


지난 '직관적인 대시보드 설계하기 #1 - 지표와 레이아웃'에서 대시보드 개선에 대한 목표와, 좋은 대시보드를 만들기 위해 알아두면 좋을 지표와 레이아웃에 대해 알아보았습니다. 특히 대시보드를 실제로 다루는 개발자, 기획자에게 정말 많은 관심을 받았는데요.
*아직 못 보셨다면, 아래 게시물에서 먼저 확인해 보세요. 😊
- 직관적인 대시보드 설계하기 #1 - 지표와 레이아웃
이어지는 이번 글에서는 더 나은 대시보드를 만들기 위한 여러 가지 시각화 방법에 관해 이야기합니다.
*이 글은 Cory Watson – Dashboard Renaissance의 강연 내용을 번역한 글로, presentation 화면에 띄워진 이미지와 함께 내용을 정리하였습니다. 번역하는 과정에서 매끄럽지 않을 수 있으니 이해를 부탁드리며, support@imqa.io로 연락해 주시면 수정하도록 하겠습니다. (글의 모든 저작권은 Cory Watson에게 있습니다. 원본 강연은 이 링크를 참고하세요!)
목차
목표: 대시보드의 개선
1. 지표와 레이아웃
• 사용자로부터 요건 가져오기 (Get a spec from users)
• 개념 잡기 (Starting Concepts)
• 포함할 항목 (What to include)
• 하나의 화면, 다음 단계 (One Screen, More Next Steps)
• 점진적인 깊이 (Progressive Depth)
2. 시각화
• 인간을 해킹한다 (Hacking Humans)
• 전주의적 처리 (Pre-attentive Processing)
• 인식의 정확성 (Accuracy of Perception)
• 인간은 가로를 좋아해 (Humans Like Horizons)
• 선, 막대, 그리고 기타 (Before Lines, Bars, & etc)
• 테이블을 잊지 마세요 (Don't Forget Tables)
• 선 vs 열 (Line Versus Heat))
• 영역 (Area)
• 막대 (Bars)
3. 맥락
• 실무자는 맥락이 필요해 (Practitioners Need Context)
• 규모, 단위, 규범, 레이블 (Scale, Units, Norms, Labels)
• 텍스트 (Text)
• 목표 표시 (Mark Targets)
요약: 대시보드를 되살리는 방법
더 알고 싶다면?
2. 시각화

💡인간을 해킹한다 (Hacking Humans)
- 어떤 정보를 빠르게 얻을 수 있는가? (What can we quickly get information from?)
- 무엇이 눈을 즐겁게 하는가? (What is pleasing to the eye?)
- 어떻게 하면 정확성을 높일 수 있을까? (How can we increase accuracy?)
- 어디에 주목해야 하는가? (Where do we draw attention?)
우리가 말하고자 하는 것을 어떻게 쉽고 빠르게, 그리고 왜곡 없이 전달할 수 있을까?
시각화의 요점은 사용자에게 정보를 제공하는 것인데요. 데이터를 더 이해하기 쉽도록 시각화 도구를 통해 전달하는 것을 시각화라고 합니다. 책을 읽거나 신문을 볼 때 글로만 적혀있는 것보다 그것을 이해할 수 있는 도표나 그림과 함께 있으면 훨씬 이해하기 쉽죠.
우리는 시각화를 통해 정확하고, 빠르게 정보를 제공해야 합니다. 사람들은 자신이 좋아하는 것을 더 많이 사용하고, 관심을 쏟을 가능성이 높기 때문에 이것이 미적으로도 적합한지에 대해서도 확인해야 합니다.
이렇듯 잘 만들어진 시각화는 한눈에 보기 좋을 뿐만 아니라 효과적으로 정보를 전달할 수 있고, 사용자들은 흥미를 갖고 정보의 의미를 쉽게 파악할 수 있습니다.
이 글에서도 각 항목마다 이해를 돕기 위해 그림을 제공하고 있답니다. 이것도 시각화 방법이라 할 수 있죠. 👀
💡전주의적 처리 (Pre-attentive Processing)
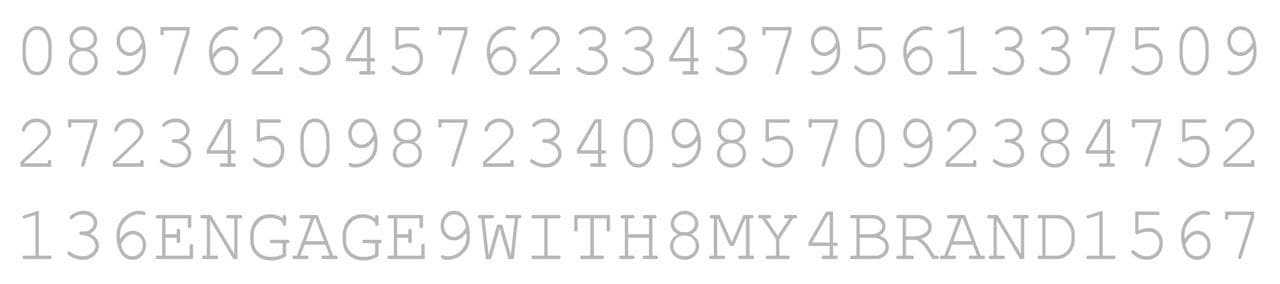
위 이미지에서 숫자 '8'이 몇 개 있는 것 같으신가요? 한눈에 보이시나요?
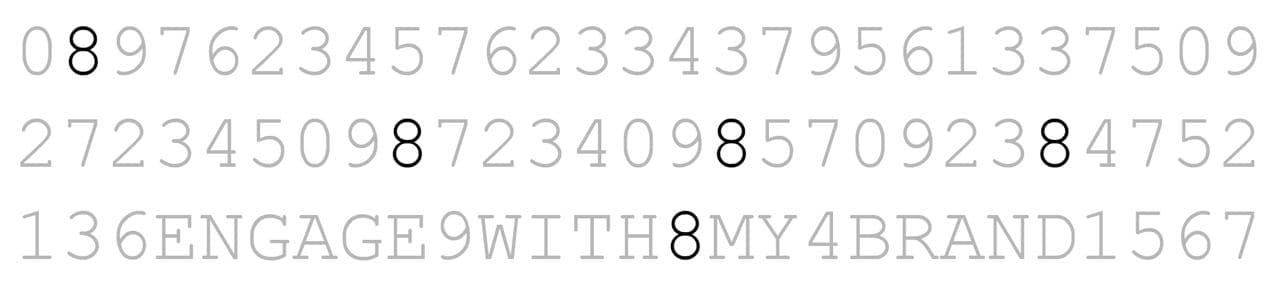
위의 이미지와 달리 두 번째 이미지에서는 숫자 '8'이 몇 개 있는지, 한눈에 정확히 알 수 있습니다.
전주의적 처리를 쉽게 설명하기 위해 예시를 하나 들어보았습니다.
우리는 숫자와 알파벳이 뒤섞인 위의 첫 번째 이미지를 보고 한 번에 '8'이라는 숫자의 개수를 알기는 어렵습니다. 하지만 두 번째 이미지에서 우리는 '8'의 개수를 정확히 인지할 수 있는데요.
이처럼 전주의적 처리는 주의를 집중하기 전에 이루어지는 것으로 인지 자원을 전혀 사용하지 않고 사용자에게 직접 정보를 전달합니다. 아무리 많은 정보가 있어도 시각화에서 강조되는 것은 우리의 시선을 끌기 마련이죠.
