시길 바랍니다. 원제는 모바일 네트워킹 인프라의 페일오버 엔지니어링이나, 이것보다는 엣지 클라우드 + 멀티 클라우드 페일오버 엔지니어링이라는 것이 더 쉽게 이해할 수 있을 것 같아 부득이하게 이렇게 번역을 하였습니다.
수백만 명의 사용자가 매일 전 세계에서 Uber의 애플리케이션을 사용하고 있으며, 버튼 하나만 누르면 원활한 이동이나 식사 배달을 사용할 수 있습니다. 규모에 맞게 이러한 접근성을 실현하기 위해서는 고객이 서비스를 사용하는 장소에 관계없이 지연 시간이 짧고 신뢰성이 높은 네트워크 통신이 필요합니다.
Uber의 모든 모바일 애플리케이션을 위한 네트워크 통신은 에지 및 모바일 네트워킹 인프라에 의해 구동됩니다. Edge 인프라는 모바일 앱에서 발생하는 HTTPS 트래픽을 백엔드 서비스로 안전하게 연결합니다. Uber의 Edge 인프라는 퍼블릭 클라우드의 글로벌 인프라와 자체 데이터 센터가 결합되어 있습니다. 퍼블릭 클라우드는 앱 지연 시간을 줄이는 데 사용되며, 향상된 안전성이 요구될 때는 자체 데이터 센터로 폴백(대체) 할 수 있습니다.
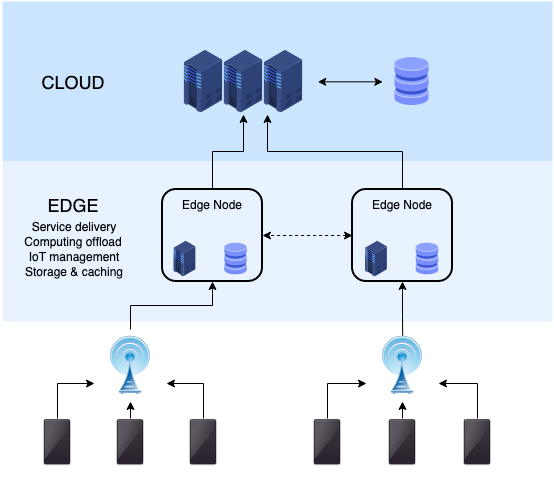
그림 1. Edge Computing의 예
모바일 측면에서, 네트워킹 스택의 핵심 구성 요소는 모든 모바일 트래픽을 애플리케이션에서 Edge 인프라로 지능적으로 라우팅하는 장애 처리 핸들러(failure handler)입니다. Uber의 장애 처리 핸들러는 클라우드 인프라를 통해 전송되는 트래픽이 최대화되도록 FSM (Finite State Machine)으로 설계되었습니다. 클라우드 인프라에 연결할 수 없는 경우 장애 처리 핸들러는 사용자 경험에 큰 영향을 주지 않고 Uber의 데이터 센터로 직접 트래픽을 동적으로 다시 라우팅합니다.
Uber에서 장애 처리 핸들러를 배포한 후 이전 솔루션과 비교했을 때 HTTPS 트래픽의 테일 엔드 지연 시간이 25-30% 감소했습니다. 장애 처리 핸들러는 퍼블릭 클라우드 인프라에서 발생하는 운영 중단되는 기간 동안 HTTPS 트래픽에 대한 오류율이 상당히 낮도록 보장합니다. 이러한 성능 향상으로 인해 전 세계 시장에서 더 나은 사용자 경험을 제공할 수 있게 되었습니다.
이 기사에서는 Uber 애플리케이션을 위한 모바일 장애 조치 핸들러를 설계할 때 직면한 도전과제와 전 세계 사용자를 대상으로 시스템을 운영하면서, 어떻게 설계(디자인)가 발전했는지에 대해 설명합니다.
우버의 엣지 인프라스트럭처
Uber의 Edge 인프라는 모바일 앱에서 TCP 또는 QUIC 연결을 통한 보안 TLS를 종료하는 프런트 엔드 프록시 서버로 구성됩니다. 이러한 연결을 통해 모바일 앱에서 발생하는 HTTPS 트래픽은 기존 연결 풀을 사용하여 가장 가까운 데이터 센터의 백엔드 서비스로 전달됩니다. Edge 인프라는 퍼블릭 클라우드 지역과 Uber의 관리되는 데이터 센터 모두에서 호스팅 되는 프런트 엔드 프록시를 통해 아래의 그림 1과 같이 퍼블릭 클라우드 및 프라이빗 관리 인프라 전반에 걸쳐 구축됩니다.
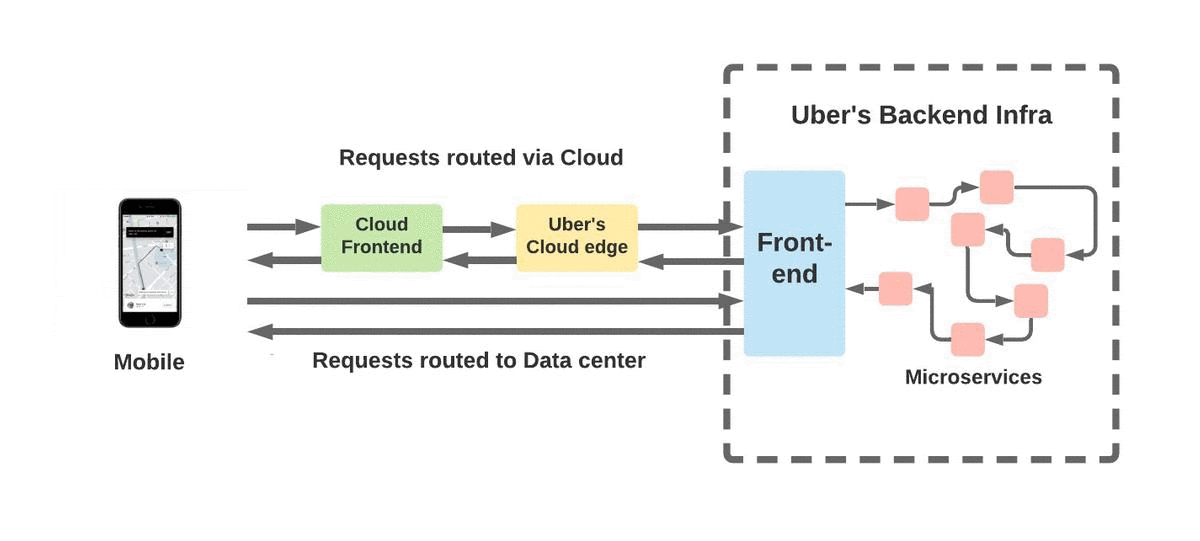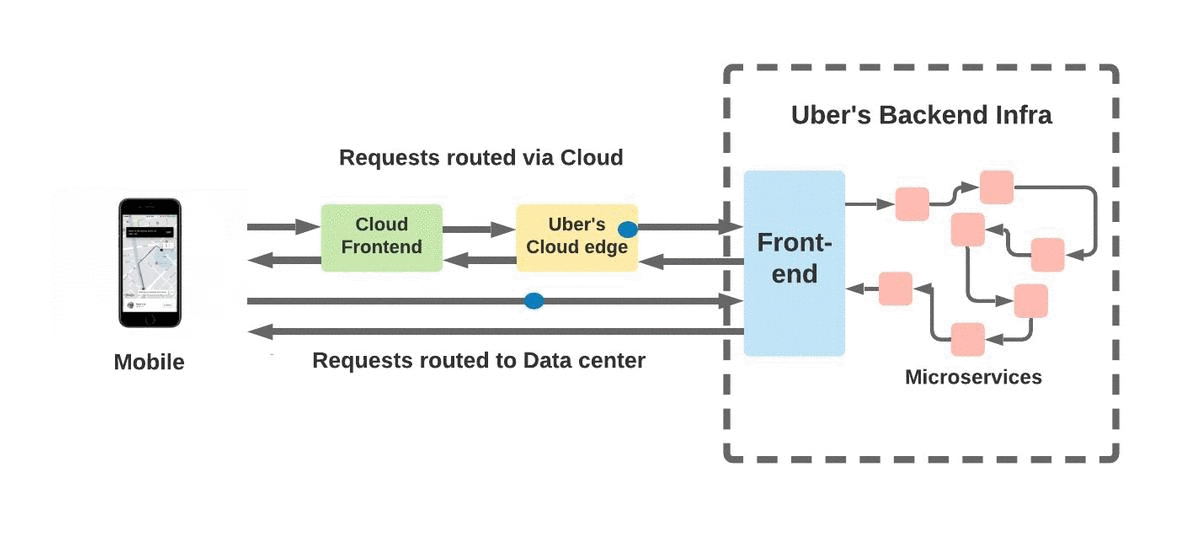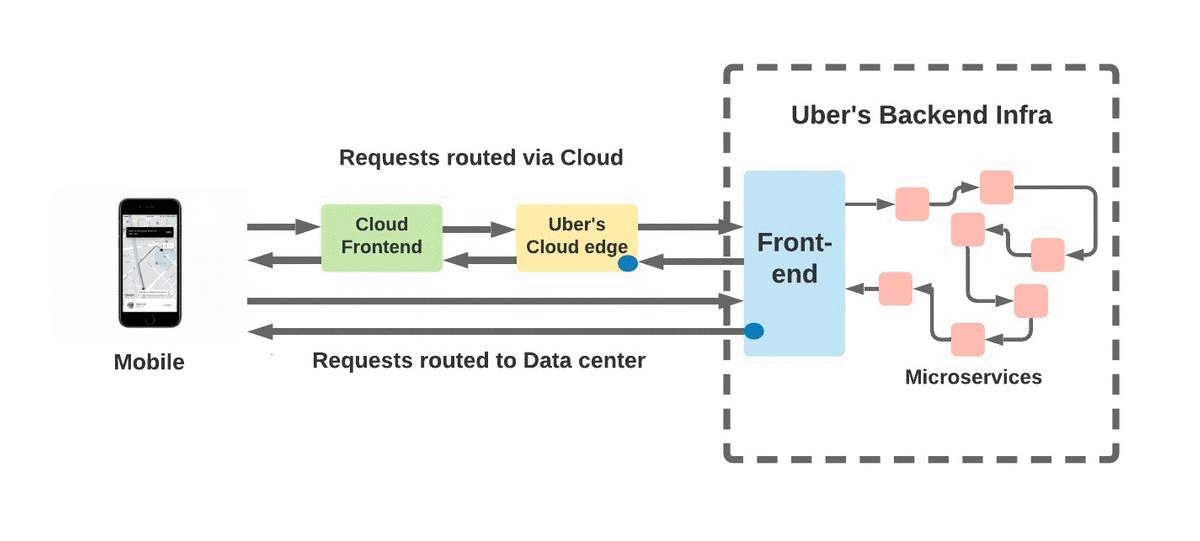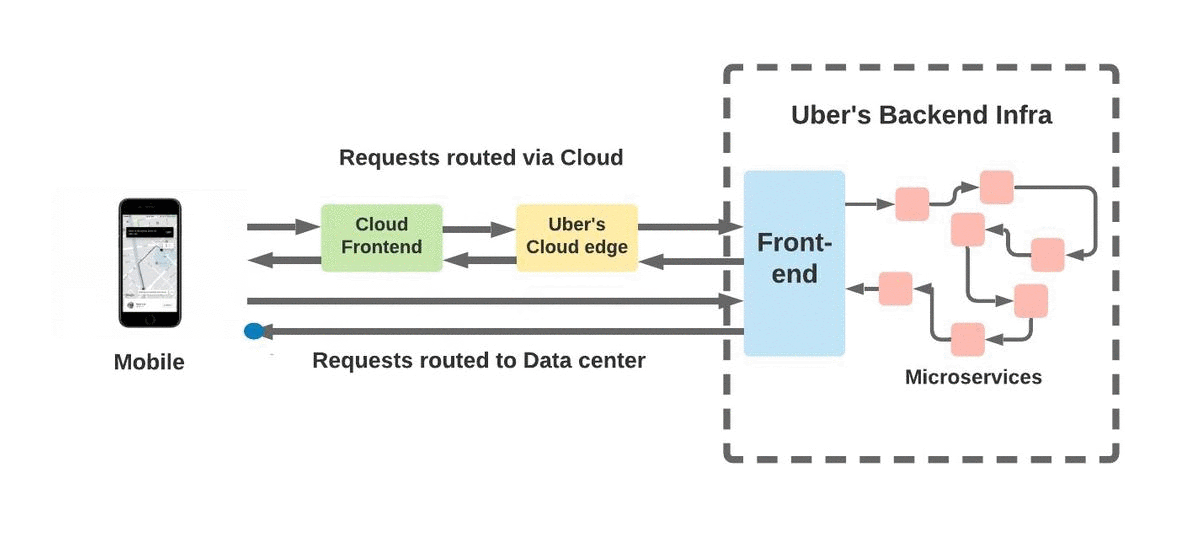 그림 2. Uber의 Edge Infra는 클라우드 인프라를 통해 또는 Uber의 관리 데이터 센터로 직접 모바일 트래픽을 라우팅하여 모바일 애플리케이션의 신뢰성을 보장합니다.