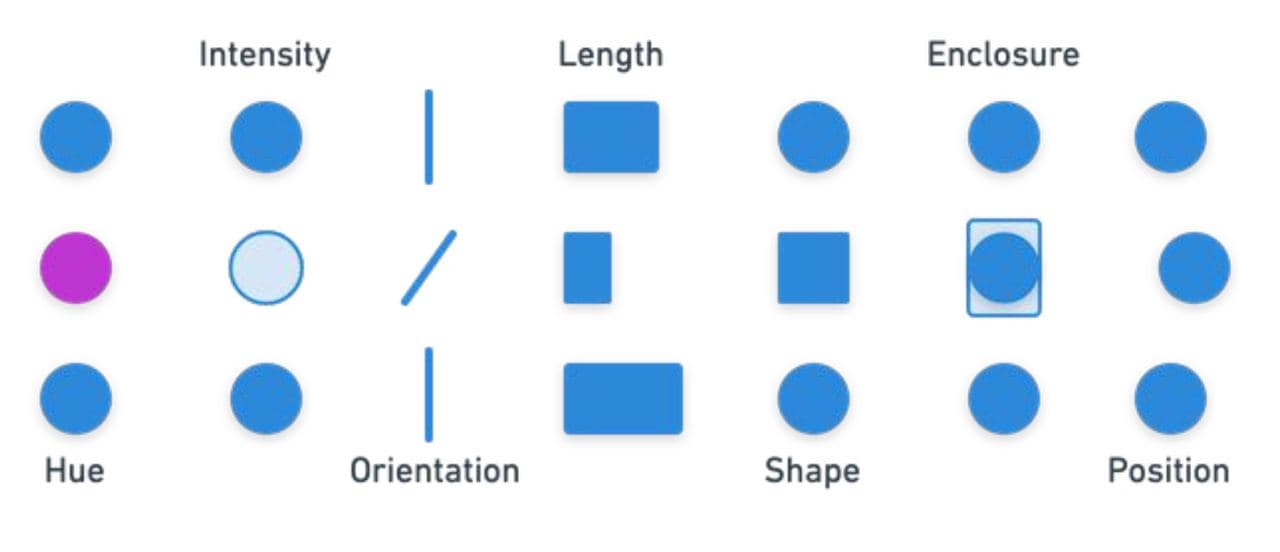
그림에서 우리는 색조(hue), 강조(intensity), 방향(orientation), length(길이), 모양(shape), 둘러싼 것(enclosure), 위치(position)로 시각화한 것 중 다른 하나를 즉시 알아차릴 수 있습니다.
하지만 이것들은 정확도의 차이가 있는데요. 우리가 시각화를 상황에 맞게 사용해야 하는 것이 그 이유입니다. 상황에 맞지 않는 시각화는 오히려 보는 사람들에게 혼란을 줄 수 있고 정보가 전달되지 않을 수 있죠.
💡인식의 정확성 (Accuracy of Perception)
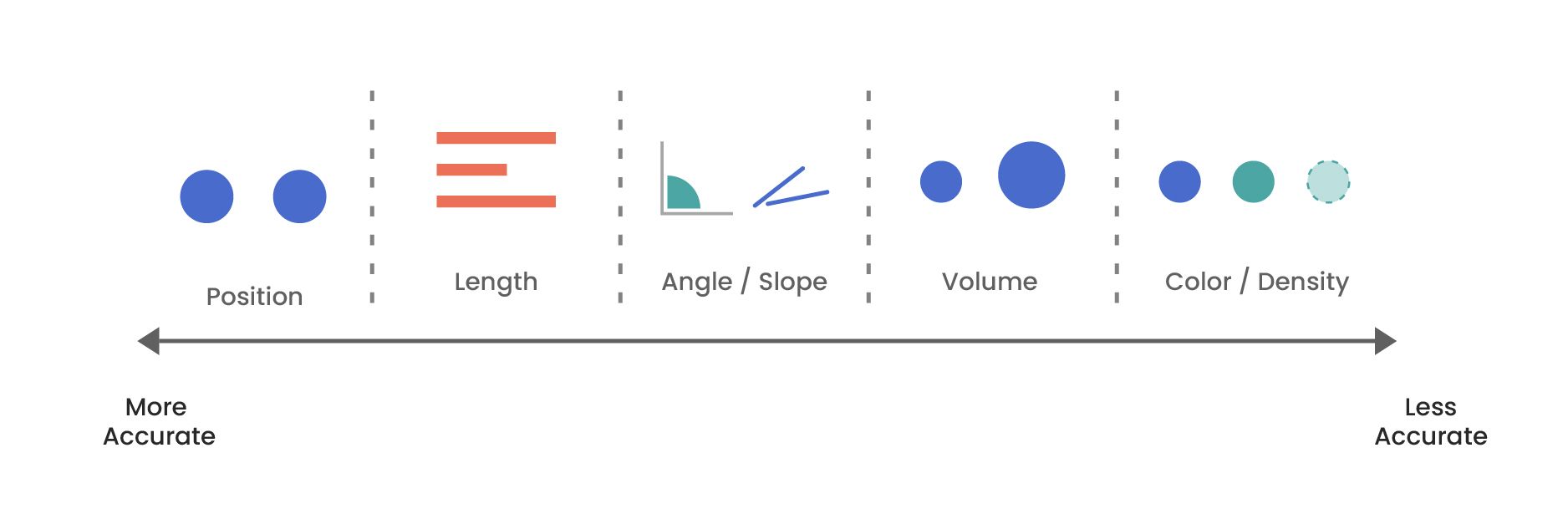
시각화 표현을 할 때, 우리가 가장 정확하게 인식하는 것은 '위치'입니다. Cory Watson은 위 이미지와 같이 "위치, 길이, 각도/경사, 양감, 색상/밀도 순으로, 높은 정확도를 가지고 있다."라고 말합니다.
💡인간은 가로를 좋아해 (Humans Like Horizons)
- 높은 것보다 넓은 것 (Wider than taller)
- 시간은 X축이 직관적 (Time as X axis is intuitive)
- 데이터의 각도 개선 (높은 꼭지점) (Angles of data are better (fewer tall spikes))
우리의 눈은 가로(horizons)를 좋아하고 적응이 되어 있는데요. 많은 대시보드가 그러하듯, 높은 것보다 넓은 것을 선호합니다. 좀 더 자세한 설명을 돕기 위해 IMQA의 대시보드를 예시로 함께 볼까요?