그림 2. Uber의 Edge Infra는 클라우드 인프라를 통해 또는 Uber의 관리 데이터 센터로 직접 모바일 트래픽을 라우팅하여 모바일 애플리케이션의 신뢰성을 보장합니다.
퍼블릭 클라우드에서 Edge 서버를 호스팅 하면 널리 배포된 PoP (Points of Presence) 네트워크를 활용할 수 있습니다. QUIC / TCP 연결을 사용자에게 더 가까운 곳에서 종료하면 일반적으로 성능이 향상되어 HTTPS 트래픽에 대한 지연 시간과 오류율이 낮아집니다. 또한 클라우드의 프런트엔드 서버는 열악한 네트워크 상태에서 대기 시간을 더욱 줄여주는 새롭고 성능이 뛰어난 프로토콜을 지원합니다. 따라서 최상의 사용자 경험을 보장하기 위해 클라우드 지역을 통해 라우팅 되는 모바일의 HTTPS 요청 양을 최대화하는 것이 중요합니다.
그러나 앱 요청이 항상 클라우드로 라우팅 되는 경우 로컬 및 글로벌 레벨 운영 중단이 발생할 위험이 있습니다. 이러한 연결 문제는 퍼블릭 클라우드 또는 중간 ISP의 다양한 구성 요소로 인해 발생할 수 있습니다. DNS 서비스, 로드 밸런서, BGP 라우팅, 네트워크 미들 박스의 잘못된 구성, 클라우드 중단 등으로 인한 문제로 인해 DNS 또는 QUIC / TCP 연결 시간 초과가 발생할 수 있습니다. 운영 중단이 발생하면 Uber의 플랫폼은 동적으로 페일오버를 수행하고 들어오는 요청을 사설 데이터 센터로 재 라우팅하여 중단 없는 서비스를 보장할 수 있어야 합니다.
클라우드에서 호스팅 되는 프런트 엔드 서버와 데이터 센터는 서로 다른 도메인 이름으로 등록됩니다. 모바일 앱은 가장 적절한 도메인 이름을 선택하여 요청을 클라우드 리전 또는 Uber 데이터 센터로 직접 라우팅할 수 있습니다.
모바일 페일오버 핸들링
사용자의 고성능 및 안정적인 애플리케이션 환경을 지원하기 위해 핵심 HTTP2/QUIC 계층 위에 배치된 인터셉터로 모바일 네트워킹 스택에 상주하는 인 하우스 Failover Handler(장애 조치 처리기)를 구축했습니다. HTTPS 요청은 응용 프로그램에서 생성되면 Failover Handler를 통과하여 코어 HTTP 라이브러리에서 처리되기 전에, 도메인 이름(또는 호스트 이름)을 다시 씁니다. 이를 통해 HTTPS 트래픽을 적절한 Edge 서버로 동적으로 라우팅할 수 있습니다.
비동기적으로, Failover Handler는 도메인의 상태를 지속적으로 모니터링하고 HTTPS 응답으로부터 수신된 오류를 기반으로 필요한 경우 도메인을 전환합니다. 도메인 전환 시기를 결정하는 로직은 페일오버 처리기의 핵심 구성 요소이며 이 문서의 주요 주제입니다.