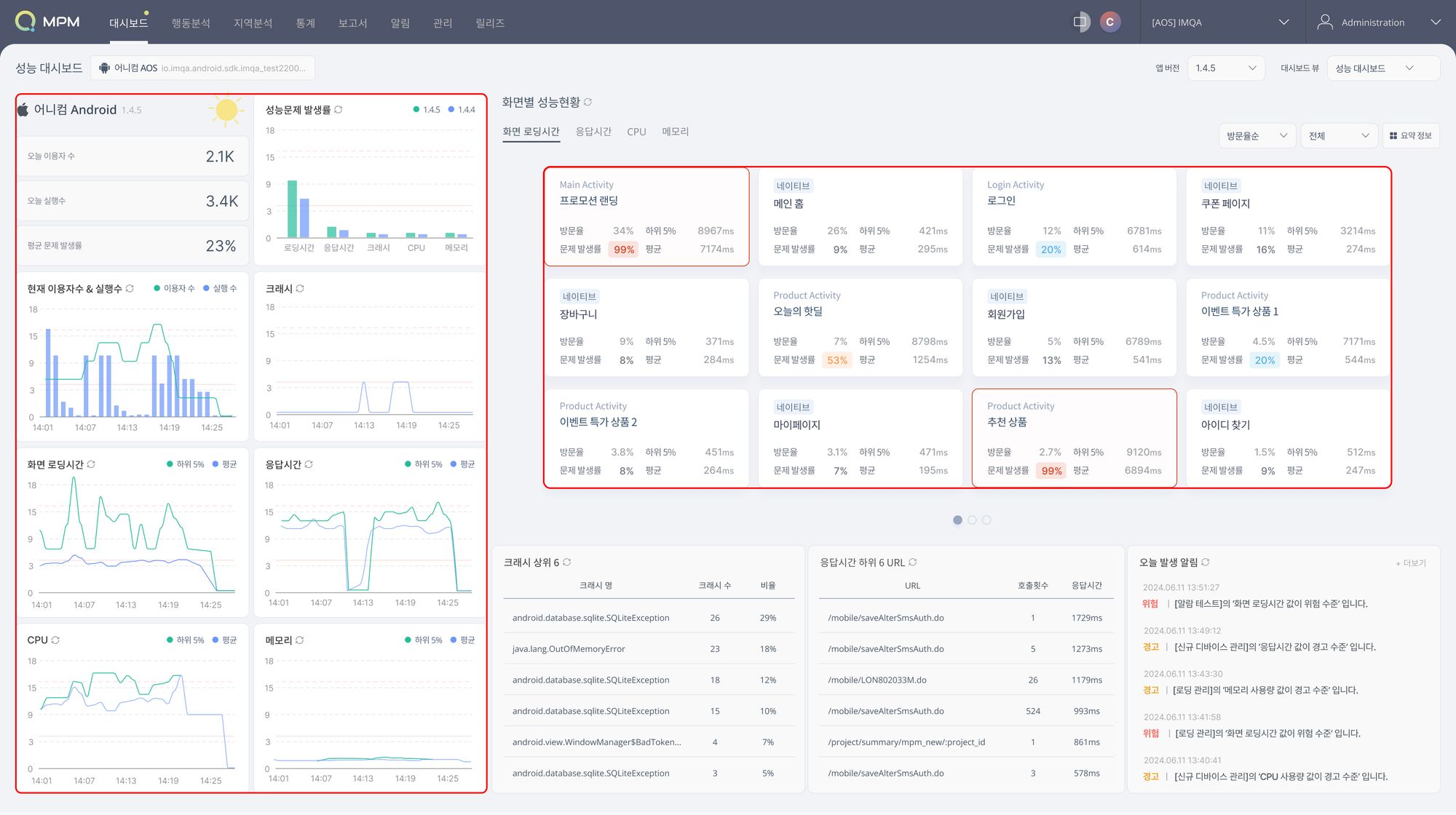
1편에서 간략히 설명드렸듯이 IMQA MPM은 모바일 성능 모니터링 솔루션으로 대시보드에서는 최근 30분간의 모바일 앱 성능을 실시간으로 모니터링할 수 있으며, 주요 지표는 화면 로딩 시간, 응답시간, CPU, 메모리 등 자원 사용량이 있습니다.
MPM 대시보드는 주요 성능을 같은 크기의 시계열 그래프로 나타내고 X축을 시간으로 표현하였는데요. 우리는 시간의 흐름에 따라 왼쪽에서 오른쪽으로 보는 것이 익숙하고, 같은 넓이(가로축)의 그래프를 사용해야 정확한 해석을 할 수 있기 때문입니다.
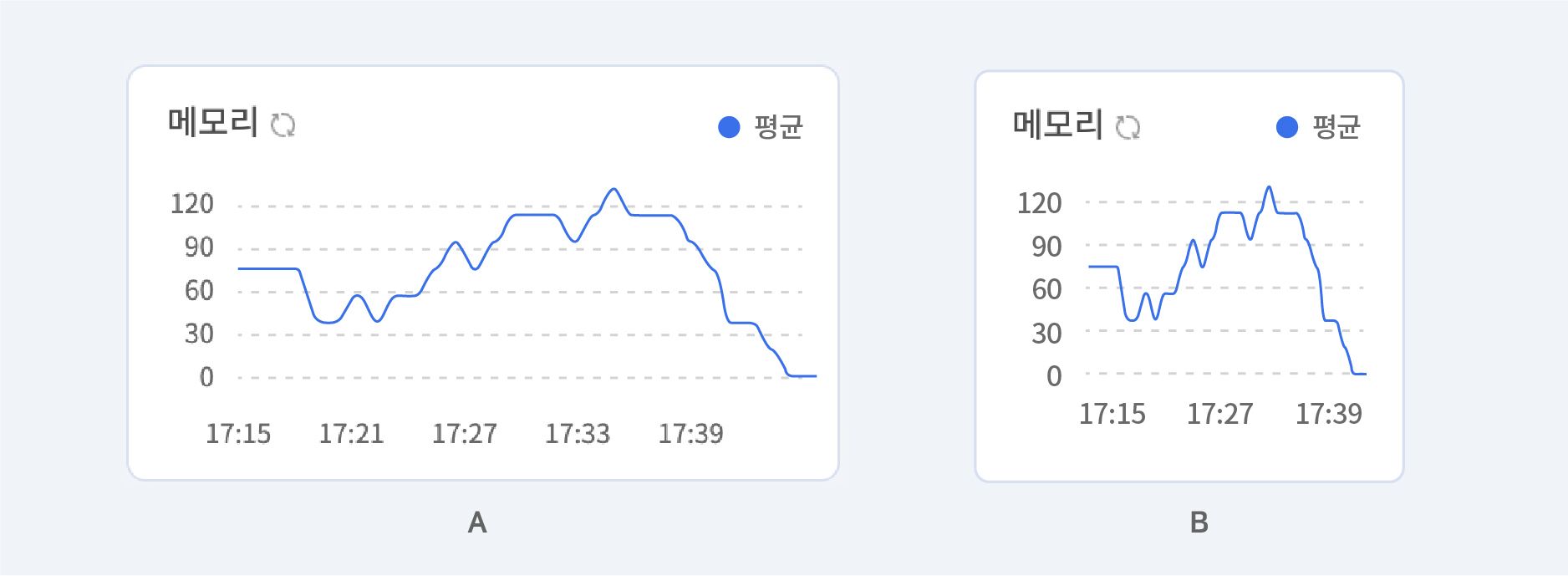
예를 들어, 시계열 그래프 2개가 있는데 A는 가로로 길고 넓게 배치되어 있고 B는 가로가 좁게 배치되어 있다고 가정해보죠. 실제로 큰 차이가 없더라도 B의 꼭지점이(Peak point)이 A의 꼭지점보다 각도가 가파르기 때문에 더 드라마틱 하게 느껴질 텐데요. 이 경우 각도가 주는 정보는, 식별이 가능하고 정확한 범위에서 멀어진다는 것을 의미합니다. 가로로 길게 배치된 차트를 사용할 경우, 각도를 식별하기 좀 더 쉬워지는데요. 이것은 데이터의 각도 또한 사용자에게 중요한 정보가 된다는 것을 의미합니다.
다시 IMQA 대시보드를 살펴보면, 화면별 성능 현황이 가장 눈에 띄는데요. 위치가 위쪽에 배치되어 있고 크기가 다른 차트보다 크기 때문입니다. 우리는 화면별 성능 현황이 중요하다 생각했기 때문에 많은 비중을 차지하게 그렸고, 클릭 시 자세한 성능 현황을 동일한 화면에서 보여주는 것이 아닌 다른 화면으로의 이동을 선택했죠.
이렇듯 중요도에 따라 위치와 크기를 조절할 수 있고, 한 화면에 너무 많은 정보를 담지 않기 위해 다른 화면으로 이동을 할 수 있습니다.