Failover Handler는 HTTPS 응답에 대한 네트워크 오류를 도메인과의 연결성(도달이 가능한지 감지) 문제를 감지하는 신호로 사용합니다. Failover Handler를 설계할 때 가장 근본적인 문제는 모바일 연결 장애로 인한 사용자 측의 오류와 Enge 인프라 가용성 또는 도달 불가능으로 인한 사용자 측의 오류를 구분하는 것이었습니다. 이러한 문제는 특히 글로벌 규모로 Uber의 애플리케이션을 위한 휴대폰/LTE 네트워크의 높은 사용률로 인해 더욱 어려워졌습니다. 모바일 네트워크는 유선 네트워크에 비해 안정성과 신뢰성이 떨어지며 간헐적인 장애, 연결 문제 및 정체가 발생하기 쉽습니다.
기본 도메인(클라우드 영역 내에서 호스팅 되는 Edge 서버의 도메인 이름)에 대해 일시적인 DNS 오류 또는 QUIC/TCP 연결 시간 초과가 발생했다고 해서 반드시 사용할 수 없는 것은 아닙니다. 대부분의 경우 이러한 오류는 실제로 연결이 간헐적인 연결 끊김으로 발생합니다. 예를 들어 터널(운전 중 지하 터널 등)에 들어가 모바일 서비스가 손실되는 경우를 상상해 보십시오. 이러한 시나리오에서는 도메인을 기본 도메인에서 백업 도메인으로 전환하는 것이 도움이 되지 않으며 일단 연결이 복구되면 성능이 저하될 수 있습니다.
라운드 로빈 기반의 페일오버 핸들링 (Round robin-based failover handler)
우리가 테스트한 몇 가지 간단한 솔루션으로는 이 문제를 효과적으로 해결하지 못했습니다. 초기 버전의 Failover Handler는 도메인 목록으로 구성된 로빈 기반 시스템을 사용했습니다. 첫 번째 도메인은 최상의 성능을 제공하는 기본 도메인입니다. 기본 도메인 다음에는 백업 도메인 (일반적으로 Uber의 관리 데이터 센터 서버)이 뒤따르며 기본 도메인을 사용할 수 없을 때 대체하도록 했습니다. 특정 네트워크 오류 (DNS 오류, 시간 초과, TCP / TLS 오류 등)를 수신하면 시스템은 모든 후속 HTTPS 요청에 대해 도메인을 목록의 다음 항목으로 전환했습니다.
이 라운드 로빈 솔루션은 가용성 요구 사항은 충족했지만, 성능과 관련하여 몇 가지 단점이 있었습니다.
-
과도한 호스트 변경: 간헐적인 네트워크 오류로 인해 시스템이 도메인을 전환합니다. 도메인 간에 과도한 전환으로 인해 불필요한 DNS 조회 및 연결 설정이 발생하여 추가적인 지연이 발생할 수 있습니다.
-
성능이 나지 않는 도메인으로 라우팅 되는 빈번한 문제들 : 네트워크 오류가 발생하면 시스템은 네트워크가 복구된 후 동일한 확률로 목록의 도메인 중 하나를 사용하게 됩니다. 기본 도메인을 사용할 수 있음에도 불구하고 성능이 낮은 백업 도메인에서 상당량의 세션이 처리된 것을 확인했습니다. 시스템은 또 다른 네트워크 오류가 발생한 후에만 기본 도메인으로 다시 전환됩니다.
임계값 기반의 페일오버 핸들링 (Threshold-based failover handler)
과도한 도메인 전환을 방지하기 위해 임계값 기반 페일오버 핸들러도 실험했습니다. 임계값 기반 솔루션은 단일 네트워크 오류를 기준으로 페일오버를 트리거하는 대신 최소 수의 네트워크 오류가 발생한 후에만 도메인을 전환합니다.
하지만 다양한 애플리케이션, 지역 및 네트워크 유형(LTE, WiFi 등)에서 효율적으로 작동하는 임계값을 찾기는 어려웠습니다. 값을 너무 낮게 설정하면 불필요한 전환이 발생했지만 너무 높게 설정하면 기본 도메인을 실제로 사용할 수 없는 시나리오에서 복구가 지연됩니다 게다가, 시스템은 이전 접근 방식의 단점을 완전히 해결하지 못했습니다.
엣지 기반의 페일오버 핸들링 (Edge-driven failover handling)
Uber의 Edge 인프라는 DNS 재매핑과 같은 도메인 장애를 완화하는 자동화된 복구 메커니즘을 갖추고 있습니다. 이 경우 기본 도메인의 오류가 과도하면 영향을 받는 도메인의 도메인-이름과 IP 주소 매핑이 재구성됩니다. 하지만 수정된 매핑이 모든 DNS 네임서버에 전역적으로 전파되어야 하므로 DNS 전파는 즉각적으로 되는 것은 아닙니다.
종종 기본 도메인의 도달 불가능이 발생한 곳은, 소규모 지역, 도시 또는 특정 이동 통신사로 한정되었습니다. DNS 매핑 업데이트 하나만으로는 효과적으로 문제를 해결할 수 없었습니다. 모바일 앱은 연결 상태에 대한 더 나은 컨텍스트를 가지고 있으며 실시간으로 반응할 수 있습니다. 따라서 Enge 기반 failover handling 메커니즘 외에도 연결을 보장하기 위해 디바이스 기반의 로컬 failover handling가 필요하다고 결정했습니다.
장애 처리 핸들러 설계하기 (Failover Handler Design)
Uber의 장애 처리 핸들러를 설계할 때, 기존 솔루션에 없는 세 가지 주요 기준을 충족시키기를 원했습니다.
- 기본 도메인들의 사용 극대화: 일반적으로 최상의 성능을 제공하는 기본 도메인으로 트래픽을 우선 라우팅하는 방식으로 운영하기 위해서는 페일오버 처리 솔루션이 필요했습니다. 기본 도메인들을 통과하는 HTTPS 트래픽의 양을 최대화하면 지연 시간이 줄어들고 전반적으로 더 나은 사용자 경험이 보장됩니다.
- 네트워크 오류와 호스트 레벨 운영 중단을 효과적으로 구별: 시스템에는 실제 도메인 장애를 정확히 식별하고 간헐적인 모바일 네트워크 연결 문제로 인해 대체 호스트로 전환될 가능성을 낮출 수 있는 강력한 메커니즘이 필요했습니다.
- 기본 도메인 중단 시 성능 저하 감소 : 기본 호스트를 사용할 수 없거나 연결할 수 없을 때 백업 도메인의 사용을 극대화하기 위해 장애 조치 처리 시스템도 필요했습니다.
이러한 요구 사항을 충족하기 위해 아래 그림 2와 같이 FSM (Finite State Machine)으로 장애 조치 처리기를 설계했습니다.
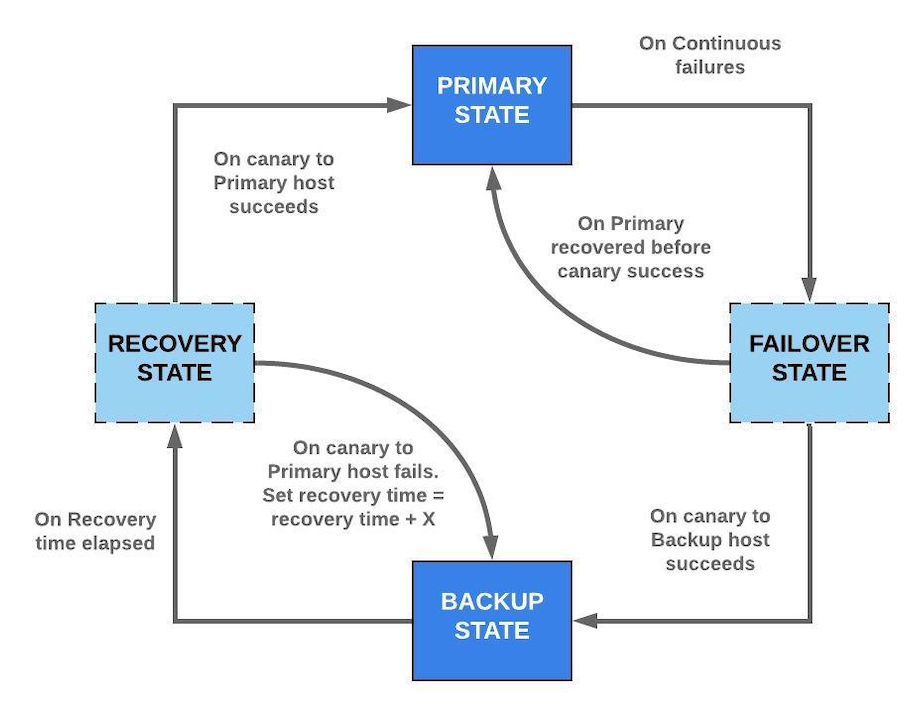 그림 3. 장애 조치 핸들러는 기본, 장애 조치, 백업 및 복구의 네 가지 상태로 작동하는 유한 상태 머신으로 설계되었습니다. 기본 및 백업 상태는 트래픽이 각각 기본 및 백업 도메인으로 라우팅 되는 안정적인 작동을 보장하고 장애 조치 및 복구 상태는 이 두 상태 간에 안정적인 전환을 보장합니다.