💡선, 막대, 그리고 기타 (Before Lines, Bars, & etc)
- 경고는 주의를 끌기 위한 것 (Alerts are just charts you care about)
- 위치와 의미 (position and meaning)
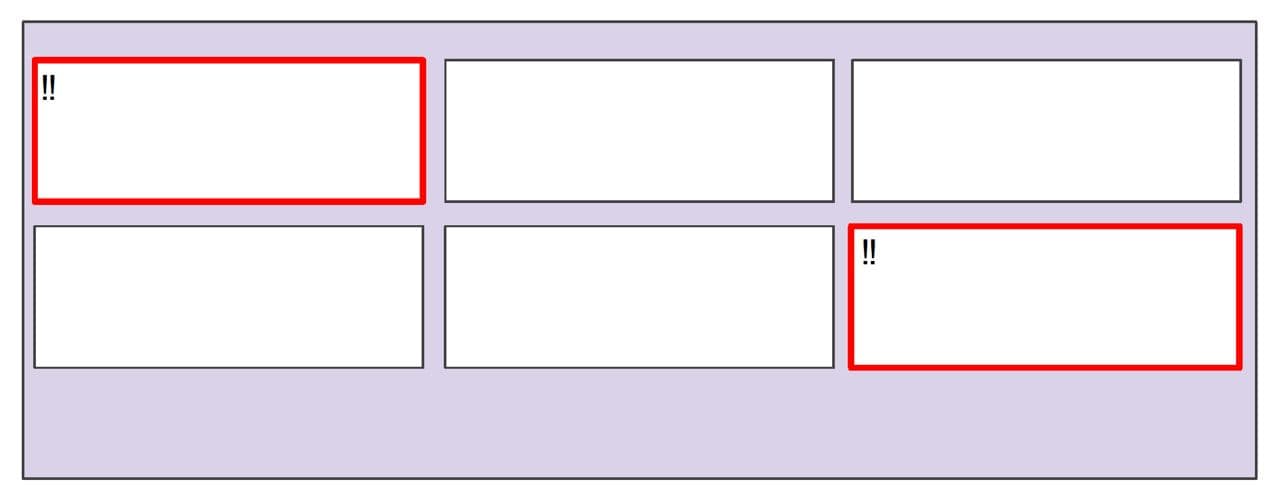
경고는 주의를 끌기 위한 것. 그리드에서의 차트의 위치는 고정되어야 합니다.
여러분들은 그림을 봤을 때, 첫 번째 칸과 여섯 번째 칸이 가장 먼저 눈에 들어올 것입니다. 이렇듯 경고 표시는 보는 사람의 주의를 끕니다. Cory Watson은 이경우 차트의 위치는 고정이 되어 있어야 한다고 말합니다. 창의 크기를 조정하거나, 디스플레이 크기를 변경할 때, 차트가 이동이 될 경우 매우 유용한 전주의적 처리 기능인 '위치'가 누락이 되니 말이죠.
IMQA MPM 대시보드로 예를 들어보죠.
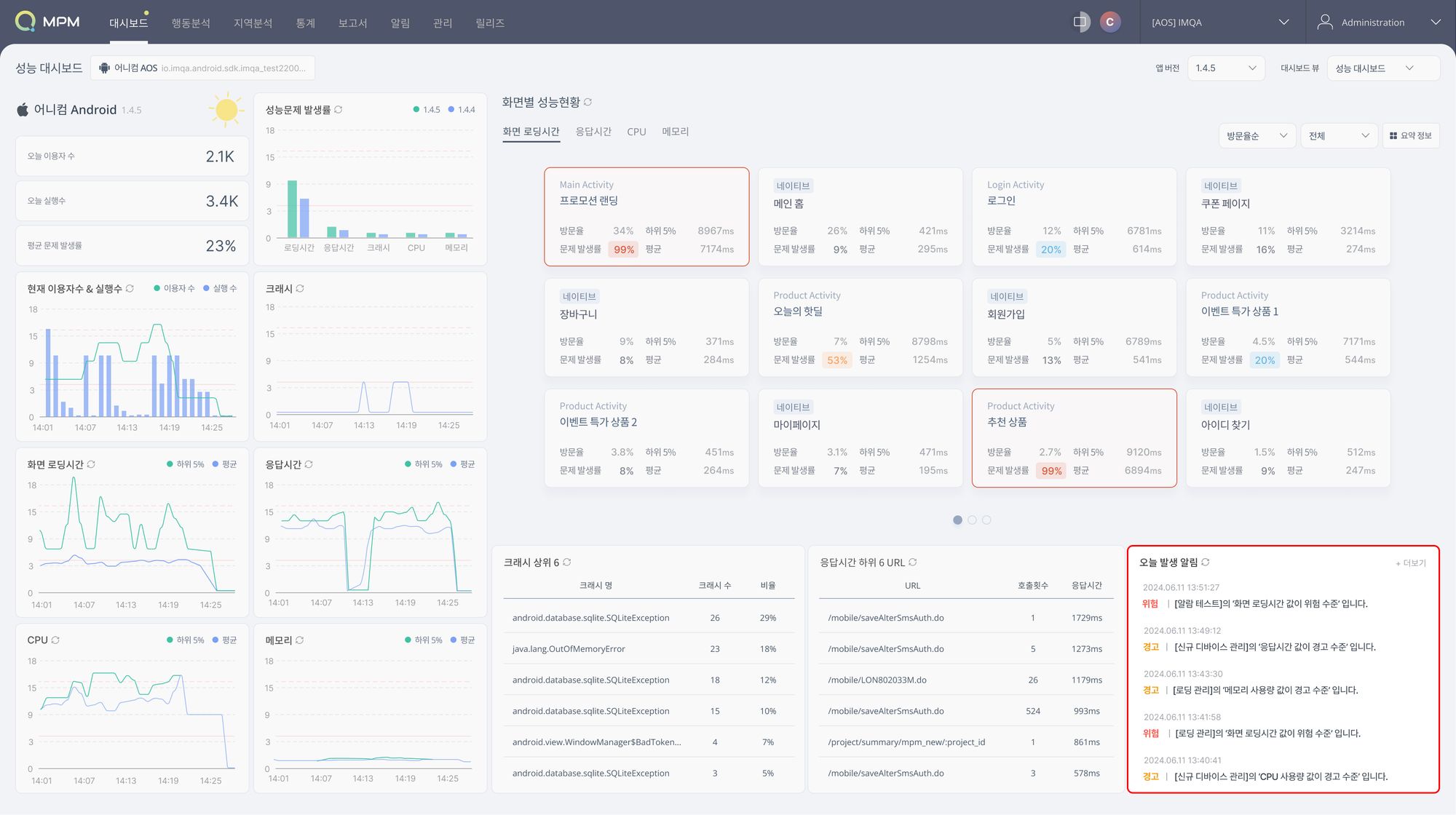
이 대시보드를 보는 사람이 맨 마지막 행의 마지막 차트가 '최근 발생 알림'임을 알고 있다면, 우리는 색상과 시간 순으로 알림을 표시하여 문제가 발생하고 있다는 메시지를 빠르게 사용자에게 전달할 수 있습니다.
'최근 발생 알림'은 최근 발생한 알림 순으로 정렬이 되며, 성능지표 값을 위험도 색상으로 표시하는데요. 성능 지표별 알림 기준치를 설정하여, 기준치 이상이 되었을 때 정상 범위, 경고 범위, 위험 범위의 비율을 기준으로 3가지 색상으로 나타냅니다.
만약 사용자가 이 특별한 차트가 항상 대시보드의 하단 오른쪽에 위치해 있다는 것을 안다면 우리는 즉시 특정 성능이 문제가 발생할 수 있다는 경고 알림을 효과적으로 전달할 수 있죠.
마지막으로 Cory Watson은 '창의 크기가 변경되면서 일어나는 차트의 위치 이동은 사람에게 전주의적 처리 기능이 작동되는 순간을 빼앗는다.'라며 그리드에서 차트의 위치는 고정되어야 한다고 다시 한번 강조하는데요. 흔히 반응형으로 대시보드를 구현할 경우, 창의 크기에 따라 요소의 위치가 재배열되기 때문에, 인간의 전주의적 처리 기능으로 매우 유용한 '고정된 위치'가 누락된다는 것입니다. 대시보드를 기획하는 사람은 이와 같은 케이스를 함께 고려해야 합니다.
💡테이블을 잊지 마세요 (Don't Forget Tables)
- 단일 값에 적합 (Good for single values)
- 잘 이해할 수 있는, 밀도 (Well understand, dense)
테이블은 단일 값에 적합한 방법입니다. 그만큼 체계적이고 이해하기도 쉽고 눈에 잘 들어옵니다. 또한 많은 정보 제공이 가능하다는 장점이 있죠.