그림 3. 장애 조치 핸들러는 기본, 장애 조치, 백업 및 복구의 네 가지 상태로 작동하는 유한 상태 머신으로 설계되었습니다. 기본 및 백업 상태는 트래픽이 각각 기본 및 백업 도메인으로 라우팅 되는 안정적인 작동을 보장하고 장애 조치 및 복구 상태는 이 두 상태 간에 안정적인 전환을 보장합니다.
시스템은 HTTPS 트래픽을 라우팅하는 데 기본 도메인이 사용되는 PRIMARY_STATE와 백업 도메인 중 하나가 대신 사용되는 BACKUP_STATE의 두 가지 안정적인 상태에서 작동하기 위해 노력하고 있습니다. 기본 도메인 다운타임이 발생하지 않는 한, 시스템은 항상 PRIMARY_STATE에서 작동하기 위해 노력하고 있습니다. 두 가지 중간 상태, FAILVER_STATE 및 RECOVER_STATE는 PRIMARY_STATE에서 BACKUP_STATE로(그리고 그 반대도) 확실하게 전환되도록 보장합니다.
PRIMARY_STATE
PRIMARY_STATE는 기본 및 원하는 상태입니다. 이 상태에서 기본 도메인은 모든 HTTPS 요청에 사용됩니다. 실패가 없거나 간헐적인 실패가 적은 경우 상태 변경이 발생하지 않습니다. 이 상태에서는 FAILOVER_STATE로의 전환을 지원하기 위해 연속 실패 횟수가 추적됩니다. 여기서 실패는 DNS 오류, TCP / QUIC 연결 오류 또는 시간 초과와 같은 HTTPS 응답에 대해 수신된 오류를 나타냅니다.
장애 처리 조건을 충족하면 FAILOVER_STATE에 도달합니다 (예 : "Y"간격 동안 "X"회 연속 실패). 이 상태에서 모든 HTTPS 요청은 여전히 기본 도메인을 통해 전송됩니다. 시스템이 임계 값 ( "X"및 "Y")의 값에 민감하지 않도록 하고 장치 연결 오류에 대한 도메인 오류 식별의 신뢰도를 높이기 위해 카나리아 요청을 활용합니다. 카나리아 요청은 에지 서버의 상태 엔드 포인트 (REST API)에 대한 전용 HTTPS 요청입니다. 카나리아 요청은 첫 번째가 성공할 때까지 백업 도메인 목록을 통해 전송되며, 이 시점에서 시스템은 BACKUP_STATE로 전환됩니다.
FAILOVER_STATE에 있는 동안 기본 도메인(primary domain)을 사용하는 일반 요청에서 응답이 성공적으로 수신되면 상태가 PRIMARY_STATE로 다시 변경됩니다. 이 문제는 모바일 네트워크에서 연결 문제 때문에, 기본 도메인(primary domain)에 에러가 발생할 수 있습니다.
카나리아 요청(Canary request) 이 도입되면 네트워크 연결 상태가 좋지 않은 기간 동안 백업 도메인으로 장애 조치할 가능성이 줄어듭니다.