저희 IMQA에서도 각 화면마다 디바이스 정보를 제공하기 위해 테이블을 사용하였는데요. 잠시 보실까요?
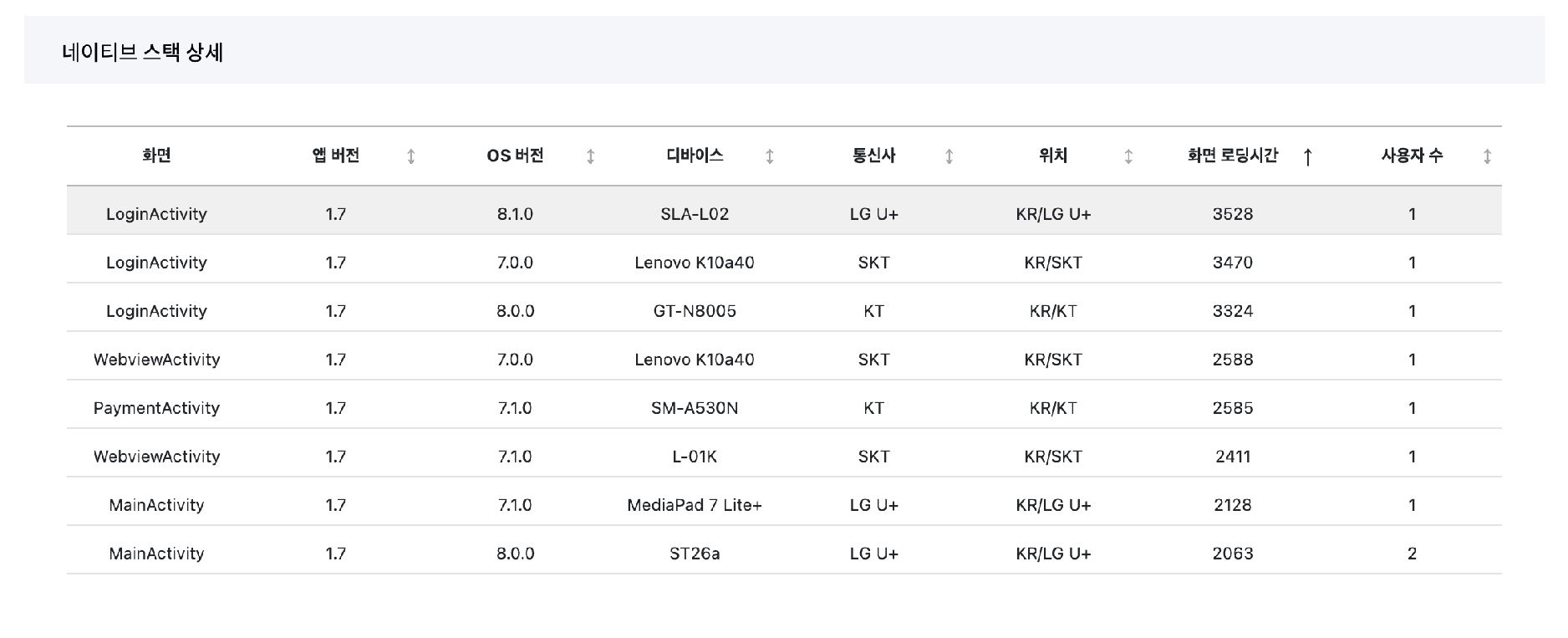
IMQA 스택 상세에서는 해당 스택에 대한 디바이스 정보를 보여주기 위해 테이블을 사용하였습니다. 해당 화면을 기준으로 왼쪽에 쌓아 많은 정보들을 나열하는 형태로 단일 가치 정보를 사용자에게 전달하고 있죠.
📍화려한 테이블 (Tables Can Be Fancy)
- 원하는 필드만 제공 (Just the fileds you want)
- 스파크라인, 기타 (Sparklines, etc.)

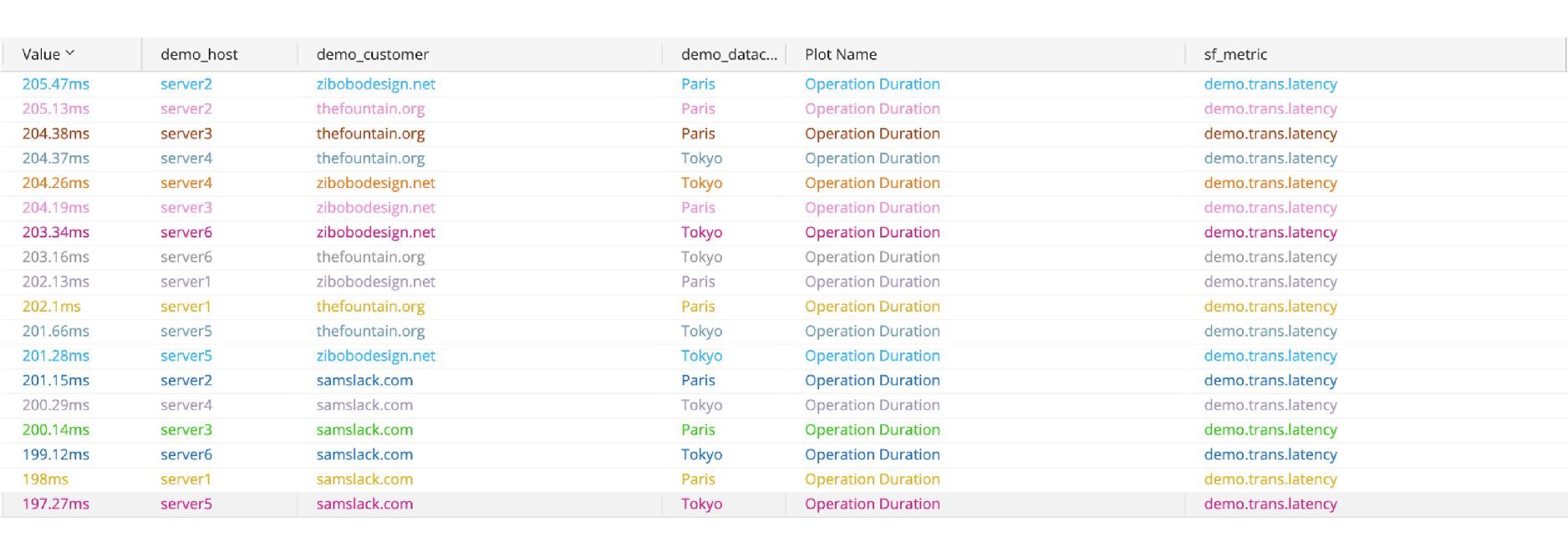
테이블은 스파크라인 등 시각적 요소를 포함하여 말하고자 하는 것을 더욱 명확하고 효과적으로 전달할 수 있는데요. 그림에서 스파크라인은 각 지역의 모든 고객들이 동시에 대기 시간이 증가했다는 것을 한눈에 알아볼 수 있도록 도와주죠. 이것은 테이블이 사용자에게 전달하고자 하는 핵심이고, 실제로 사용자가 알고 싶어 하는 것일 수도 있습니다. 오른쪽 *불릿 그래프같이 보이는 차트는 서비스 수준 목표(SLO)가 넘어가는 데이터를 한눈에 볼 수 있도록 도와줍니다. 사용자는 하나하나 숫자를 확인하지 않아도 전체 상황을 한눈에 확인할 수 있죠.
*불릿 그래프(Bullet Chart): 불릿 그래프는 실적 데이터를 표현하기 위한 그래프로, 주로 목표 달성 대비 실적 결과를 보여주기 위한 목적으로 사용합니다.
이렇듯 테이블은 시각적인 요소를 포함하여 정보를 직관적으로 전달할 수 있습니다.
💡선 vs 열 (Line Versus Heat)
- 너무 많은 선은 신호를 숨긴다 (Too many lines actually hide signal)
- 히트맵은 이상치를 보여준다 (Heatmaps show outliers)
- 채도는 정확도가 낮다 (Saturation is low accuracy tho)
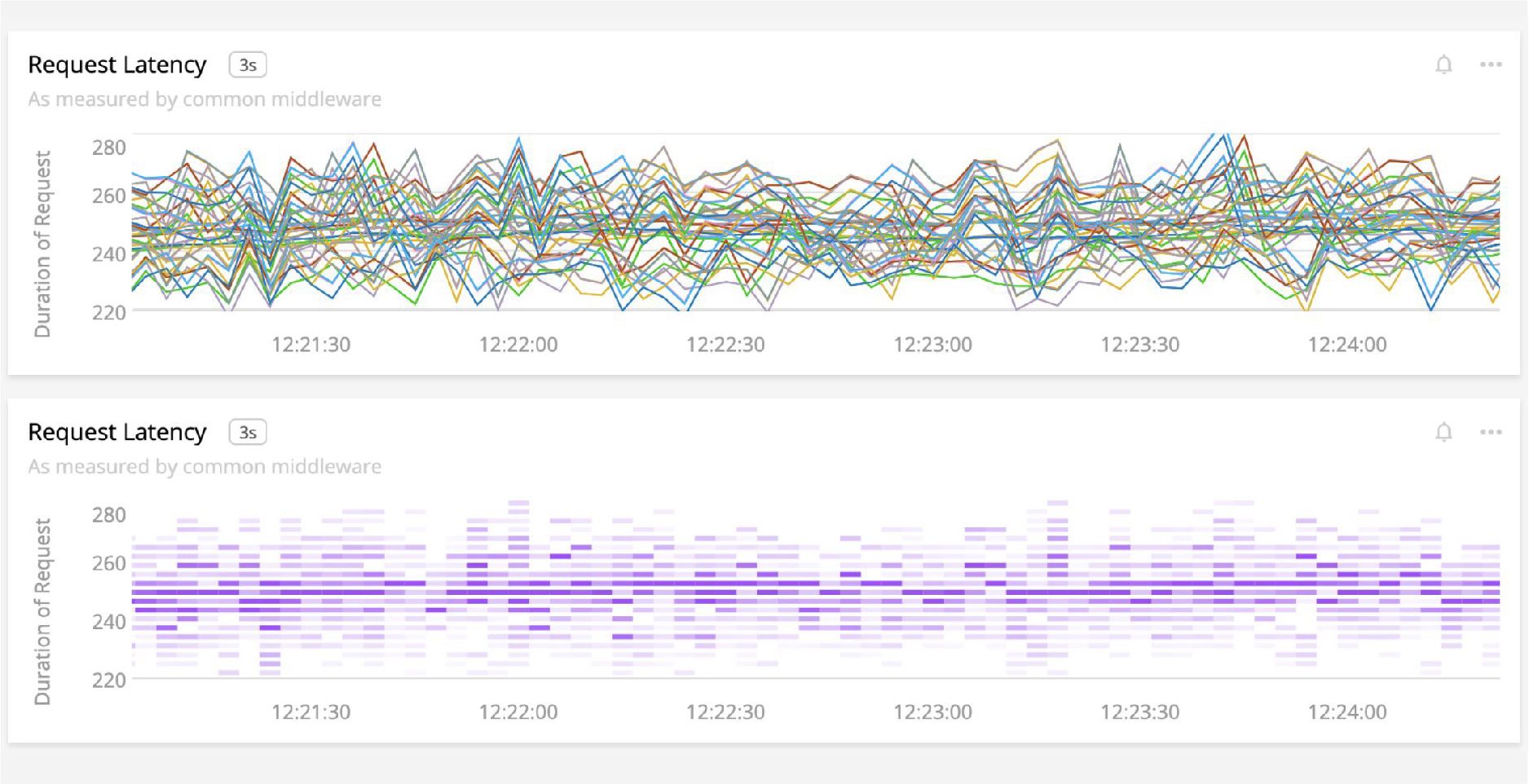
당신은 첫 번째 그래프에서 어떤 일이 벌어지는지, 무엇을 주목해야 하는지 알 수 있나요?
너무 많은 선은 말하고자 하는 것을 숨깁니다. 위와 같이 시각화에서 너무 많은 선을 넣는다면 실제로 어떤 일이 벌어지고 있는지 알 수 없는 거죠.
이것을 보완으로 히트맵을 사용한다고 해보죠. 두 번째 그래프는 눈에 들어오시나요? 히트맵은 때때로 이 문제에 도움이 되지만, 히트맵을 사용할 때는 매우 주의해야 합니다. 앞서 배웠듯이 채도(opacity)는 정확도가 낮기 때문이죠. 우리는 두 단계의 채도 차이를 쉽게 구별할 만큼 정확한 눈을 가지고 있지 않습니다.
요청 지연 시간에 대한 데이터를 두 가지 다른 형태로 표현한 이 시각화는 목적에 따라 구분하여 사용해야 합니다. 히트맵에서 차트의 가운데 높은 채도는 선들이 많이 교차하기 때문인데요. 우리는 이 선들로부터 어떤 정보를 얻을 수 있을까요? 그것은 사용자가 무엇을 알고 싶어 하는지에 따라 다릅니다. 만약 사용자가 집단 분포를 알고 싶다면, 우리는 여기 표시된 것처럼 두껍고 진한 띠를 보고 의미를 찾을 수 있겠죠. 히트맵으로 이상치(outliers)를 찾는다면, 채도 구분보다는 구분이 확실한 다른 색상을 사용해야 특이치와 나머지를 구분할 수 있습니다.
이해를 돕기 위해 IMQA 대시보드를 살펴보죠.
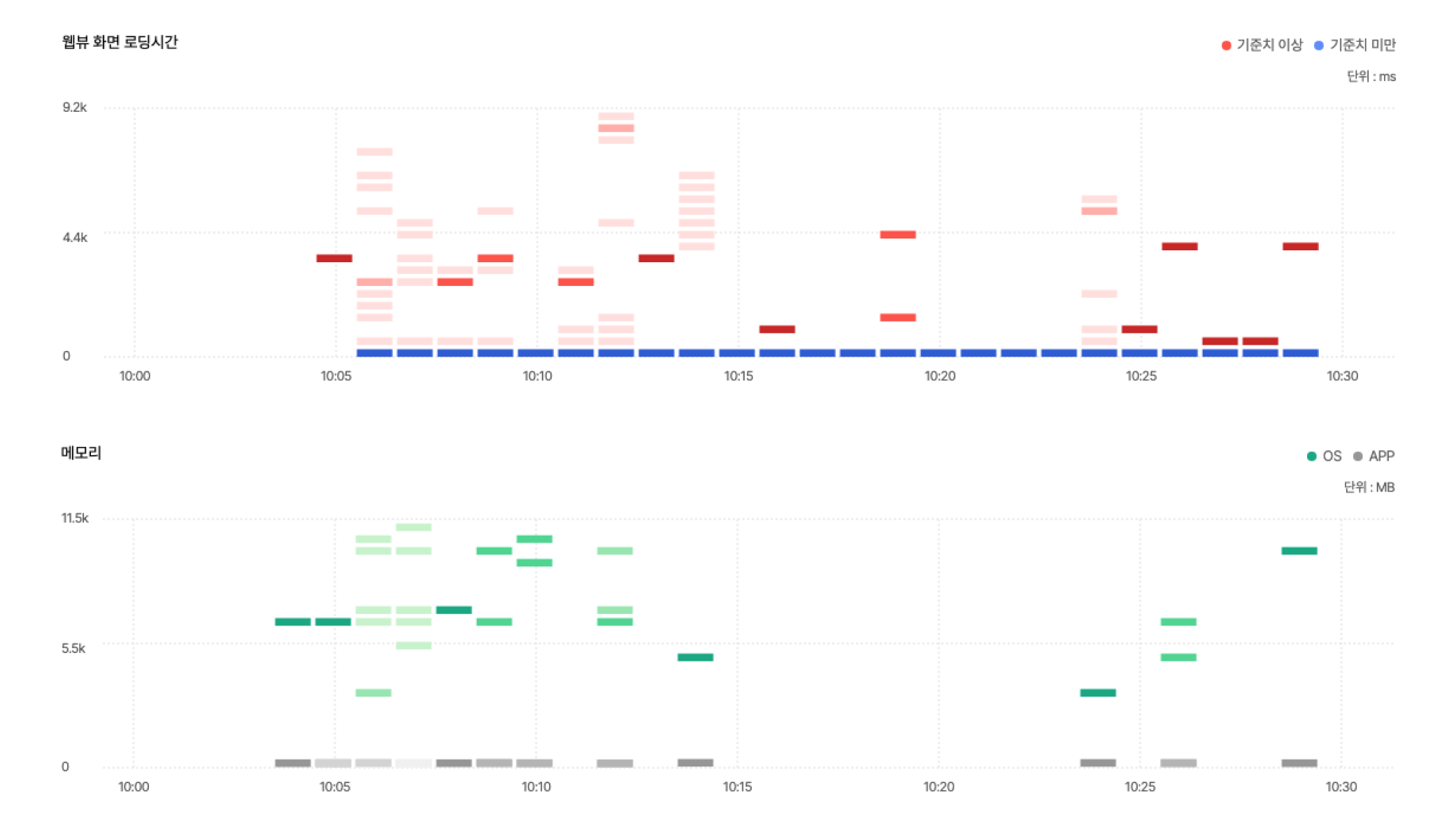
IMQA 화면 성능 분석에서는 각 성능 지표별 데이터를 히트맵으로 구성하였는데요. 이를 통해 성능 분포와 저하 상황을 상세하게 분석할 수 있습니다.