BACKUP_STATE
대신 시스템이 FAILVER_STATE에서 카나리아 응답을 성공적으로 수신하면 BACKUP_STATE로 전환되고 모든 HTTPS 요청에 대해 백업 도메인을 사용하기 시작합니다. 시스템은 일반적으로 기본 도메인을 사용할 수 없거나 해당 사용자 세션에 연결할 수 없는 경우 이 상태에 도달합니다.
시스템이 BACKUP_STATE에서 작동하는 동안 기본 도메인이 복구되었을 수 있는 경우 계속해서 상태를 확인하는 것이 중요합니다. 따라서 BACKUP_STATE에서 시스템은 복구 타이머를 유지하고 타이머가 만료되면 RECOVERY_STATE로 전환됩니다. RECOVERY_STATE에서 카나리아 요청은 기본 도메인으로 트리거되는 반면 일반 HTTPS 트래픽은 여전히 백업 도메인을 통해 전송됩니다. 기본 도메인이 복구되었음을 나타내는 카나리아 요청이 성공하면 시스템이 PRIMARY_STATE로 다시 전환되어 모든 트래픽을 다시 기본 도메인으로 라우팅합니다.
BACKUP_STATE에 있을 때 시스템은 (PRIMARY_STATE로 다시 전환되면 지워지는) 영구적인 캐시(persistent cache)에 마지막으로 사용된 백업 도메인을 저장합니다. 앱 시작 시, 시스템이 (영구적인 캐시로부터) 도메인을 읽을 수 있다면, BACKUP_STATE에서 시작합니다. 이렇게 하면 이전 세션에서 기본 도메인에 문제가 있는 사용자를 위해 항상 백업 도메인에서 시작할 수 있습니다. 앱을 새로 시작할 때마다 시스템이 문제를 발견해야 하는 것을 피하면 연속 세션에서 지연 시간을 줄이고 더 나은 경험을 할 수 있습니다.
카나리아 요청(Canary requests)
주요 선택(전략) 중 하나는 카나리아 요청을 사용하는 것이었습니다. 카나리아 요청 사용은 백엔드 인스턴스의 상태를 결정하는 상태 확인에서 영감을 받았습니다. 일반 트래픽을 백업 도메인으로 전환하기 전에 백업 도메인에 대한 카나리아 요청을 트리거함으로써 트래픽이 기본 도메인과의 연결 문제가 발생했을 때, 백업 도메인의 활성화할 가능성([1]confidence) 을 높입니다. 모바일 네트워크로 인해, 기본 도메인과의 연결 문제가 발생한 경우 백업 도메인에 대한 카나리아도 실패해야 합니다.
카나리아 요청을 실행하기 위해 두 가지 옵션 중 하나를 선택해야 했습니다. 전용 상태 엔드 포인트에 요청을 보내거나 또는, 기존 애플리케이션 요청을 카나리아 요청으로 피기 백(piggyback) 하는 것입니다.
비교적 단순하기 때문에 첫 번째 옵션을 선택했습니다. 전용 카나리아 요청을 사용하면 시스템이 애플리케이션 요청에 의존하지 않고 온디맨드 방식으로 카나리아 요청을 트리거할 수 있으므로 카나리아 요청을 트리거할 때 불필요한 지연을 방지할 수 있습니다. 또한 엄격한 SLA로 인해 일부 중요한 HTTPS 요청을 카나리아로 사용하면 안 되는 경우, 각 애플리케이션에 대한 요청 허용 목록(whitelist)을 유지하지 않습니다. 또한 백엔드 처리 지연을 완화하고 시스템을 쉽게 디버깅할 수 있으며, 여러 카나리아를 트리거하여 도메인에서 요청을 처리할 가능성을 높이거나 여러 옵션 중에서 특정 도메인을 선택할 수 있는 등 향후 최적화를 보다 쉽게 수행할 수 있습니다.
2부 (II)에서는
다음 글에서는 실제 상황에서의 장애 처리 핸들링 노하우와 이로 인해 어떻게 성능 향상이 이루어졌는지를 다루도록 하겠습니다.
우버의 아키텍처 및 시스템 설계에 대해 궁금하시다면, 아래 콘텐츠를 추천해드립니다.
Uber 아키텍처와 시스템 디자인
입력이 어떤 부류(class)에 속하는 신뢰도(confidence)에 매핑하는 함수. ↩︎