히트맵에서 기준치 이상 구간일 경우 빨강, 미만일 경우 파랑으로 표시하고 같은 시간축에 집계된 데이터 비율에 따라 색상 농도를 3단계로 표시합니다. 또 자원 사용량(CPU, 메모리)에서는 OS 사용량과 APP 사용량을 '색상'(초록, 검은색)으로 구분하여 정확하게 식별할 수 있습니다.
채도(opacity)는 정확성이 낮습니다.
💡영역 (Area)
- "합산의 일부"에 적합 (Good for "parts of a sum")
- "누적"에만 사용 (Only use stacked)
- 어떤 것들이 기여하는가? (But which things are contributing?)
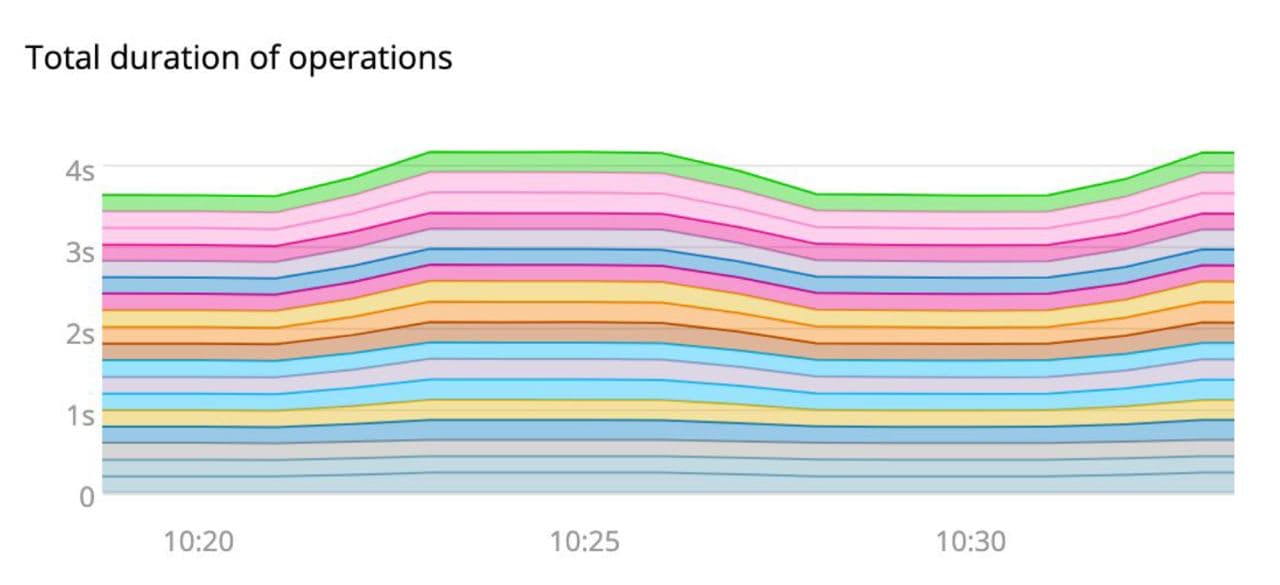
영역 차트는 '합산의 일부'에 적합합니다.
영역 차트는 데이터 분석 결과의 수치를 도형의 넓이로 표현한 것인데요. 시간의 흐름에 따라 데이터의 변화를 보기에 적합합니다. 여기 총 대기시간이 4초 정도 되는 차트에서 시간의 흐름에 따라 3초 반에서 4초 정도로 오르락내리락하면서 진행이 되는데요. 서로 선을 그으면 영역이 생기기 때문에 누적 영역 차트로만 사용을 해야 하죠. 하지만 어떤 것들이 이 누적에 영향을 주고, 어떤 부분들이 오르락 내리락하는 것에 영향을 줄까요? 우리는 모두 해답을 찾기 어렵습니다.
📍가끔 영역보다 나은 것 (Sometimes Better Than Area)
- 합계를 한 줄로 표시 (Show sum as single line)
- 이상치를 위한 항목별 분리 (Separate per-item unstaked line for outliers)
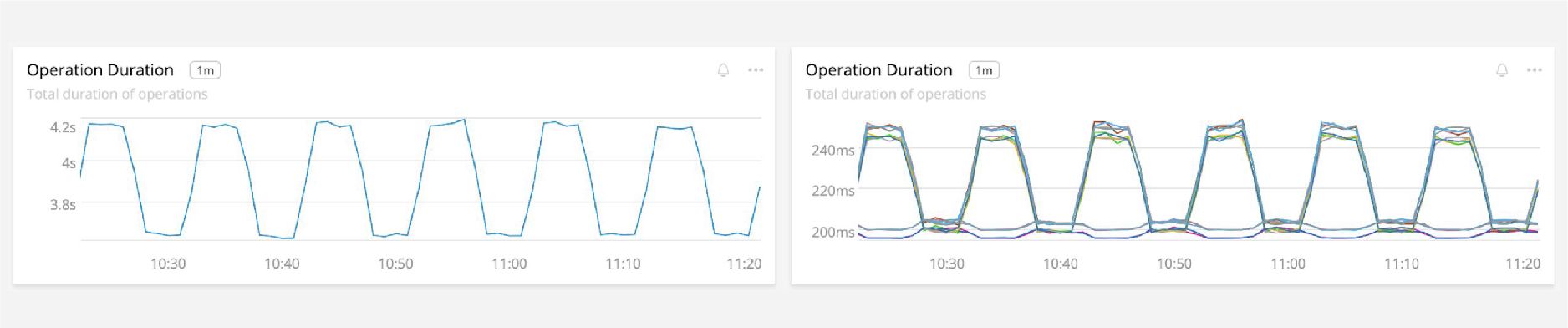
여기 총합을 선 차트로 표현한 그래프를 살펴보죠. 총합계만 표시한 다음 누적되지 않은 각 개별 구성을 따로 표현할 수 있죠. 우리는 이 그래프를 보고 주기성을 가진 집단과 그렇지 않은 집단이 있음을 알 수 있습니다. 이렇듯 Cory Watson은 때로는 모든 것을 하나의 차트에 표현하지 않는 게 정답이라고 말합니다.
💡막대 (Bars)
- 집계에 주의 (Beware aggregation)
- 몇 가지 값 비교에 최적 (Best for comparisons of a few values)
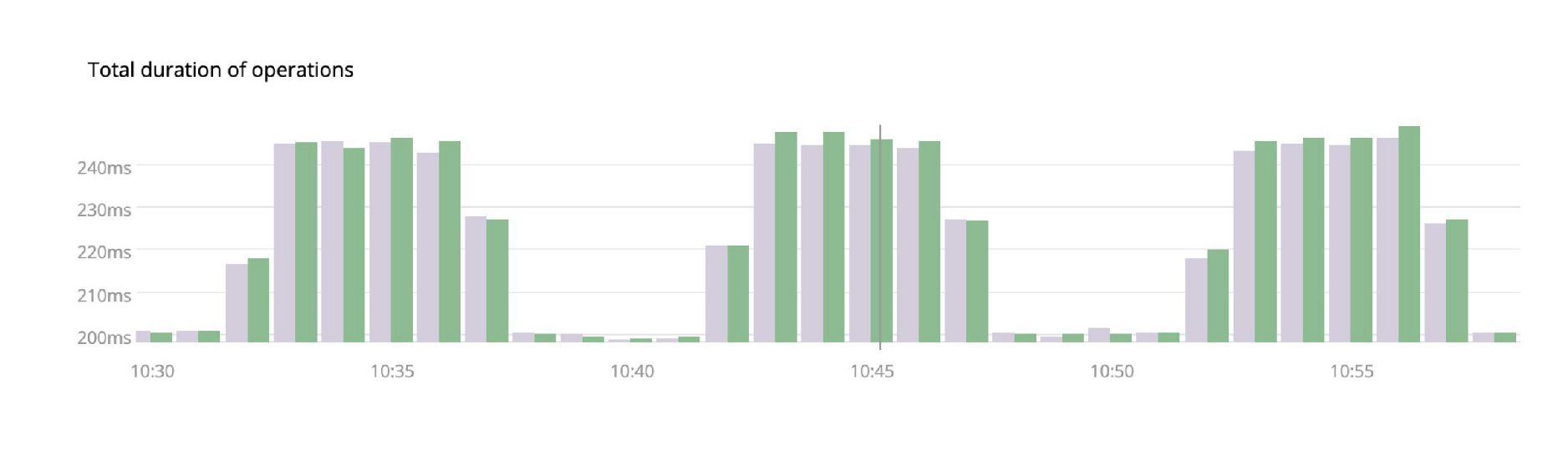
막대그래프는 데이터를 시각화할 수 있는 가장 일반적인 방법이면서 소규모 비교를 위한 최적의 방법입니다. 막대그래프는 다른 데이터를 다른 값의 차이로써 분석해야 하는데요. 비교하는 그룹 막대가 많아질수록 즉, 너무 많은 비교 대상이 생기게 되면 사람의 뇌는 자연스럽게 그룹핑을 해버리는 경향이 있습니다. 이것은 원래 차트가 주어야 하는 정보가 아닌 다른 정보를 주게 되죠.
다시 말하지만, 정확도가 가장 높은 것은 '위치'입니다.
여기서, Cory Watson이 강조한 이 부분을 다시 한번 기억해야 합니다. 우리는 그림에서 꼭대기의 두 값이 약간 다르다는 것을 매우 쉽게 비교할 수 있죠. 하지만 그룹 막대 차트에 4~5개의 막대를 추가하면 어떻게 될까요? 아마, 차이를 느끼기 어려울 것입니다. 그리고 이것은 비교 대상이 많을수록 더 그럴 것입니다. 즉, 몇 가지 비교 대상을 주면 그 차이점에 집중하지만, 너무 많은 비교 대상을 주면 차이를 느끼기 어려워지죠. 그렇기 때문에 막대그래프는 몇 가지 값을 비교하는 데 최적이라 말합니다.
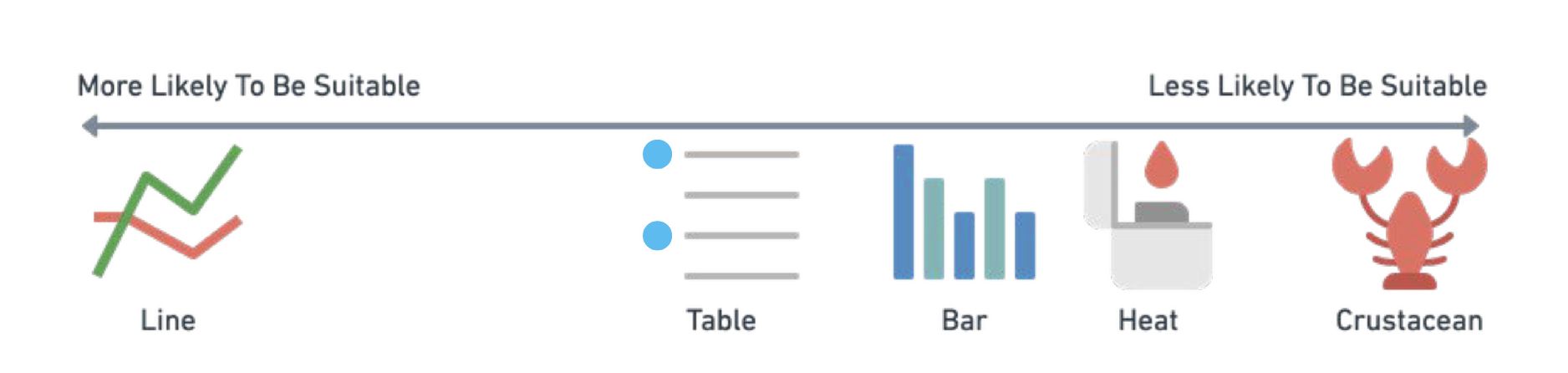
요약: 시각화의 선택 Visualization Choices
- 단일 값을 위한 테이블 사용 (Use table for single values)
- 1보다 작거나, 소수를 위한 선 (Use lines for 1 > x < a few)
- 선 차트의 사용은 진지하게 (Seriously, use line charts)
- 많은 선을 위한 히트맵 (Heatmaps for lots of lines)
- 소규모의 비교를 위한 막대 (Bars for small comparisons)
Cory Watson이 강의에서 강조하는 것은 '효과적인 정보 전달을 위해 시각화 방법을 사용할 수 있다.'라는 것입니다. 물론 목적에 맞게 사용해야 한다는 점도 같이 강조하며, 효과적인 시각화 대시보드를 만드는 방법에 대해 이야기합니다.
먼저 우리는 사용자가 시각화를 이해했는지 확인을 해야 합니다. 대시보드 운영자, 개발자, 사용자, 심지어 리더십을 가진 사용자조차 대시보드를 이해하지 못하는 경우가 많이 있죠. 물론 예쁘고 보기 좋은 대시보드는 보는 사람에게 즐거움을 주지만, 대시보드의 목적을 잃어서는 안됩니다. 사용자가 그것을 이해하고 다음 행동으로 이어질 수 있는가를 명심해야 합니다.
다음 시간에는 이번 시간에 이어 훌륭한 대시보드로 개선하기 위해 맥락에는 어떤 부분이 포함되는지, 대시보드를 되살리는 방법에 대해 알아보겠습니다.
이어지는 다음 편은 직관적인 대시보드 설계하기의 마지막 편입니다. 마지막까지 많이 기대해 주세요 😊
- 직관적인 대시보드 설계하기 #3 - 맥락
IMQA와 관련하여 궁금하신 사항은 언제든 아래 연락처로 문의해 주시면 상세히 안내해 드리겠습니다. 이미지를 클릭하시면 1:1 채팅 창으로 이동합니다.
- 02-6395-7730
- support@imqa.io


![[210701] SDK 업데이트 소식](/content/images/2022/03/IMQA_ReleaseNote-2.jpg)